 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the convex hull of convex quadratic optimization problems with indicators
Jan 02, 2022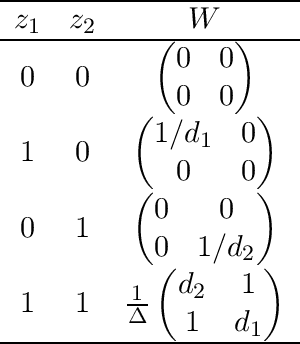
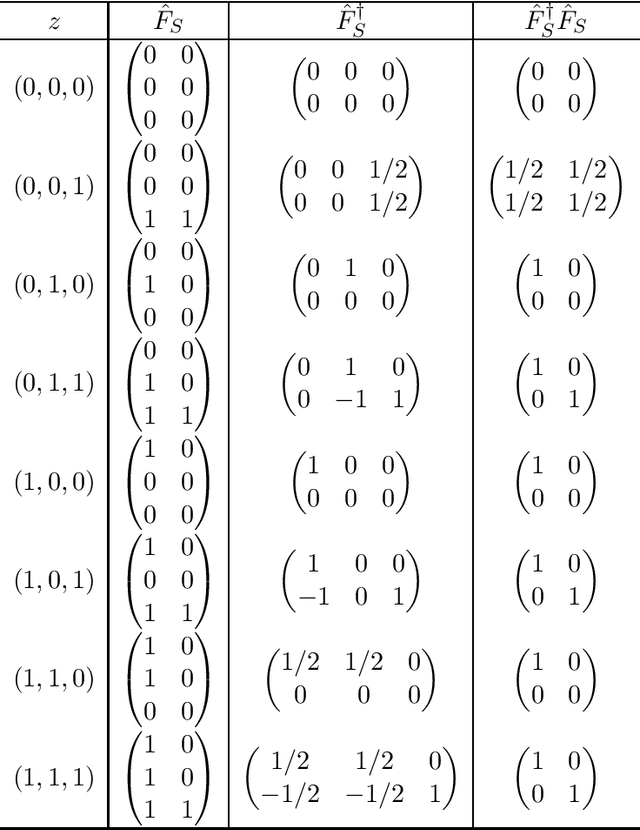
We consider the convex quadratic optimization problem with indicator variables and arbitrary constraints on the indicators. We show that a convex hull description of the associated mixed-integer set in an extended space with a quadratic number of additional variables consists of a single positive semidefinite constraint (explicitly stated) and linear constraints. In particular, convexification of this class of problems reduces to describing a polyhedral set in an extended formulation. We also give descriptions in the original space of variables: we provide a description based on an infinite number of conic-quadratic inequalities, which are "finitely generated." In particular, it is possible to characterize whether a given inequality is necessary to describe the convex-hull. The new theory presented here unifies several previously established results, and paves the way toward utilizing polyhedral methods to analyze the convex hull of mixed-integer nonlinear sets.
Ideal formulations for constrained convex optimization problems with indicator variables
Jun 30, 2020
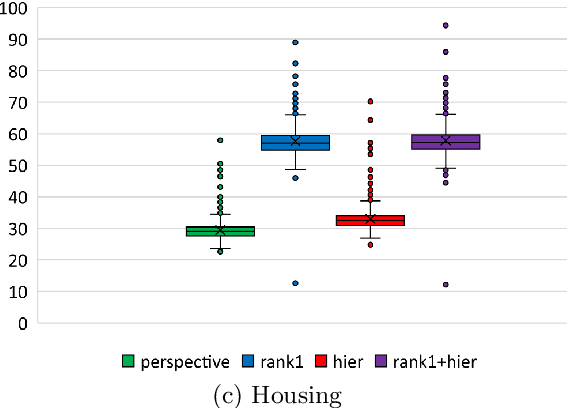
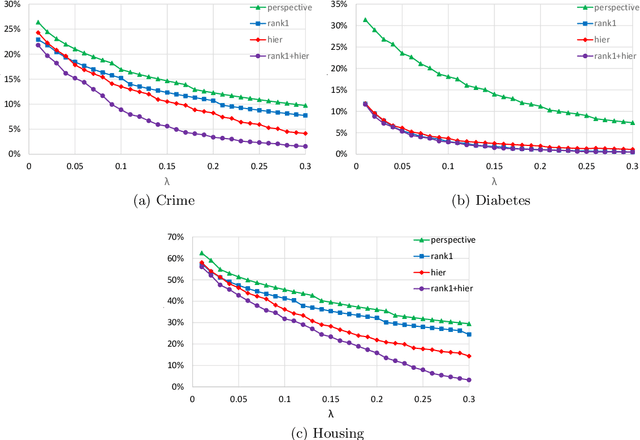
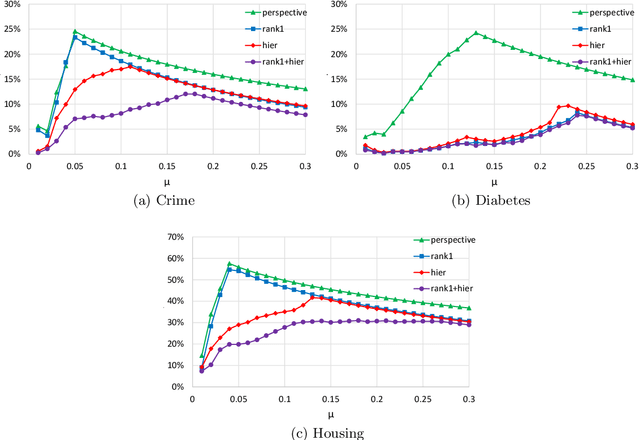
Motivated by modern regression applications, in this paper, we study the convexification of a class of convex optimization problems with indicator variables and combinatorial constraints on the indicators. Unlike most of the previous work on convexification of sparse regression problems, we simultaneously consider the nonlinear non-separable objective, indicator variables, and combinatorial constraints. Specifically, we give the convex hull description of the epigraph of the composition of a one-dimensional convex function and an affine function under arbitrary combinatorial constraints. As special cases of this result, we derive ideal convexifications for problems with hierarchy, multi-collinearity, and sparsity constraints. Moreover, we also give a short proof that for a separable objective function, the perspective reformulation is ideal independent from the constraints of the problem. Our computational experiments with regression problems under hierarchy constraints on real datasets demonstrate the potential of the proposed approach in improving the relaxation quality without significant computational overhead.
Consistent Second-Order Conic Integer Programming for Learning Bayesian Networks
Jun 13, 2020
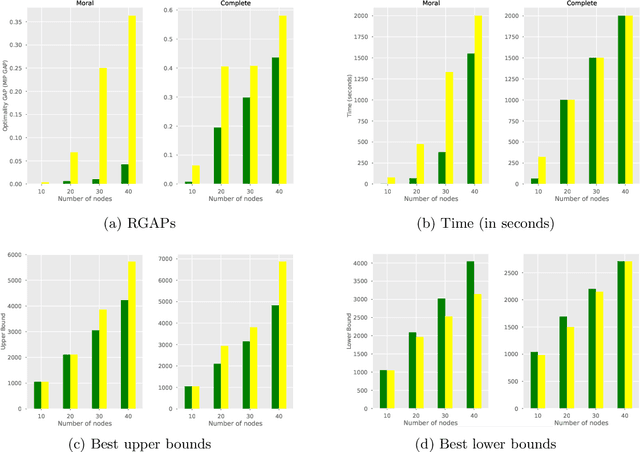
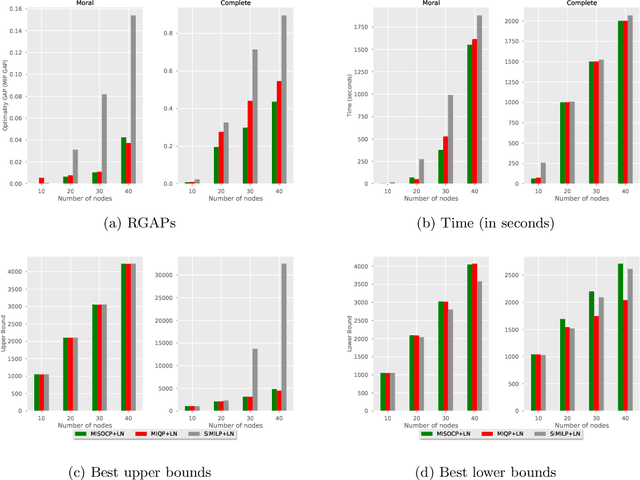
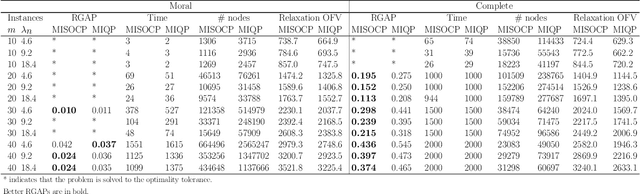
Bayesian Networks (BNs) represent conditional probability relations among a set of random variables (nodes) in the form of a directed acyclic graph (DAG), and have found diverse applications in knowledge discovery. We study the problem of learning the sparse DAG structure of a BN from continuous observational data. The central problem can be modeled as a mixed-integer program with an objective function composed of a convex quadratic loss function and a regularization penalty subject to linear constraints. The optimal solution to this mathematical program is known to have desirable statistical properties under certain conditions. However, the state-of-the-art optimization solvers are not able to obtain provably optimal solutions to the existing mathematical formulations for medium-size problems within reasonable computational times. To address this difficulty, we tackle the problem from both computational and statistical perspectives. On the one hand, we propose a concrete early stopping criterion to terminate the branch-and-bound process in order to obtain a near-optimal solution to the mixed-integer program, and establish the consistency of this approximate solution. On the other hand, we improve the existing formulations by replacing the linear "big-$M$" constraints that represent the relationship between the continuous and binary indicator variables with second-order conic constraints. Our numerical results demonstrate the effectiveness of the proposed approaches.