 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Spatial-Temporal Representation via Star Graph for mmWave Radar-based Human Activity Recognition
Dec 12, 2025
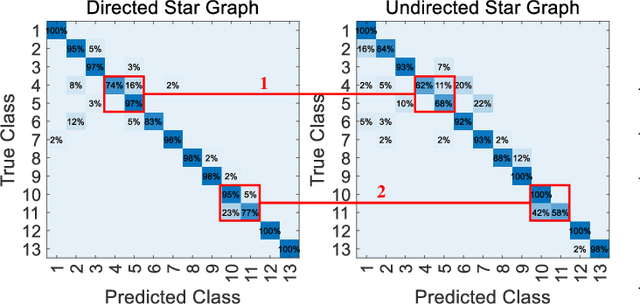


Human activity recognition (HAR) requires extracting accurate spatial-temporal features with human movements. A mmWave radar point cloud-based HAR system suffers from sparsity and variable-size problems due to the physical features of the mmWave signal. Existing works usually borrow the preprocessing algorithms for the vision-based systems with dense point clouds, which may not be optimal for mmWave radar systems. In this work, we proposed a graph representation with a discrete dynamic graph neural network (DDGNN) to explore the spatial-temporal representation of human movement-related features. Specifically, we designed a star graph to describe the high-dimensional relative relationship between a manually added static center point and the dynamic mmWave radar points in the same and consecutive frames. We then adopted DDGNN to learn the features residing in the star graph with variable sizes. Experimental results demonstrated that our approach outperformed other baseline methods using real-world HAR datasets. Our system achieved an overall classification accuracy of 94.27\%, which gets the near-optimal performance with a vision-based skeleton data accuracy of 97.25\%. We also conducted an inference test on Raspberry Pi~4 to demonstrate its effectiveness on resource-constraint platforms. \sh{ We provided a comprehensive ablation study for variable DDGNN structures to validate our model design. Our system also outperformed three recent radar-specific methods without requiring resampling or frame aggregators.
mmSpyVR: Exploiting mmWave Radar for Penetrating Obstacles to Uncover Privacy Vulnerability of Virtual Reality
Nov 15, 2024



Virtual reality (VR), while enhancing user experiences, introduces significant privacy risks. This paper reveals a novel vulnerability in VR systems that allows attackers to capture VR privacy through obstacles utilizing millimeter-wave (mmWave) signals without physical intrusion and virtual connection with the VR devices. We propose mmSpyVR, a novel attack on VR user's privacy via mmWave radar. The mmSpyVR framework encompasses two main parts: (i) A transfer learning-based feature extraction model to achieve VR feature extraction from mmWave signal. (ii) An attention-based VR privacy spying module to spy VR privacy information from the extracted feature. The mmSpyVR demonstrates the capability to extract critical VR privacy from the mmWave signals that have penetrated through obstacles. We evaluate mmSpyVR through IRB-approved user studies. Across 22 participants engaged in four experimental scenes utilizing VR devices from three different manufacturers, our system achieves an application recognition accuracy of 98.5\% and keystroke recognition accuracy of 92.6\%. This newly discovered vulnerability has implications across various domains, such as cybersecurity, privacy protection, and VR technology development. We also engage with VR manufacturer Meta to discuss and explore potential mitigation strategies. Data and code are publicly available for scrutiny and research at https://github.com/luoyumei1-a/mmSpyVR/
ESP-PCT: Enhanced VR Semantic Performance through Efficient Compression of Temporal and Spatial Redundancies in Point Cloud Transformers
Sep 02, 2024



Semantic recognition is pivotal in virtual reality (VR) applications, enabling immersive and interactive experiences. A promising approach is utilizing millimeter-wave (mmWave) signals to generate point clouds. However, the high computational and memory demands of current mmWave point cloud models hinder their efficiency and reliability. To address this limitation, our paper introduces ESP-PCT, a novel Enhanced Semantic Performance Point Cloud Transformer with a two-stage semantic recognition framework tailored for VR applications. ESP-PCT takes advantage of the accuracy of sensory point cloud data and optimizes the semantic recognition process, where the localization and focus stages are trained jointly in an end-to-end manner. We evaluate ESP-PCT on various VR semantic recognition conditions, demonstrating substantial enhancements in recognition efficiency. Notably, ESP-PCT achieves a remarkable accuracy of 93.2% while reducing the computational requirements (FLOPs) by 76.9% and memory usage by 78.2% compared to the existing Point Transformer model simultaneously. These underscore ESP-PCT's potential in VR semantic recognition by achieving high accuracy and reducing redundancy. The code and data of this project are available at \url{https://github.com/lymei-SEU/ESP-PCT}.
Human Semantic Segmentation using Millimeter-Wave Radar Sparse Point Clouds
Apr 28, 2023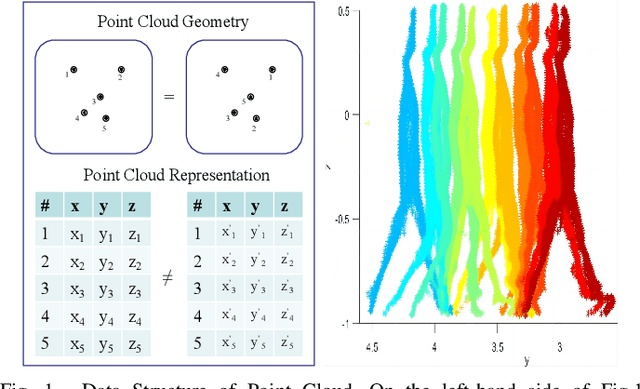
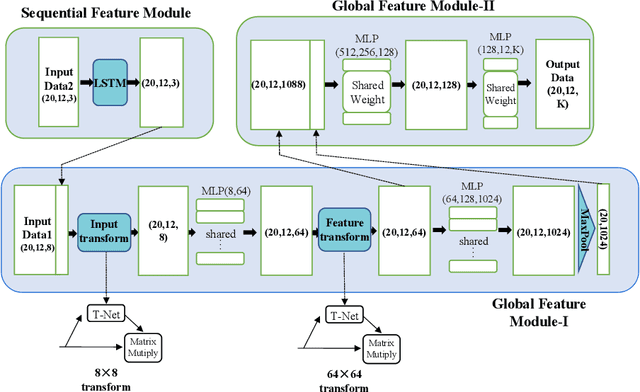
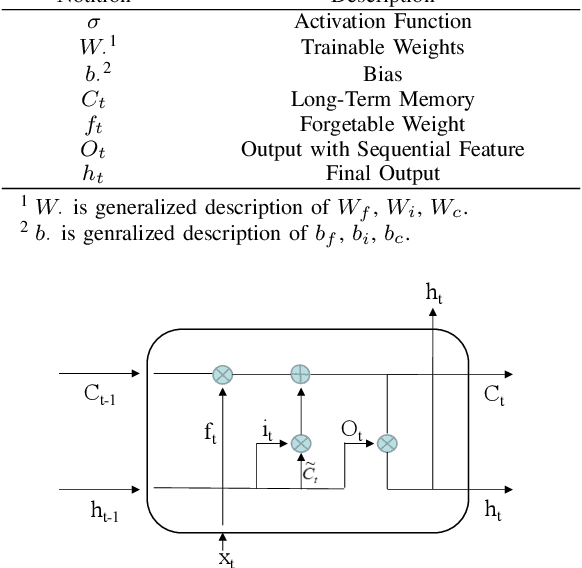
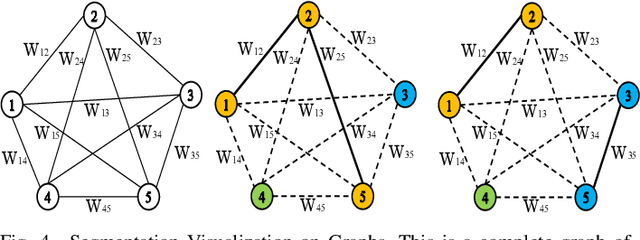
This paper presents a framework for semantic segmentation on sparse sequential point clouds of millimeter-wave radar. Compared with cameras and lidars, millimeter-wave radars have the advantage of not revealing privacy, having a strong anti-interference ability, and having long detection distance. The sparsity and capturing temporal-topological features of mmWave data is still a problem. However, the issue of capturing the temporal-topological coupling features under the human semantic segmentation task prevents previous advanced segmentation methods (e.g PointNet, PointCNN, Point Transformer) from being well utilized in practical scenarios. To address the challenge caused by the sparsity and temporal-topological feature of the data, we (i) introduce graph structure and topological features to the point cloud, (ii) propose a semantic segmentation framework including a global feature-extracting module and a sequential feature-extracting module. In addition, we design an efficient and more fitting loss function for a better training process and segmentation results based on graph clustering. Experimentally, we deploy representative semantic segmentation algorithms (Transformer, GCNN, etc.) on a custom dataset. Experimental results indicate that our model achieves mean accuracy on the custom dataset by $\mathbf{82.31}\%$ and outperforms the state-of-the-art algorithms. Moreover, to validate the model's robustness, we deploy our model on the well-known S3DIS dataset. On the S3DIS dataset, our model achieves mean accuracy by $\mathbf{92.6}\%$, outperforming baseline algorithms.