 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Input Transformations by Low-Dimensional Parameter Subspaces
Paper and Code
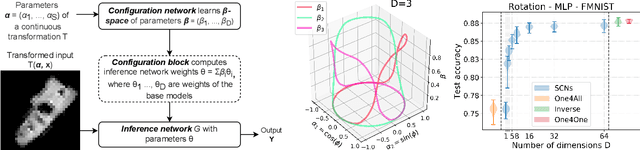
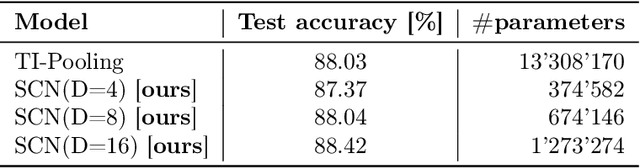
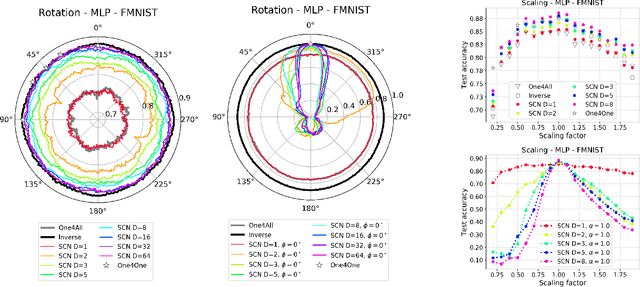
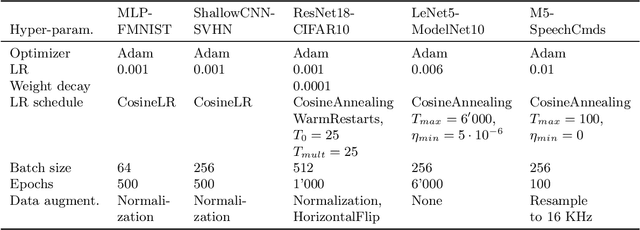
Deep models lack robustness to simple input transformations such as rotation, scaling, and translation, unless they feature a particular invariant architecture or undergo specific training, e.g., learning the desired robustness from data augmentations. Alternatively, input transformations can be treated as a domain shift problem, and solved by post-deployment model adaptation. Although a large number of methods deal with transformed inputs, the fundamental relation between input transformations and optimal model weights is unknown. In this paper, we put forward the configuration subspace hypothesis that model weights optimal for parameterized continuous transformations can reside in low-dimensional linear subspaces. We introduce subspace-configurable networks to learn these subspaces and observe their structure and surprisingly low dimensionality on all tested transformations, datasets and architectures from computer vision and audio signal processing domains. Our findings enable efficient model reconfiguration, especially when limited storage and computing resources are at stake.