 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring what Really Matters: Optimizing Neural Networks for TinyML
Paper and Code

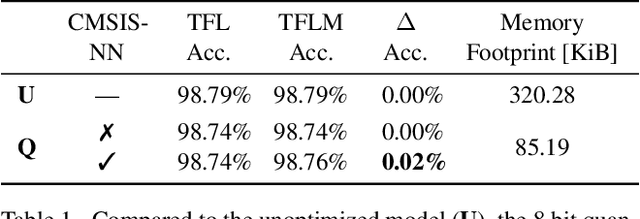
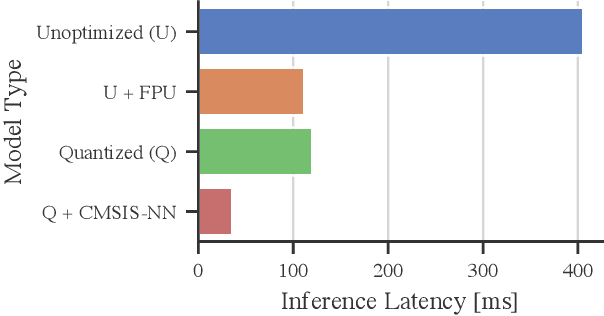
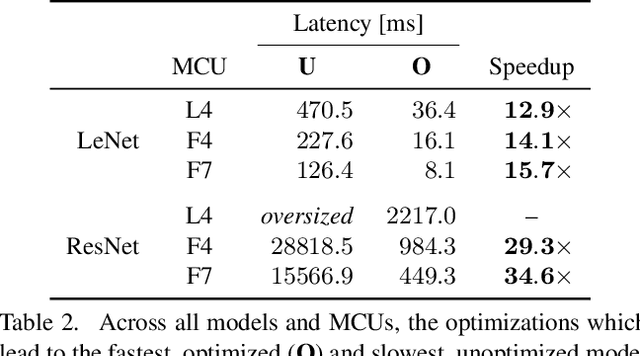
With the surge of inexpensive computational and memory resources, neural networks (NNs) have experienced an unprecedented growth in architectural and computational complexity. Introducing NNs to resource-constrained devices enables cost-efficient deployments, widespread availability, and the preservation of sensitive data. This work addresses the challenges of bringing Machine Learning to MCUs, where we focus on the ubiquitous ARM Cortex-M architecture. The detailed effects and trade-offs that optimization methods, software frameworks, and MCU hardware architecture have on key performance metrics such as inference latency and energy consumption have not been previously studied in depth for state-of-the-art frameworks such as TensorFlow Lite Micro. We find that empirical investigations which measure the perceptible metrics - performance as experienced by the user - are indispensable, as the impact of specialized instructions and layer types can be subtle. To this end, we propose an implementation-aware design as a cost-effective method for verification and benchmarking. Employing our developed toolchain, we demonstrate how existing NN deployments on resource-constrained devices can be improved by systematically optimizing NNs to their targeted application scenario.