 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Second-Order Conic Integer Programming for Learning Bayesian Networks
Jun 13, 2020
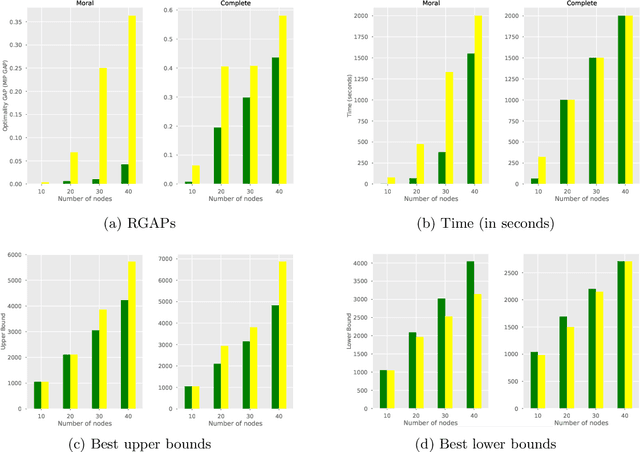
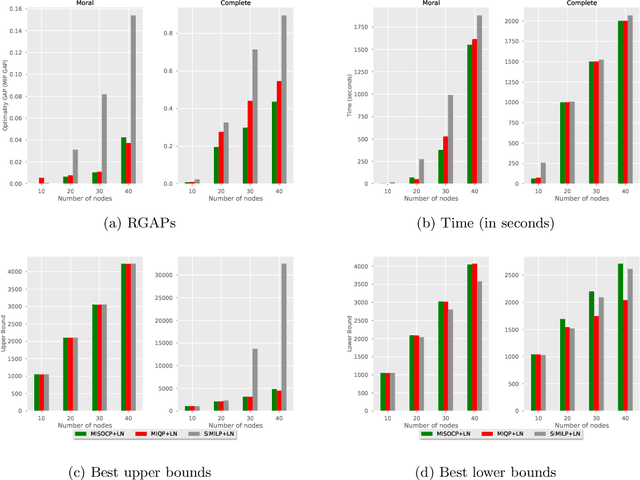
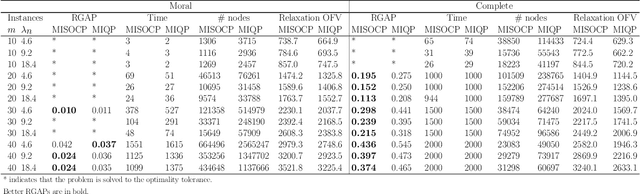
Bayesian Networks (BNs) represent conditional probability relations among a set of random variables (nodes) in the form of a directed acyclic graph (DAG), and have found diverse applications in knowledge discovery. We study the problem of learning the sparse DAG structure of a BN from continuous observational data. The central problem can be modeled as a mixed-integer program with an objective function composed of a convex quadratic loss function and a regularization penalty subject to linear constraints. The optimal solution to this mathematical program is known to have desirable statistical properties under certain conditions. However, the state-of-the-art optimization solvers are not able to obtain provably optimal solutions to the existing mathematical formulations for medium-size problems within reasonable computational times. To address this difficulty, we tackle the problem from both computational and statistical perspectives. On the one hand, we propose a concrete early stopping criterion to terminate the branch-and-bound process in order to obtain a near-optimal solution to the mixed-integer program, and establish the consistency of this approximate solution. On the other hand, we improve the existing formulations by replacing the linear "big-$M$" constraints that represent the relationship between the continuous and binary indicator variables with second-order conic constraints. Our numerical results demonstrate the effectiveness of the proposed approaches.
Integer Programming for Learning Directed Acyclic Graphs from Continuous Data
Apr 23, 2019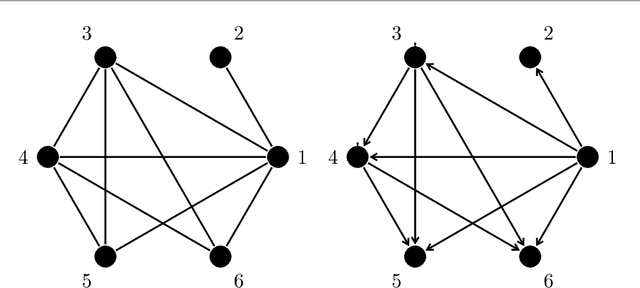

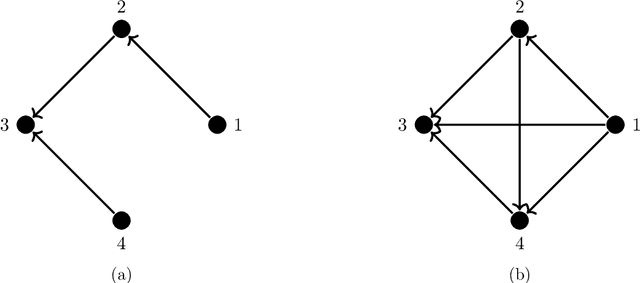
Learning directed acyclic graphs (DAGs) from data is a challenging task both in theory and in practice, because the number of possible DAGs scales superexponentially with the number of nodes. In this paper, we study the problem of learning an optimal DAG from continuous observational data. We cast this problem in the form of a mathematical programming model which can naturally incorporate a super-structure in order to reduce the set of possible candidate DAGs. We use the penalized negative log-likelihood score function with both $\ell_0$ and $\ell_1$ regularizations and propose a new mixed-integer quadratic optimization (MIQO) model, referred to as a layered network (LN) formulation. The LN formulation is a compact model, which enjoys as tight an optimal continuous relaxation value as the stronger but larger formulations under a mild condition. Computational results indicate that the proposed formulation outperforms existing mathematical formulations and scales better than available algorithms that can solve the same problem with only $\ell_1$ regularization. In particular, the LN formulation clearly outperforms existing methods in terms of computational time needed to find an optimal DAG in the presence of a sparse super-structure.