 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowCast-ODE: Continuous Hourly Weather Forecasting with Dynamic Flow Matching and ODE Integration
Sep 18, 2025Accurate hourly weather forecasting is critical for numerous applications. Recent deep learning models have demonstrated strong capability on 6-hour intervals, yet achieving accurate and stable hourly predictions remains a critical challenge. This is primarily due to the rapid accumulation of errors in autoregressive rollouts and temporal discontinuities within the ERA5 data's 12-hour assimilation cycle. To address these issues, we propose FlowCast-ODE, a framework that models atmospheric state evolution as a continuous flow. FlowCast-ODE learns the conditional flow path directly from the previous state, an approach that aligns more naturally with physical dynamic systems and enables efficient computation. A coarse-to-fine strategy is introduced to train the model on 6-hour data using dynamic flow matching and then refined on hourly data that incorporates an Ordinary Differential Equation (ODE) solver to achieve temporally coherent forecasts. In addition, a lightweight low-rank AdaLN-Zero modulation mechanism is proposed and reduces model size by 15% without compromising accuracy. Experiments demonstrate that FlowCast-ODE outperforms strong baselines, yielding lower root mean square error (RMSE) and better energy conservation, which reduces blurring and preserves more fine-scale spatial details. It also shows comparable performance to the state-of-the-art model in forecasting extreme events like typhoons. Furthermore, the model alleviates temporal discontinuities associated with assimilation cycle transitions.
PCDCNet: A Surrogate Model for Air Quality Forecasting with Physical-Chemical Dynamics and Constraints
May 26, 2025Air quality forecasting (AQF) is critical for public health and environmental management, yet remains challenging due to the complex interplay of emissions, meteorology, and chemical transformations. Traditional numerical models, such as CMAQ and WRF-Chem, provide physically grounded simulations but are computationally expensive and rely on uncertain emission inventories. Deep learning models, while computationally efficient, often struggle with generalization due to their lack of physical constraints. To bridge this gap, we propose PCDCNet, a surrogate model that integrates numerical modeling principles with deep learning. PCDCNet explicitly incorporates emissions, meteorological influences, and domain-informed constraints to model pollutant formation, transport, and dissipation. By combining graph-based spatial transport modeling, recurrent structures for temporal accumulation, and representation enhancement for local interactions, PCDCNet achieves state-of-the-art (SOTA) performance in 72-hour station-level PM2.5 and O3 forecasting while significantly reducing computational costs. Furthermore, our model is deployed in an online platform, providing free, real-time air quality forecasts, demonstrating its scalability and societal impact. By aligning deep learning with physical consistency, PCDCNet offers a practical and interpretable solution for AQF, enabling informed decision-making for both personal and regulatory applications.
CNCast: Leveraging 3D Swin Transformer and DiT for Enhanced Regional Weather Forecasting
Mar 16, 2025This study introduces a cutting-edge regional weather forecasting model based on the SwinTransformer 3D architecture. This model is specifically designed to deliver precise hourly weather predictions ranging from 1 hour to 5 days, significantly improving the reliability and practicality of short-term weather forecasts. Our model has demonstrated generally superior performance when compared to Pangu, a well-established global model. The evaluation indicates that our model excels in predicting most weather variables, highlighting its potential as a more effective alternative in the field of limited area modeling. A noteworthy feature of this model is the integration of enhanced boundary conditions, inspired by traditional numerical weather prediction (NWP) techniques. This integration has substantially improved the model's predictive accuracy. Additionally, the model includes an innovative approach for diagnosing hourly total precipitation at a high spatial resolution of approximately 5 kilometers. This is achieved through a latent diffusion model, offering an alternative method for generating high-resolution precipitation data.
Skillful High-Resolution Ensemble Precipitation Forecasting with an Integrated Deep Learning Framework
Jan 06, 2025

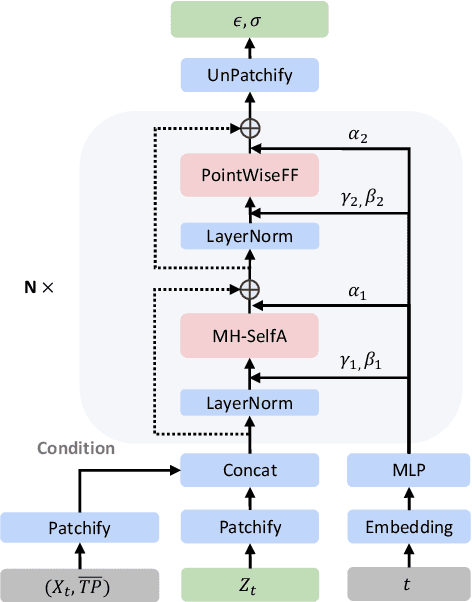
High-resolution precipitation forecasts are crucial for providing accurate weather prediction and supporting effective responses to extreme weather events. Traditional numerical models struggle with stochastic subgrid-scale processes, while recent deep learning models often produce blurry results. To address these challenges, we propose a physics-inspired deep learning framework for high-resolution (0.05\textdegree{} $\times$ 0.05\textdegree{}) ensemble precipitation forecasting. Trained on ERA5 and CMPA high-resolution precipitation datasets, the framework integrates deterministic and probabilistic components. The deterministic model, based on a 3D SwinTransformer, captures average precipitation at mesoscale resolution and incorporates strategies to enhance performance, particularly for moderate to heavy rainfall. The probabilistic model employs conditional diffusion in latent space to account for uncertainties in residual precipitation at convective scales. During inference, ensemble members are generated by repeatedly sampling latent variables, enabling the model to represent precipitation uncertainty. Our model significantly enhances spatial resolution and forecast accuracy. Rank histogram shows that the ensemble system is reliable and unbiased. In a case study of heavy precipitation in southern China, the model outputs align more closely with observed precipitation distributions than ERA5, demonstrating superior capability in capturing extreme precipitation events. Additionally, 5-day real-time forecasts show good performance in terms of CSI scores.
Improving Transformers with Dynamically Composable Multi-Head Attention
May 14, 2024



Multi-Head Attention (MHA) is a key component of Transformer. In MHA, attention heads work independently, causing problems such as low-rank bottleneck of attention score matrices and head redundancy. We propose Dynamically Composable Multi-Head Attention (DCMHA), a parameter and computation efficient attention architecture that tackles the shortcomings of MHA and increases the expressive power of the model by dynamically composing attention heads. At the core of DCMHA is a $\it{Compose}$ function that transforms the attention score and weight matrices in an input-dependent way. DCMHA can be used as a drop-in replacement of MHA in any transformer architecture to obtain the corresponding DCFormer. DCFormer significantly outperforms Transformer on different architectures and model scales in language modeling, matching the performance of models with ~1.7x-2.0x compute. For example, DCPythia-6.9B outperforms open source Pythia-12B on both pretraining perplexity and downstream task evaluation. The code and models are available at https://github.com/Caiyun-AI/DCFormer.
Improving the Universality and Learnability of Neural Programmer-Interpreters with Combinator Abstraction
Feb 08, 2018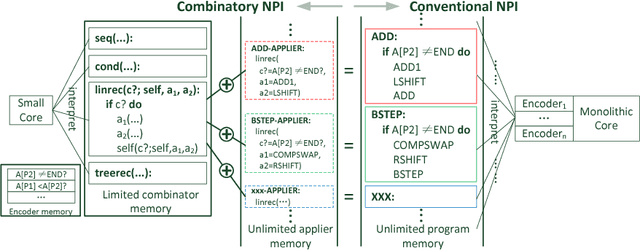


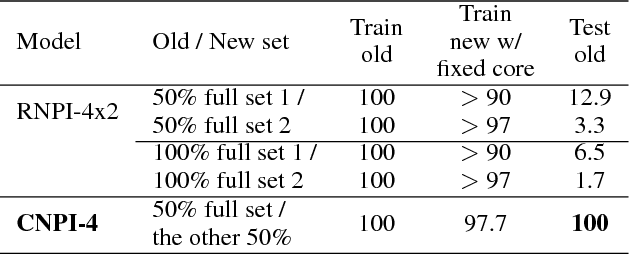
To overcome the limitations of Neural Programmer-Interpreters (NPI) in its universality and learnability, we propose the incorporation of combinator abstraction into neural programing and a new NPI architecture to support this abstraction, which we call Combinatory Neural Programmer-Interpreter (CNPI). Combinator abstraction dramatically reduces the number and complexity of programs that need to be interpreted by the core controller of CNPI, while still allowing the CNPI to represent and interpret arbitrary complex programs by the collaboration of the core with the other components. We propose a small set of four combinators to capture the most pervasive programming patterns. Due to the finiteness and simplicity of this combinator set and the offloading of some burden of interpretation from the core, we are able construct a CNPI that is universal with respect to the set of all combinatorizable programs, which is adequate for solving most algorithmic tasks. Moreover, besides supervised training on execution traces, CNPI can be trained by policy gradient reinforcement learning with appropriately designed curricula.