 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAIL: Post-hoc Compensation by Linear Reconstruction for Compressed Networks
Mar 02, 2026Structured deep model compression methods are hardware-friendly and substantially reduce memory and inference costs. However, under aggressive compression, the resulting accuracy degradation often necessitates post-compression finetuning, which can be impractical due to missing labeled data or high training cost. We propose post-hoc blockwise compensation, called GRAIL, a simple zero-finetuning step applied after model compression that restores each block's input-output behavior using a small calibration set. The method summarizes hidden activations via a Gram matrix and applies ridge regression to linearly reconstruct the original hidden representation from the reduced one. The resulting reconstruction map is absorbed into the downstream projection weights, while the upstream layer is compressed. The approach is selector-agnostic (Magnitude, Wanda, Gram-based selection, or folding), data-aware (requiring only a few forward passes without gradients or labels), and recovers classic pruning or folding when the Gram matrix is near identity, indicating weak inter-channel correlations. Across ResNets, ViTs, and decoder-only LLMs, GRAIL consistently improves accuracy or perplexity over data-free and data-aware pruning or folding baselines in practical compression regimes, with manageable overhead and no backpropagation. The code is available at https://github.com/TWWinde/GRAIL_Compensation.
PCDCNet: A Surrogate Model for Air Quality Forecasting with Physical-Chemical Dynamics and Constraints
May 26, 2025Air quality forecasting (AQF) is critical for public health and environmental management, yet remains challenging due to the complex interplay of emissions, meteorology, and chemical transformations. Traditional numerical models, such as CMAQ and WRF-Chem, provide physically grounded simulations but are computationally expensive and rely on uncertain emission inventories. Deep learning models, while computationally efficient, often struggle with generalization due to their lack of physical constraints. To bridge this gap, we propose PCDCNet, a surrogate model that integrates numerical modeling principles with deep learning. PCDCNet explicitly incorporates emissions, meteorological influences, and domain-informed constraints to model pollutant formation, transport, and dissipation. By combining graph-based spatial transport modeling, recurrent structures for temporal accumulation, and representation enhancement for local interactions, PCDCNet achieves state-of-the-art (SOTA) performance in 72-hour station-level PM2.5 and O3 forecasting while significantly reducing computational costs. Furthermore, our model is deployed in an online platform, providing free, real-time air quality forecasts, demonstrating its scalability and societal impact. By aligning deep learning with physical consistency, PCDCNet offers a practical and interpretable solution for AQF, enabling informed decision-making for both personal and regulatory applications.
MIMONet: Multi-Input Multi-Output On-Device Deep Learning
Jul 22, 2023
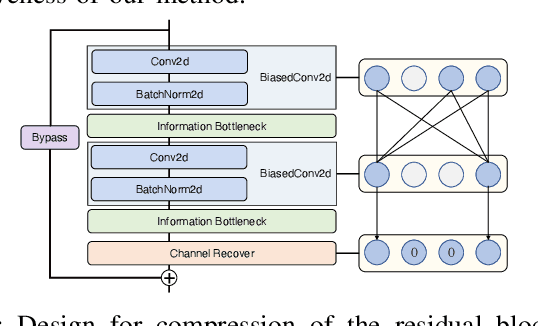


Future intelligent robots are expected to process multiple inputs simultaneously (such as image and audio data) and generate multiple outputs accordingly (such as gender and emotion), similar to humans. Recent research has shown that multi-input single-output (MISO) deep neural networks (DNN) outperform traditional single-input single-output (SISO) models, representing a significant step towards this goal. In this paper, we propose MIMONet, a novel on-device multi-input multi-output (MIMO) DNN framework that achieves high accuracy and on-device efficiency in terms of critical performance metrics such as latency, energy, and memory usage. Leveraging existing SISO model compression techniques, MIMONet develops a new deep-compression method that is specifically tailored to MIMO models. This new method explores unique yet non-trivial properties of the MIMO model, resulting in boosted accuracy and on-device efficiency. Extensive experiments on three embedded platforms commonly used in robotic systems, as well as a case study using the TurtleBot3 robot, demonstrate that MIMONet achieves higher accuracy and superior on-device efficiency compared to state-of-the-art SISO and MISO models, as well as a baseline MIMO model we constructed. Our evaluation highlights the real-world applicability of MIMONet and its potential to significantly enhance the performance of intelligent robotic systems.
Localised Adaptive Spatial-Temporal Graph Neural Network
Jun 15, 2023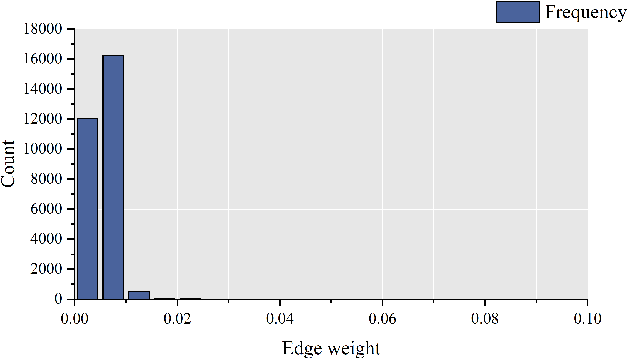
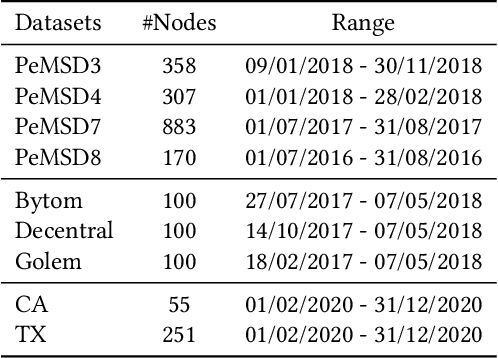
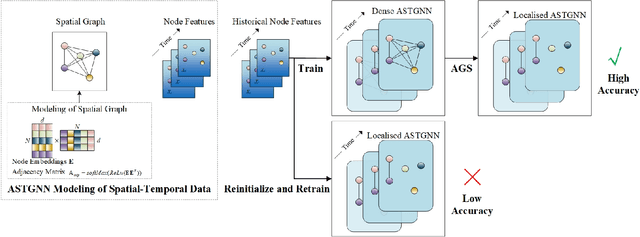

Spatial-temporal graph models are prevailing for abstracting and modelling spatial and temporal dependencies. In this work, we ask the following question: whether and to what extent can we localise spatial-temporal graph models? We limit our scope to adaptive spatial-temporal graph neural networks (ASTGNNs), the state-of-the-art model architecture. Our approach to localisation involves sparsifying the spatial graph adjacency matrices. To this end, we propose Adaptive Graph Sparsification (AGS), a graph sparsification algorithm which successfully enables the localisation of ASTGNNs to an extreme extent (fully localisation). We apply AGS to two distinct ASTGNN architectures and nine spatial-temporal datasets. Intriguingly, we observe that spatial graphs in ASTGNNs can be sparsified by over 99.5\% without any decline in test accuracy. Furthermore, even when ASTGNNs are fully localised, becoming graph-less and purely temporal, we record no drop in accuracy for the majority of tested datasets, with only minor accuracy deterioration observed in the remaining datasets. However, when the partially or fully localised ASTGNNs are reinitialised and retrained on the same data, there is a considerable and consistent drop in accuracy. Based on these observations, we reckon that \textit{(i)} in the tested data, the information provided by the spatial dependencies is primarily included in the information provided by the temporal dependencies and, thus, can be essentially ignored for inference; and \textit{(ii)} although the spatial dependencies provide redundant information, it is vital for the effective training of ASTGNNs and thus cannot be ignored during training. Furthermore, the localisation of ASTGNNs holds the potential to reduce the heavy computation overhead required on large-scale spatial-temporal data and further enable the distributed deployment of ASTGNNs.
Representing Input Transformations by Low-Dimensional Parameter Subspaces
May 22, 2023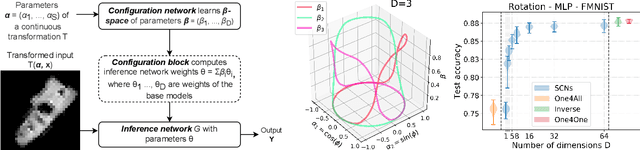
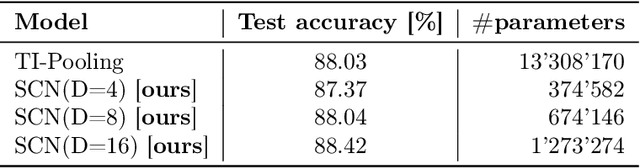
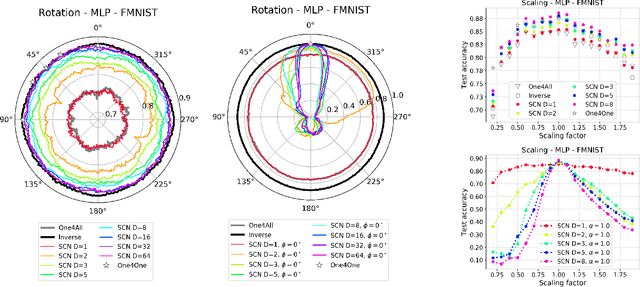
Deep models lack robustness to simple input transformations such as rotation, scaling, and translation, unless they feature a particular invariant architecture or undergo specific training, e.g., learning the desired robustness from data augmentations. Alternatively, input transformations can be treated as a domain shift problem, and solved by post-deployment model adaptation. Although a large number of methods deal with transformed inputs, the fundamental relation between input transformations and optimal model weights is unknown. In this paper, we put forward the configuration subspace hypothesis that model weights optimal for parameterized continuous transformations can reside in low-dimensional linear subspaces. We introduce subspace-configurable networks to learn these subspaces and observe their structure and surprisingly low dimensionality on all tested transformations, datasets and architectures from computer vision and audio signal processing domains. Our findings enable efficient model reconfiguration, especially when limited storage and computing resources are at stake.
p-Meta: Towards On-device Deep Model Adaptation
Jun 25, 2022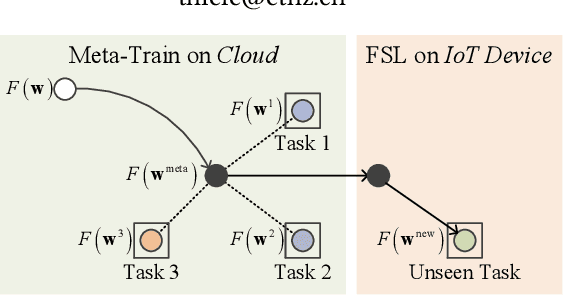

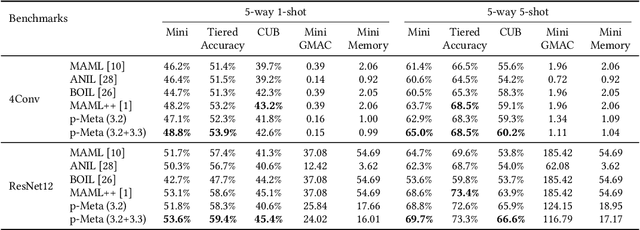
Data collected by IoT devices are often private and have a large diversity across users. Therefore, learning requires pre-training a model with available representative data samples, deploying the pre-trained model on IoT devices, and adapting the deployed model on the device with local data. Such an on-device adaption for deep learning empowered applications demands data and memory efficiency. However, existing gradient-based meta learning schemes fail to support memory-efficient adaptation. To this end, we propose p-Meta, a new meta learning method that enforces structure-wise partial parameter updates while ensuring fast generalization to unseen tasks. Evaluations on few-shot image classification and reinforcement learning tasks show that p-Meta not only improves the accuracy but also substantially reduces the peak dynamic memory by a factor of 2.5 on average compared to state-of-the-art few-shot adaptation methods.
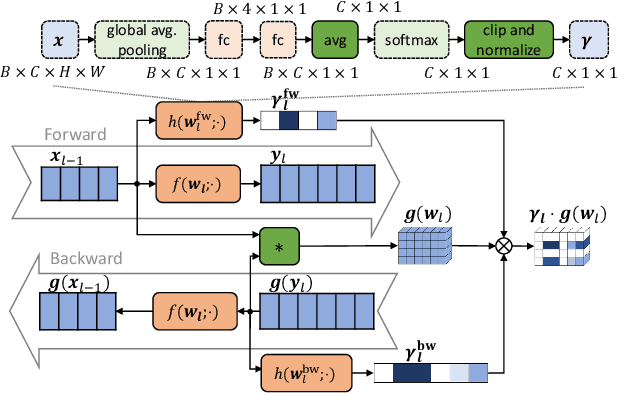
Hyper Attention Recurrent Neural Network: Tackling Temporal Covariate Shift in Time Series Analysis
Feb 22, 2022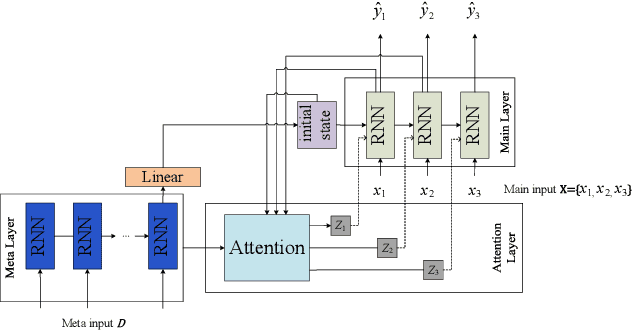
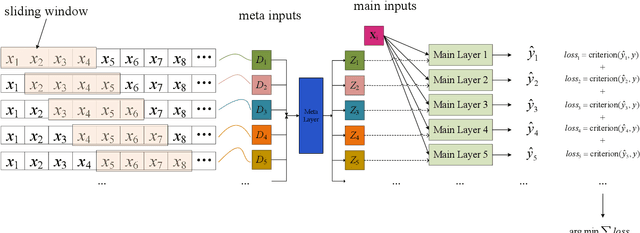
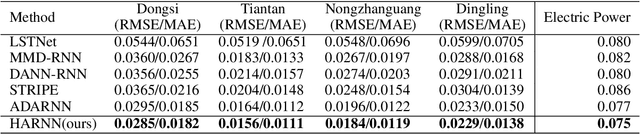
Analyzing long time series with RNNs often suffers from infeasible training. Segmentation is therefore commonly used in data pre-processing. However, in non-stationary time series, there exists often distribution shift among different segments. RNN is easily swamped in the dilemma of fitting bias in these segments due to the lack of global information, leading to poor generalization, known as Temporal Covariate Shift (TCS) problem, which is only addressed by a recently proposed RNN-based model. One of the assumptions in TCS is that the distribution of all divided intervals under the same segment are identical. This assumption, however, may not be true on high-frequency time series, such as traffic flow, that also have large stochasticity. Besides, macro information across long periods isn't adequately considered in the latest RNN-based methods. To address the above issues, we propose Hyper Attention Recurrent Neural Network (HARNN) for the modeling of temporal patterns containing both micro and macro information. An HARNN consists of a meta layer for parameter generation and an attention-enabled main layer for inference. High-frequency segments are transformed into low-frequency segments and fed into the meta layers, while the first main layer consumes the same high-frequency segments as conventional methods. In this way, each low-frequency segment in the meta inputs generates a unique main layer, enabling the integration of both macro information and micro information for inference. This forces all main layers to predict the same target which fully harnesses the common knowledge in varied distributions when capturing temporal patterns. Evaluations on multiple benchmarks demonstrated that our model outperforms a couple of RNN-based methods on a federation of key metrics.
Memory-Aware Partitioning of Machine Learning Applications for Optimal Energy Use in Batteryless Systems
Aug 05, 2021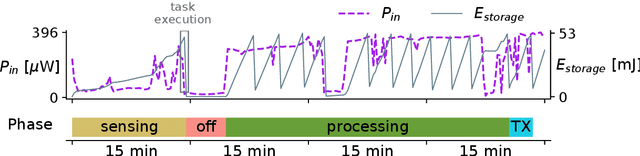
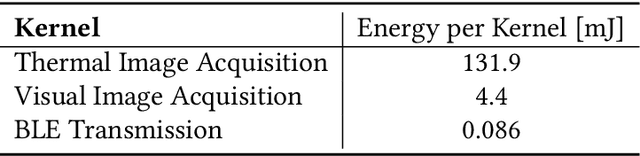
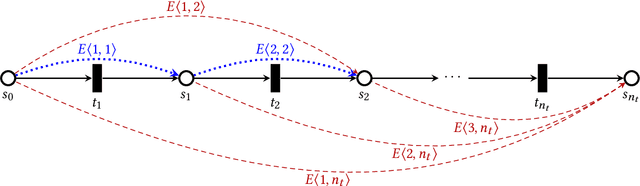
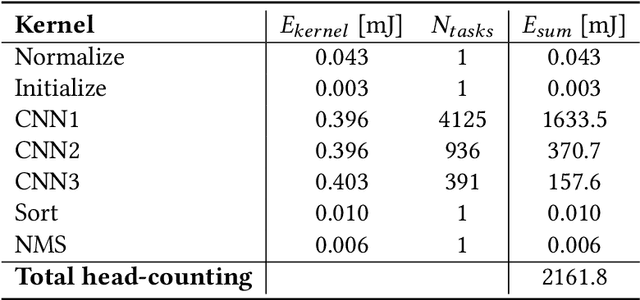
Sensing systems powered by energy harvesting have traditionally been designed to tolerate long periods without energy. As the Internet of Things (IoT) evolves towards a more transient and opportunistic execution paradigm, reducing energy storage costs will be key for its economic and ecologic viability. However, decreasing energy storage in harvesting systems introduces reliability issues. Transducers only produce intermittent energy at low voltage and current levels, making guaranteed task completion a challenge. Existing ad hoc methods overcome this by buffering enough energy either for single tasks, incurring large data-retention overheads, or for one full application cycle, requiring a large energy buffer. We present Julienning: an automated method for optimizing the total energy cost of batteryless applications. Using a custom specification model, developers can describe transient applications as a set of atomically executed kernels with explicit data dependencies. Our optimization flow can partition data- and energy-intensive applications into multiple execution cycles with bounded energy consumption. By leveraging interkernel data dependencies, these energy-bounded execution cycles minimize the number of system activations and nonvolatile data transfers, and thus the total energy overhead. We validate our methodology with two batteryless cameras running energy-intensive machine learning applications. Results demonstrate that compared to ad hoc solutions, our method can reduce the required energy storage by over 94% while only incurring a 0.12% energy overhead.
Using system context information to complement weakly labeled data
Jul 19, 2021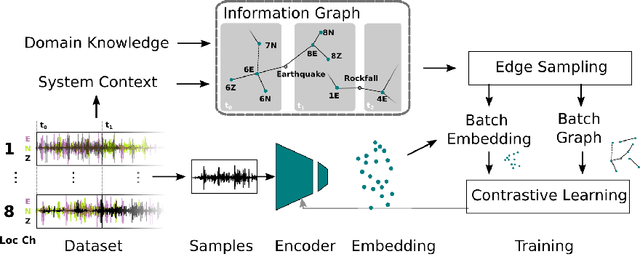

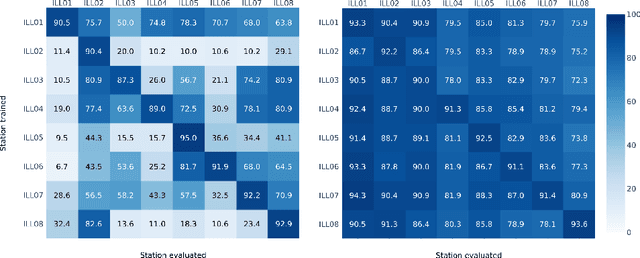
Real-world datasets collected with sensor networks often contain incomplete and uncertain labels as well as artefacts arising from the system environment. Complete and reliable labeling is often infeasible for large-scale and long-term sensor network deployments due to the labor and time overhead, limited availability of experts and missing ground truth. In addition, if the machine learning method used for analysis is sensitive to certain features of a deployment, labeling and learning needs to be repeated for every new deployment. To address these challenges, we propose to make use of system context information formalized in an information graph and embed it in the learning process via contrastive learning. Based on real-world data we show that this approach leads to an increased accuracy in case of weakly labeled data and leads to an increased robustness and transferability of the classifier to new sensor locations.
Measuring what Really Matters: Optimizing Neural Networks for TinyML
Apr 21, 2021
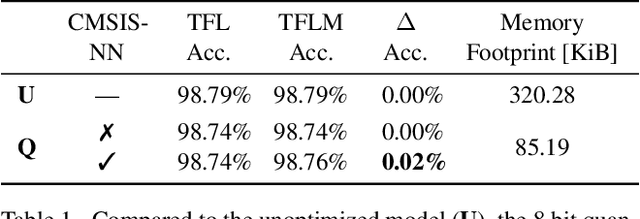
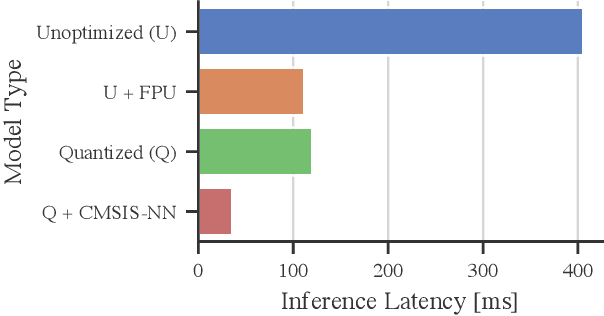
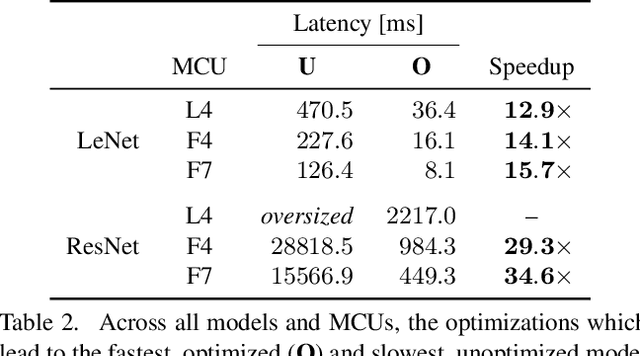
With the surge of inexpensive computational and memory resources, neural networks (NNs) have experienced an unprecedented growth in architectural and computational complexity. Introducing NNs to resource-constrained devices enables cost-efficient deployments, widespread availability, and the preservation of sensitive data. This work addresses the challenges of bringing Machine Learning to MCUs, where we focus on the ubiquitous ARM Cortex-M architecture. The detailed effects and trade-offs that optimization methods, software frameworks, and MCU hardware architecture have on key performance metrics such as inference latency and energy consumption have not been previously studied in depth for state-of-the-art frameworks such as TensorFlow Lite Micro. We find that empirical investigations which measure the perceptible metrics - performance as experienced by the user - are indispensable, as the impact of specialized instructions and layer types can be subtle. To this end, we propose an implementation-aware design as a cost-effective method for verification and benchmarking. Employing our developed toolchain, we demonstrate how existing NN deployments on resource-constrained devices can be improved by systematically optimizing NNs to their targeted application scenario.