 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Drag: How Errors in the Context Affect LLM Reasoning
Feb 04, 2026Central to many self-improvement pipelines for large language models (LLMs) is the assumption that models can improve by reflecting on past mistakes. We study a phenomenon termed contextual drag: the presence of failed attempts in the context biases subsequent generations toward structurally similar errors. Across evaluations of 11 proprietary and open-weight models on 8 reasoning tasks, contextual drag induces 10-20% performance drops, and iterative self-refinement in models with severe contextual drag can collapse into self-deterioration. Structural analysis using tree edit distance reveals that subsequent reasoning trajectories inherit structurally similar error patterns from the context. We demonstrate that neither external feedback nor successful self-verification suffices to eliminate this effect. While mitigation strategies such as fallback-behavior fine-tuning and context denoising yield partial improvements, they fail to fully restore baseline performance, positioning contextual drag as a persistent failure mode in current reasoning architectures.
PCDCNet: A Surrogate Model for Air Quality Forecasting with Physical-Chemical Dynamics and Constraints
May 26, 2025Air quality forecasting (AQF) is critical for public health and environmental management, yet remains challenging due to the complex interplay of emissions, meteorology, and chemical transformations. Traditional numerical models, such as CMAQ and WRF-Chem, provide physically grounded simulations but are computationally expensive and rely on uncertain emission inventories. Deep learning models, while computationally efficient, often struggle with generalization due to their lack of physical constraints. To bridge this gap, we propose PCDCNet, a surrogate model that integrates numerical modeling principles with deep learning. PCDCNet explicitly incorporates emissions, meteorological influences, and domain-informed constraints to model pollutant formation, transport, and dissipation. By combining graph-based spatial transport modeling, recurrent structures for temporal accumulation, and representation enhancement for local interactions, PCDCNet achieves state-of-the-art (SOTA) performance in 72-hour station-level PM2.5 and O3 forecasting while significantly reducing computational costs. Furthermore, our model is deployed in an online platform, providing free, real-time air quality forecasts, demonstrating its scalability and societal impact. By aligning deep learning with physical consistency, PCDCNet offers a practical and interpretable solution for AQF, enabling informed decision-making for both personal and regulatory applications.
FoCTTA: Low-Memory Continual Test-Time Adaptation with Focus
Feb 28, 2025Continual adaptation to domain shifts at test time (CTTA) is crucial for enhancing the intelligence of deep learning enabled IoT applications. However, prevailing TTA methods, which typically update all batch normalization (BN) layers, exhibit two memory inefficiencies. First, the reliance on BN layers for adaptation necessitates large batch sizes, leading to high memory usage. Second, updating all BN layers requires storing the activations of all BN layers for backpropagation, exacerbating the memory demand. Both factors lead to substantial memory costs, making existing solutions impractical for IoT devices. In this paper, we present FoCTTA, a low-memory CTTA strategy. The key is to automatically identify and adapt a few drift-sensitive representation layers, rather than blindly update all BN layers. The shift from BN to representation layers eliminates the need for large batch sizes. Also, by updating adaptation-critical layers only, FoCTTA avoids storing excessive activations. This focused adaptation approach ensures that FoCTTA is not only memory-efficient but also maintains effective adaptation. Evaluations show that FoCTTA improves the adaptation accuracy over the state-of-the-arts by 4.5%, 4.9%, and 14.8% on CIFAR10-C, CIFAR100-C, and ImageNet-C under the same memory constraints. Across various batch sizes, FoCTTA reduces the memory usage by 3-fold on average, while improving the accuracy by 8.1%, 3.6%, and 0.2%, respectively, on the three datasets.
FocusDD: Real-World Scene Infusion for Robust Dataset Distillation
Jan 11, 2025



Dataset distillation has emerged as a strategy to compress real-world datasets for efficient training. However, it struggles with large-scale and high-resolution datasets, limiting its practicality. This paper introduces a novel resolution-independent dataset distillation method Focus ed Dataset Distillation (FocusDD), which achieves diversity and realism in distilled data by identifying key information patches, thereby ensuring the generalization capability of the distilled dataset across different network architectures. Specifically, FocusDD leverages a pre-trained Vision Transformer (ViT) to extract key image patches, which are then synthesized into a single distilled image. These distilled images, which capture multiple targets, are suitable not only for classification tasks but also for dense tasks such as object detection. To further improve the generalization of the distilled dataset, each synthesized image is augmented with a downsampled view of the original image. Experimental results on the ImageNet-1K dataset demonstrate that, with 100 images per class (IPC), ResNet50 and MobileNet-v2 achieve validation accuracies of 71.0% and 62.6%, respectively, outperforming state-of-the-art methods by 2.8% and 4.7%. Notably, FocusDD is the first method to use distilled datasets for object detection tasks. On the COCO2017 dataset, with an IPC of 50, YOLOv11n and YOLOv11s achieve 24.4% and 32.1% mAP, respectively, further validating the effectiveness of our approach.
Interpretable deep learning illuminates multiple structures fluorescence imaging: a path toward trustworthy artificial intelligence in microscopy
Jan 09, 2025Live-cell imaging of multiple subcellular structures is essential for understanding subcellular dynamics. However, the conventional multi-color sequential fluorescence microscopy suffers from significant imaging delays and limited number of subcellular structure separate labeling, resulting in substantial limitations for real-time live-cell research applications. Here, we present the Adaptive Explainable Multi-Structure Network (AEMS-Net), a deep-learning framework that enables simultaneous prediction of two subcellular structures from a single image. The model normalizes staining intensity and prioritizes critical image features by integrating attention mechanisms and brightness adaptation layers. Leveraging the Kolmogorov-Arnold representation theorem, our model decomposes learned features into interpretable univariate functions, enhancing the explainability of complex subcellular morphologies. We demonstrate that AEMS-Net allows real-time recording of interactions between mitochondria and microtubules, requiring only half the conventional sequential-channel imaging procedures. Notably, this approach achieves over 30% improvement in imaging quality compared to traditional deep learning methods, establishing a new paradigm for long-term, interpretable live-cell imaging that advances the ability to explore subcellular dynamics.
Generalizing from SIMPLE to HARD Visual Reasoning: Can We Mitigate Modality Imbalance in VLMs?
Jan 05, 2025



While Vision Language Models (VLMs) are impressive in tasks such as visual question answering (VQA) and image captioning, their ability to apply multi-step reasoning to images has lagged, giving rise to perceptions of modality imbalance or brittleness. Towards systematic study of such issues, we introduce a synthetic framework for assessing the ability of VLMs to perform algorithmic visual reasoning (AVR), comprising three tasks: Table Readout, Grid Navigation, and Visual Analogy. Each has two levels of difficulty, SIMPLE and HARD, and even the SIMPLE versions are difficult for frontier VLMs. We seek strategies for training on the SIMPLE version of the tasks that improve performance on the corresponding HARD task, i.e., S2H generalization. This synthetic framework, where each task also has a text-only version, allows a quantification of the modality imbalance, and how it is impacted by training strategy. Ablations highlight the importance of explicit image-to-text conversion in promoting S2H generalization when using auto-regressive training. We also report results of mechanistic study of this phenomenon, including a measure of gradient alignment that seems to identify training strategies that promote better S2H generalization.
ESP-PCT: Enhanced VR Semantic Performance through Efficient Compression of Temporal and Spatial Redundancies in Point Cloud Transformers
Sep 02, 2024



Semantic recognition is pivotal in virtual reality (VR) applications, enabling immersive and interactive experiences. A promising approach is utilizing millimeter-wave (mmWave) signals to generate point clouds. However, the high computational and memory demands of current mmWave point cloud models hinder their efficiency and reliability. To address this limitation, our paper introduces ESP-PCT, a novel Enhanced Semantic Performance Point Cloud Transformer with a two-stage semantic recognition framework tailored for VR applications. ESP-PCT takes advantage of the accuracy of sensory point cloud data and optimizes the semantic recognition process, where the localization and focus stages are trained jointly in an end-to-end manner. We evaluate ESP-PCT on various VR semantic recognition conditions, demonstrating substantial enhancements in recognition efficiency. Notably, ESP-PCT achieves a remarkable accuracy of 93.2% while reducing the computational requirements (FLOPs) by 76.9% and memory usage by 78.2% compared to the existing Point Transformer model simultaneously. These underscore ESP-PCT's potential in VR semantic recognition by achieving high accuracy and reducing redundancy. The code and data of this project are available at \url{https://github.com/lymei-SEU/ESP-PCT}.
MultiZoo & MultiBench: A Standardized Toolkit for Multimodal Deep Learning
Jun 28, 2023

Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiZoo, a public toolkit consisting of standardized implementations of > 20 core multimodal algorithms and MultiBench, a large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. Together, these provide an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, we offer a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench paves the way towards a better understanding of the capabilities and limitations of multimodal models, while ensuring ease of use, accessibility, and reproducibility. Our toolkits are publicly available, will be regularly updated, and welcome inputs from the community.
Multimodal Learning Without Labeled Multimodal Data: Guarantees and Applications
Jun 07, 2023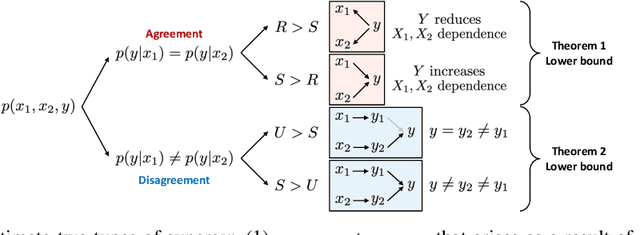
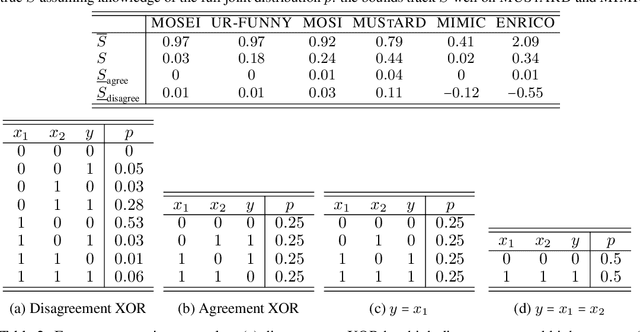
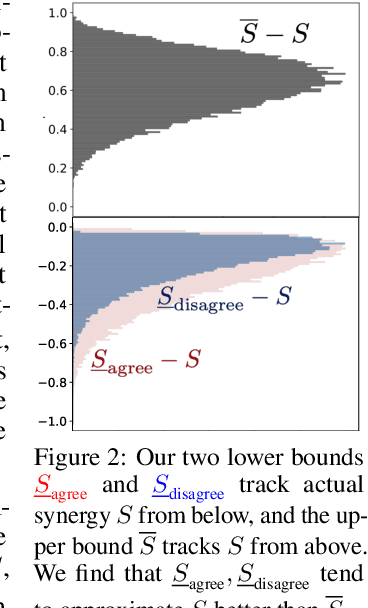
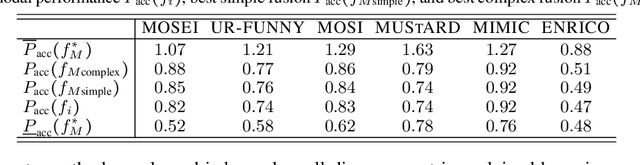
In many machine learning systems that jointly learn from multiple modalities, a core research question is to understand the nature of multimodal interactions: the emergence of new task-relevant information during learning from both modalities that was not present in either alone. We study this challenge of interaction quantification in a semi-supervised setting with only labeled unimodal data and naturally co-occurring multimodal data (e.g., unlabeled images and captions, video and corresponding audio) but when labeling them is time-consuming. Using a precise information-theoretic definition of interactions, our key contributions are the derivations of lower and upper bounds to quantify the amount of multimodal interactions in this semi-supervised setting. We propose two lower bounds based on the amount of shared information between modalities and the disagreement between separately trained unimodal classifiers, and derive an upper bound through connections to approximate algorithms for min-entropy couplings. We validate these estimated bounds and show how they accurately track true interactions. Finally, two semi-supervised multimodal applications are explored based on these theoretical results: (1) analyzing the relationship between multimodal performance and estimated interactions, and (2) self-supervised learning that embraces disagreement between modalities beyond agreement as is typically done.
Multimodal Fusion Interactions: A Study of Human and Automatic Quantification
Jun 07, 2023Multimodal fusion of multiple heterogeneous and interconnected signals is a fundamental challenge in almost all multimodal problems and applications. In order to perform multimodal fusion, we need to understand the types of interactions that modalities can exhibit: how each modality individually provides information useful for a task and how this information changes in the presence of other modalities. In this paper, we perform a comparative study of how human annotators can be leveraged to annotate two categorizations of multimodal interactions: (1) partial labels, where different randomly assigned annotators annotate the label given the first, second, and both modalities, and (2) counterfactual labels, where the same annotator is tasked to annotate the label given the first modality before giving them the second modality and asking them to explicitly reason about how their answer changes, before proposing an alternative taxonomy based on (3) information decomposition, where annotators annotate the degrees of redundancy: the extent to which modalities individually and together give the same predictions on the task, uniqueness: the extent to which one modality enables a task prediction that the other does not, and synergy: the extent to which only both modalities enable one to make a prediction about the task that one would not otherwise make using either modality individually. Through extensive experiments and annotations, we highlight several opportunities and limitations of each approach and propose a method to automatically convert annotations of partial and counterfactual labels to information decomposition, yielding an accurate and efficient method for quantifying interactions in multimodal datasets.