 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMS: Intelligent Hardware Monitoring System for Secure SoCs
Jan 16, 2026In the modern Systems-on-Chip (SoC), the Advanced eXtensible Interface (AXI) protocol exhibits security vulnerabilities, enabling partial or complete denial-of-service (DoS) through protocol-violation attacks. The recent countermeasures lack a dedicated real-time protocol semantic analysis and evade protocol compliance checks. This paper tackles this AXI vulnerability issue and presents an intelligent hardware monitoring system (IMS) for real-time detection of AXI protocol violations. IMS is a hardware module leveraging neural networks to achieve high detection accuracy. For model training, we perform DoS attacks through header-field manipulation and systematic malicious operations, while recording AXI transactions to build a training dataset. We then deploy a quantization-optimized neural network, achieving 98.7% detection accuracy with <=3% latency overhead, and throughput of >2.5 million inferences/s. We subsequently integrate this IMS into a RISC-V SoC as a memory-mapped IP core to monitor its AXI bus. For demonstration and initial assessment for later ASIC integration, we implemented this IMS on an AMD Zynq UltraScale+ MPSoC ZCU104 board, showing an overall small hardware footprint (9.04% look-up-tables (LUTs), 0.23% DSP slices, and 0.70% flip-flops) and negligible impact on the overall design's achievable frequency. This demonstrates the feasibility of lightweight, security monitoring for resource-constrained edge environments.
Solar Panel-based Visible Light Communication for Batteryless Systems
Jan 07, 2026This paper presents a batteryless wireless communication node for the Internet of Things, powered entirely by ambient light and capable of receiving data through visible light communication. A solar panel serves dual functions as an energy harvester and an optical antenna, capturing modulated signals from LED light sources. A lightweight analog front-end filters and digitizes the signals for an 8-bit low-power processor, which manages the system's operational states based on stored energy levels. The main processor is selectively activated to minimize energy consumption. Data reception is synchronized with the harvester's open-circuit phase, reducing interference and improving signal quality. The prototype reliably decodes 32-bit VLC frames at 800\,Herz, consuming less than 2.8\,mJ, and maintains sleep-mode power below 30\,uW.
Embedding Autonomous Agents in Resource-Constrained Robotic Platforms
Jan 07, 2026Many embedded devices operate under resource constraints and in dynamic environments, requiring local decision-making capabilities. Enabling devices to make independent decisions in such environments can improve the responsiveness of the system and reduce the dependence on constant external control. In this work, we integrate an autonomous agent, programmed using AgentSpeak, with a small two-wheeled robot that explores a maze using its own decision-making and sensor data. Experimental results show that the agent successfully solved the maze in 59 seconds using 287 reasoning cycles, with decision phases taking less than one millisecond. These results indicate that the reasoning process is efficient enough for real-time execution on resource-constrained hardware. This integration demonstrates how high-level agent-based control can be applied to resource-constrained embedded systems for autonomous operation.
Space Debris Removal using Nano-Satellites controlled by Low-Power Autonomous Agents
Jan 01, 2026Space debris is an ever-increasing problem in space travel. There are already many old, no longer functional spacecraft and debris orbiting the earth, which endanger both the safe operation of satellites and space travel. Small nano-satellite swarms can address this problem by autonomously de-orbiting debris safely into the Earth's atmosphere. This work builds on the recent advances of autonomous agents deployed in resource-constrained platforms and shows a first simplified approach how such intelligent and autonomous nano-satellite swarms can be realized. We implement our autonomous agent software on wireless microcontrollers and perform experiments on a specialized test-bed to show the feasibility and overall energy efficiency of our approach.
Mixed-feature Logistic Regression Robust to Distribution Shifts
Mar 15, 2025Logistic regression models are widely used in the social and behavioral sciences and in high-stakes domains, due to their simplicity and interpretability properties. At the same time, such domains are permeated by distribution shifts, where the distribution generating the data changes between training and deployment. In this paper, we study a distributionally robust logistic regression problem that seeks the model that will perform best against adversarial realizations of the data distribution drawn from a suitably constructed Wasserstein ambiguity set. Our model and solution approach differ from prior work in that we can capture settings where the likelihood of distribution shifts can vary across features, significantly broadening the applicability of our model relative to the state-of-the-art. We propose a graph-based solution approach that can be integrated into off-the-shelf optimization solvers. We evaluate the performance of our model and algorithms on numerous publicly available datasets. Our solution achieves a 408x speed-up relative to the state-of-the-art. Additionally, compared to the state-of-the-art, our model reduces average calibration error by up to 36.19% and worst-case calibration error by up to 41.70%, while increasing the average area under the ROC curve (AUC) by up to 18.02% and worst-case AUC by up to 48.37%.
Solution Path of Time-varying Markov Random Fields with Discrete Regularization
Jul 25, 2023We study the problem of inferring sparse time-varying Markov random fields (MRFs) with different discrete and temporal regularizations on the parameters. Due to the intractability of discrete regularization, most approaches for solving this problem rely on the so-called maximum-likelihood estimation (MLE) with relaxed regularization, which neither results in ideal statistical properties nor scale to the dimensions encountered in realistic settings. In this paper, we address these challenges by departing from the MLE paradigm and resorting to a new class of constrained optimization problems with exact, discrete regularization to promote sparsity in the estimated parameters. Despite the nonconvex and discrete nature of our formulation, we show that it can be solved efficiently and parametrically for all sparsity levels. More specifically, we show that the entire solution path of the time-varying MRF for all sparsity levels can be obtained in $\mathcal{O}(pT^3)$, where $T$ is the number of time steps and $p$ is the number of unknown parameters at any given time. The efficient and parametric characterization of the solution path renders our approach highly suitable for cross-validation, where parameter estimation is required for varying regularization values. Despite its simplicity and efficiency, we show that our proposed approach achieves provably small estimation error for different classes of time-varying MRFs, namely Gaussian and discrete MRFs, with as few as one sample per time. Utilizing our algorithm, we can recover the complete solution path for instances of time-varying MRFs featuring over 30 million variables in less than 12 minutes on a standard laptop computer. Our code is available at \url{https://sites.google.com/usc.edu/gomez/data}.
Memory-Aware Partitioning of Machine Learning Applications for Optimal Energy Use in Batteryless Systems
Aug 05, 2021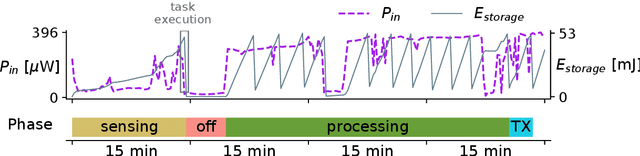
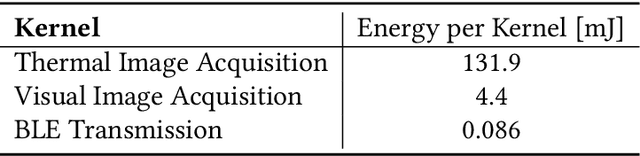
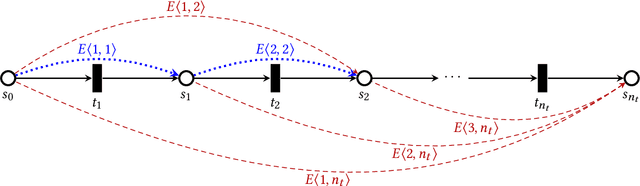
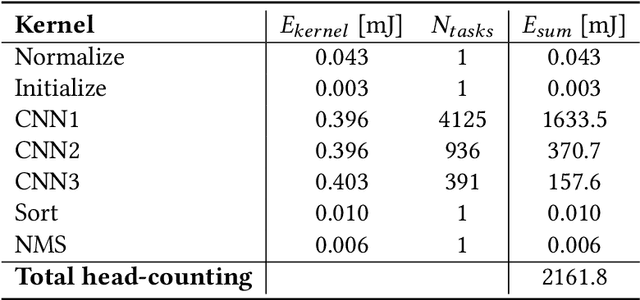
Sensing systems powered by energy harvesting have traditionally been designed to tolerate long periods without energy. As the Internet of Things (IoT) evolves towards a more transient and opportunistic execution paradigm, reducing energy storage costs will be key for its economic and ecologic viability. However, decreasing energy storage in harvesting systems introduces reliability issues. Transducers only produce intermittent energy at low voltage and current levels, making guaranteed task completion a challenge. Existing ad hoc methods overcome this by buffering enough energy either for single tasks, incurring large data-retention overheads, or for one full application cycle, requiring a large energy buffer. We present Julienning: an automated method for optimizing the total energy cost of batteryless applications. Using a custom specification model, developers can describe transient applications as a set of atomically executed kernels with explicit data dependencies. Our optimization flow can partition data- and energy-intensive applications into multiple execution cycles with bounded energy consumption. By leveraging interkernel data dependencies, these energy-bounded execution cycles minimize the number of system activations and nonvolatile data transfers, and thus the total energy overhead. We validate our methodology with two batteryless cameras running energy-intensive machine learning applications. Results demonstrate that compared to ad hoc solutions, our method can reduce the required energy storage by over 94% while only incurring a 0.12% energy overhead.
Scalable Inference of Sparsely-changing Markov Random Fields with Strong Statistical Guarantees
Feb 06, 2021


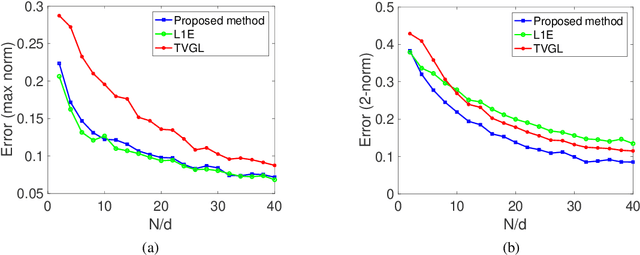
In this paper, we study the problem of inferring time-varying Markov random fields (MRF), where the underlying graphical model is both sparse and changes sparsely over time. Most of the existing methods for the inference of time-varying MRFs rely on the regularized maximum likelihood estimation (MLE), that typically suffer from weak statistical guarantees and high computational time. Instead, we introduce a new class of constrained optimization problems for the inference of sparsely-changing MRFs. The proposed optimization problem is formulated based on the exact $\ell_0$ regularization, and can be solved in near-linear time and memory. Moreover, we show that the proposed estimator enjoys a provably small estimation error. As a special case, we derive sharp statistical guarantees for the inference of sparsely-changing Gaussian MRFs (GMRF) in the high-dimensional regime, showing that such problems can be learned with as few as one sample per time. Our proposed method is extremely efficient in practice: it can accurately estimate sparsely-changing graphical models with more than 500 million variables in less than one hour.
Supermodularity and valid inequalities for quadratic optimization with indicators
Dec 29, 2020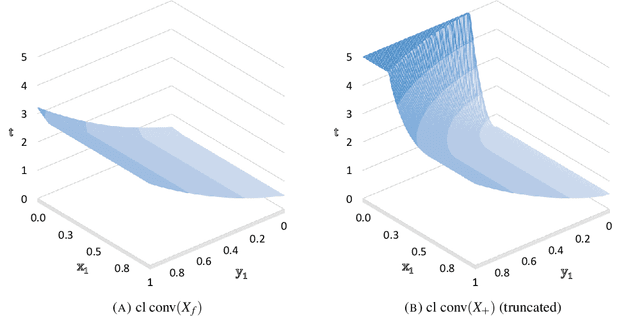
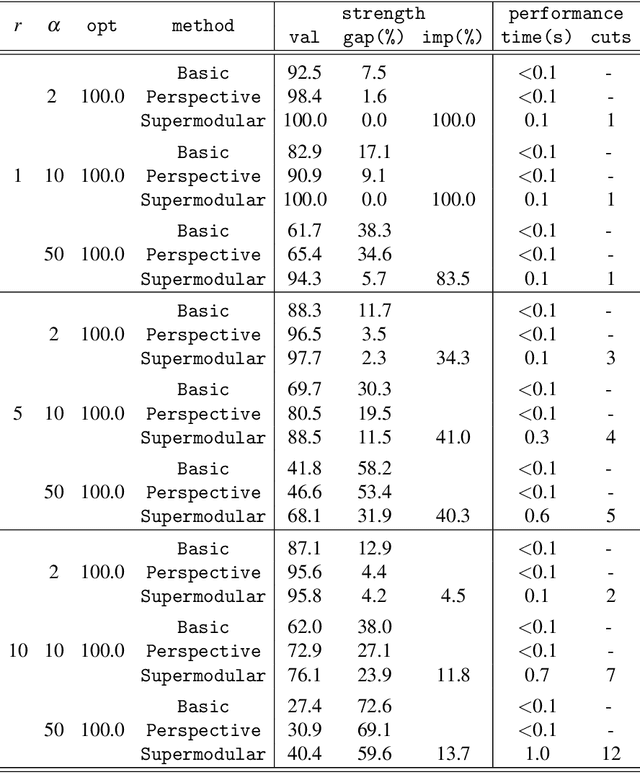
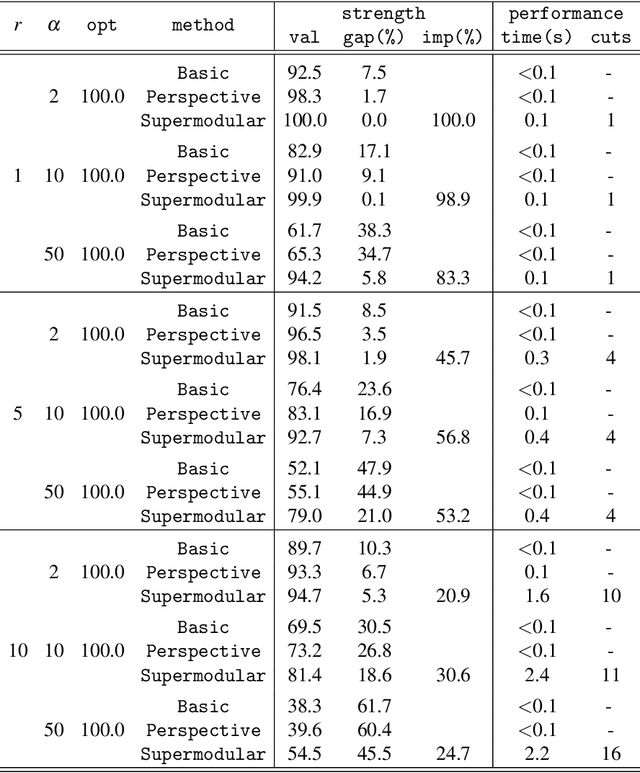
We study the minimization of a rank-one quadratic with indicators and show that the underlying set function obtained by projecting out the continuous variables is supermodular. Although supermodular minimization is, in general, difficult, the specific set function for the rank-one quadratic can be minimized in linear time. We show that the convex hull of the epigraph of the quadratic can be obtaining from inequalities for the underlying supermodular set function by lifting them into nonlinear inequalities in the original space of variables. Explicit forms of the convex-hull description are given, both in the original space of variables and in an extended formulation via conic quadratic-representable inequalities, along with a polynomial separation algorithm. Computational experiments indicate that the lifted supermodular inequalities in conic quadratic form are quite effective in reducing the integrality gap for quadratic optimization with indicators.
Ideal formulations for constrained convex optimization problems with indicator variables
Jun 30, 2020
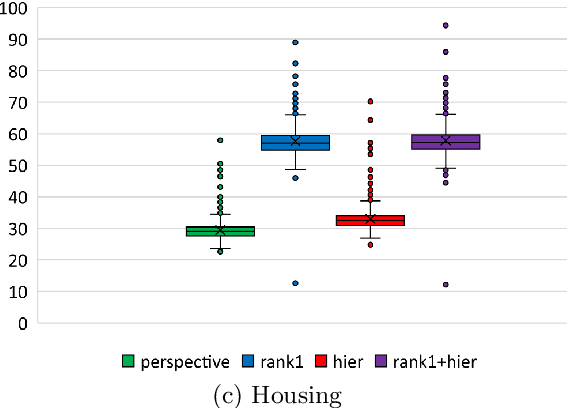
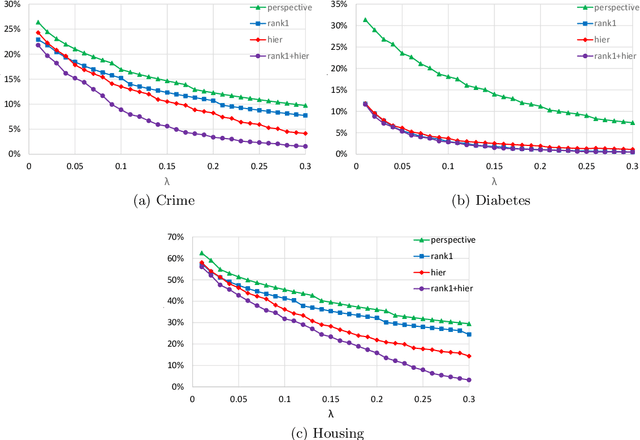
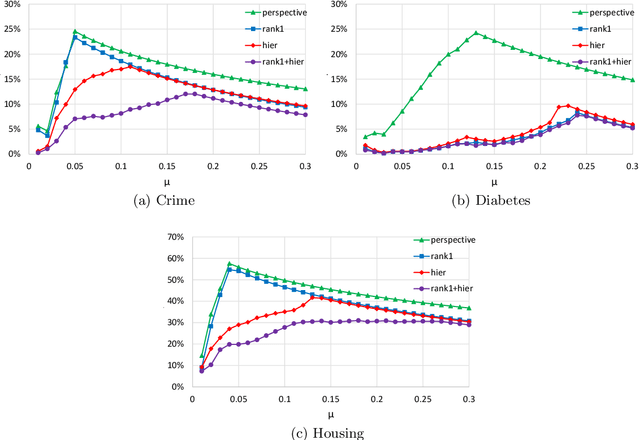
Motivated by modern regression applications, in this paper, we study the convexification of a class of convex optimization problems with indicator variables and combinatorial constraints on the indicators. Unlike most of the previous work on convexification of sparse regression problems, we simultaneously consider the nonlinear non-separable objective, indicator variables, and combinatorial constraints. Specifically, we give the convex hull description of the epigraph of the composition of a one-dimensional convex function and an affine function under arbitrary combinatorial constraints. As special cases of this result, we derive ideal convexifications for problems with hierarchy, multi-collinearity, and sparsity constraints. Moreover, we also give a short proof that for a separable objective function, the perspective reformulation is ideal independent from the constraints of the problem. Our computational experiments with regression problems under hierarchy constraints on real datasets demonstrate the potential of the proposed approach in improving the relaxation quality without significant computational overhead.