 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAIL: Post-hoc Compensation by Linear Reconstruction for Compressed Networks
Mar 02, 2026Structured deep model compression methods are hardware-friendly and substantially reduce memory and inference costs. However, under aggressive compression, the resulting accuracy degradation often necessitates post-compression finetuning, which can be impractical due to missing labeled data or high training cost. We propose post-hoc blockwise compensation, called GRAIL, a simple zero-finetuning step applied after model compression that restores each block's input-output behavior using a small calibration set. The method summarizes hidden activations via a Gram matrix and applies ridge regression to linearly reconstruct the original hidden representation from the reduced one. The resulting reconstruction map is absorbed into the downstream projection weights, while the upstream layer is compressed. The approach is selector-agnostic (Magnitude, Wanda, Gram-based selection, or folding), data-aware (requiring only a few forward passes without gradients or labels), and recovers classic pruning or folding when the Gram matrix is near identity, indicating weak inter-channel correlations. Across ResNets, ViTs, and decoder-only LLMs, GRAIL consistently improves accuracy or perplexity over data-free and data-aware pruning or folding baselines in practical compression regimes, with manageable overhead and no backpropagation. The code is available at https://github.com/TWWinde/GRAIL_Compensation.
PCDCNet: A Surrogate Model for Air Quality Forecasting with Physical-Chemical Dynamics and Constraints
May 26, 2025Air quality forecasting (AQF) is critical for public health and environmental management, yet remains challenging due to the complex interplay of emissions, meteorology, and chemical transformations. Traditional numerical models, such as CMAQ and WRF-Chem, provide physically grounded simulations but are computationally expensive and rely on uncertain emission inventories. Deep learning models, while computationally efficient, often struggle with generalization due to their lack of physical constraints. To bridge this gap, we propose PCDCNet, a surrogate model that integrates numerical modeling principles with deep learning. PCDCNet explicitly incorporates emissions, meteorological influences, and domain-informed constraints to model pollutant formation, transport, and dissipation. By combining graph-based spatial transport modeling, recurrent structures for temporal accumulation, and representation enhancement for local interactions, PCDCNet achieves state-of-the-art (SOTA) performance in 72-hour station-level PM2.5 and O3 forecasting while significantly reducing computational costs. Furthermore, our model is deployed in an online platform, providing free, real-time air quality forecasts, demonstrating its scalability and societal impact. By aligning deep learning with physical consistency, PCDCNet offers a practical and interpretable solution for AQF, enabling informed decision-making for both personal and regulatory applications.
FocusDD: Real-World Scene Infusion for Robust Dataset Distillation
Jan 11, 2025



Dataset distillation has emerged as a strategy to compress real-world datasets for efficient training. However, it struggles with large-scale and high-resolution datasets, limiting its practicality. This paper introduces a novel resolution-independent dataset distillation method Focus ed Dataset Distillation (FocusDD), which achieves diversity and realism in distilled data by identifying key information patches, thereby ensuring the generalization capability of the distilled dataset across different network architectures. Specifically, FocusDD leverages a pre-trained Vision Transformer (ViT) to extract key image patches, which are then synthesized into a single distilled image. These distilled images, which capture multiple targets, are suitable not only for classification tasks but also for dense tasks such as object detection. To further improve the generalization of the distilled dataset, each synthesized image is augmented with a downsampled view of the original image. Experimental results on the ImageNet-1K dataset demonstrate that, with 100 images per class (IPC), ResNet50 and MobileNet-v2 achieve validation accuracies of 71.0% and 62.6%, respectively, outperforming state-of-the-art methods by 2.8% and 4.7%. Notably, FocusDD is the first method to use distilled datasets for object detection tasks. On the COCO2017 dataset, with an IPC of 50, YOLOv11n and YOLOv11s achieve 24.4% and 32.1% mAP, respectively, further validating the effectiveness of our approach.
Breaking the Illusion: Real-world Challenges for Adversarial Patches in Object Detection
Oct 23, 2024



Adversarial attacks pose a significant threat to the robustness and reliability of machine learning systems, particularly in computer vision applications. This study investigates the performance of adversarial patches for the YOLO object detection network in the physical world. Two attacks were tested: a patch designed to be placed anywhere within the scene - global patch, and another patch intended to partially overlap with specific object targeted for removal from detection - local patch. Various factors such as patch size, position, rotation, brightness, and hue were analyzed to understand their impact on the effectiveness of the adversarial patches. The results reveal a notable dependency on these parameters, highlighting the challenges in maintaining attack efficacy in real-world conditions. Learning to align digitally applied transformation parameters with those measured in the real world still results in up to a 64\% discrepancy in patch performance. These findings underscore the importance of understanding environmental influences on adversarial attacks, which can inform the development of more robust defenses for practical machine learning applications.
REDS: Resource-Efficient Deep Subnetworks for Dynamic Resource Constraints
Nov 22, 2023Deep models deployed on edge devices frequently encounter resource variability, which arises from fluctuating energy levels, timing constraints, or prioritization of other critical tasks within the system. State-of-the-art machine learning pipelines generate resource-agnostic models, not capable to adapt at runtime. In this work we introduce Resource-Efficient Deep Subnetworks (REDS) to tackle model adaptation to variable resources. In contrast to the state-of-the-art, REDS use structured sparsity constructively by exploiting permutation invariance of neurons, which allows for hardware-specific optimizations. Specifically, REDS achieve computational efficiency by (1) skipping sequential computational blocks identified by a novel iterative knapsack optimizer, and (2) leveraging simple math to re-arrange the order of operations in REDS computational graph to take advantage of the data cache. REDS support conventional deep networks frequently deployed on the edge and provide computational benefits even for small and simple networks. We evaluate REDS on six benchmark architectures trained on the Google Speech Commands, FMNIST and CIFAR10 datasets, and test on four off-the-shelf mobile and embedded hardware platforms. We provide a theoretical result and empirical evidence for REDS outstanding performance in terms of submodels' test set accuracy, and demonstrate an adaptation time in response to dynamic resource constraints of under 40$\mu$s, utilizing a 2-layer fully-connected network on Arduino Nano 33 BLE Sense.
Geometric Data Augmentations to Mitigate Distribution Shifts in Pollen Classification from Microscopic Images
Nov 18, 2023Distribution shifts are characterized by differences between the training and test data distributions. They can significantly reduce the accuracy of machine learning models deployed in real-world scenarios. This paper explores the distribution shift problem when classifying pollen grains from microscopic images collected in the wild with a low-cost camera sensor. We leverage the domain knowledge that geometric features are highly important for accurate pollen identification and introduce two novel geometric image augmentation techniques to significantly narrow the accuracy gap between the model performance on the train and test datasets. In particular, we show that Tenengrad and ImageToSketch filters are highly effective to balance the shape and texture information while leaving out unimportant details that may confuse the model. Extensive evaluations on various model architectures demonstrate a consistent improvement of the model generalization to field data of up to 14% achieved by the geometric augmentation techniques when compared to a wide range of standard image augmentations. The approach is validated through an ablation study using pollen hydration tests to recover the shape of dry pollen grains. The proposed geometric augmentations also receive the highest scores according to the affinity and diversity measures from the literature.
Representing Input Transformations by Low-Dimensional Parameter Subspaces
May 22, 2023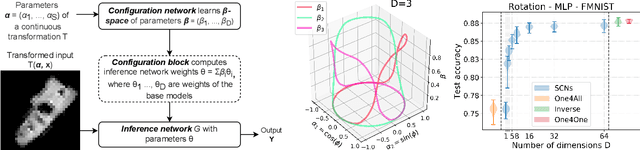
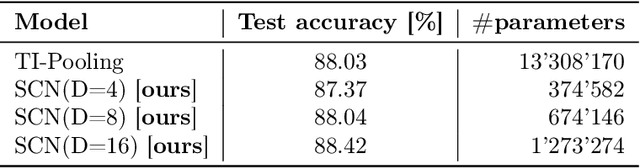
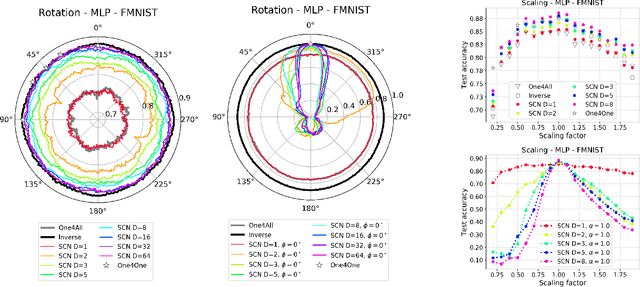
Deep models lack robustness to simple input transformations such as rotation, scaling, and translation, unless they feature a particular invariant architecture or undergo specific training, e.g., learning the desired robustness from data augmentations. Alternatively, input transformations can be treated as a domain shift problem, and solved by post-deployment model adaptation. Although a large number of methods deal with transformed inputs, the fundamental relation between input transformations and optimal model weights is unknown. In this paper, we put forward the configuration subspace hypothesis that model weights optimal for parameterized continuous transformations can reside in low-dimensional linear subspaces. We introduce subspace-configurable networks to learn these subspaces and observe their structure and surprisingly low dimensionality on all tested transformations, datasets and architectures from computer vision and audio signal processing domains. Our findings enable efficient model reconfiguration, especially when limited storage and computing resources are at stake.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
The Role of Pre-training Data in Transfer Learning
Mar 01, 2023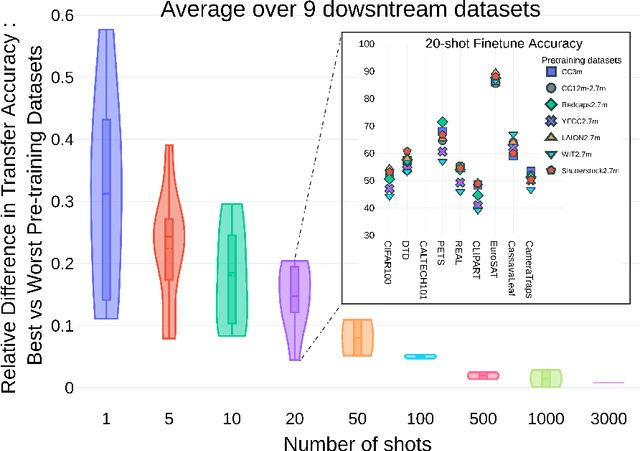
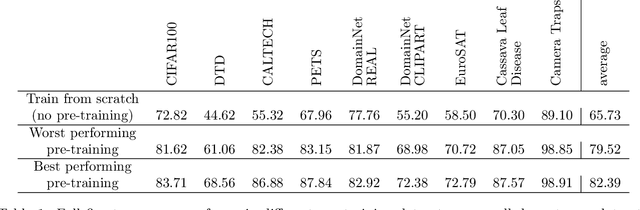
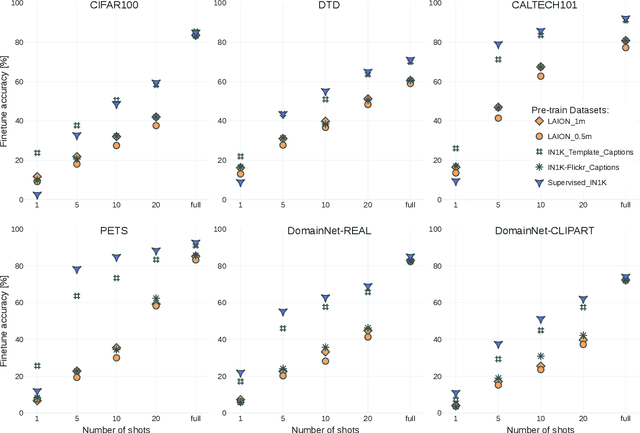

The transfer learning paradigm of model pre-training and subsequent fine-tuning produces high-accuracy models. While most studies recommend scaling the pre-training size to benefit most from transfer learning, a question remains: what data and method should be used for pre-training? We investigate the impact of pre-training data distribution on the few-shot and full fine-tuning performance using 3 pre-training methods (supervised, contrastive language-image and image-image), 7 pre-training datasets, and 9 downstream datasets. Through extensive controlled experiments, we find that the choice of the pre-training data source is essential for the few-shot transfer, but its role decreases as more data is made available for fine-tuning. Additionally, we explore the role of data curation and examine the trade-offs between label noise and the size of the pre-training dataset. We find that using 2000X more pre-training data from LAION can match the performance of supervised ImageNet pre-training. Furthermore, we investigate the effect of pre-training methods, comparing language-image contrastive vs. image-image contrastive, and find that the latter leads to better downstream accuracy
REPAIR: REnormalizing Permuted Activations for Interpolation Repair
Nov 15, 2022


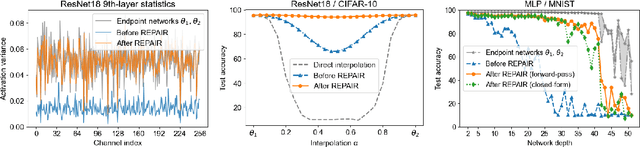
In this paper we look into the conjecture of Entezari et al.(2021) which states that if the permutation invariance of neural networks is taken into account, then there is likely no loss barrier to the linear interpolation between SGD solutions. First, we observe that neuron alignment methods alone are insufficient to establish low-barrier linear connectivity between SGD solutions due to a phenomenon we call variance collapse: interpolated deep networks suffer a collapse in the variance of their activations, causing poor performance. Next, we propose REPAIR (REnormalizing Permuted Activations for Interpolation Repair) which mitigates variance collapse by rescaling the preactivations of such interpolated networks. We explore the interaction between our method and the choice of normalization layer, network width, and depth, and demonstrate that using REPAIR on top of neuron alignment methods leads to 60%-100% relative barrier reduction across a wide variety of architecture families and tasks. In particular, we report a 74% barrier reduction for ResNet50 on ImageNet and 90% barrier reduction for ResNet18 on CIFAR10.