 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward AI Matching Policies in Homeless Services: A Qualitative Study with Policymakers
Aug 10, 2025Artificial intelligence researchers have proposed various data-driven algorithms to improve the processes that match individuals experiencing homelessness to scarce housing resources. It remains unclear whether and how these algorithms are received or adopted by practitioners and what their corresponding consequences are. Through semi-structured interviews with 13 policymakers in homeless services in Los Angeles, we investigate whether such change-makers are open to the idea of integrating AI into the housing resource matching process, identifying where they see potential gains and drawbacks from such a system in issues of efficiency, fairness, and transparency. Our qualitative analysis indicates that, even when aware of various complicating factors, policymakers welcome the idea of an AI matching tool if thoughtfully designed and used in tandem with human decision-makers. Though there is no consensus as to the exact design of such an AI system, insights from policymakers raise open questions and design considerations that can be enlightening for future researchers and practitioners who aim to build responsible algorithmic systems to support decision-making in low-resource scenarios.
Mixed-Integer Optimization for Responsible Machine Learning
May 09, 2025In the last few decades, Machine Learning (ML) has achieved significant success across domains ranging from healthcare, sustainability, and the social sciences, to criminal justice and finance. But its deployment in increasingly sophisticated, critical, and sensitive areas affecting individuals, the groups they belong to, and society as a whole raises critical concerns around fairness, transparency, robustness, and privacy, among others. As the complexity and scale of ML systems and of the settings in which they are deployed grow, so does the need for responsible ML methods that address these challenges while providing guaranteed performance in deployment. Mixed-integer optimization (MIO) offers a powerful framework for embedding responsible ML considerations directly into the learning process while maintaining performance. For example, it enables learning of inherently transparent models that can conveniently incorporate fairness or other domain specific constraints. This tutorial paper provides an accessible and comprehensive introduction to this topic discussing both theoretical and practical aspects. It outlines some of the core principles of responsible ML, their importance in applications, and the practical utility of MIO for building ML models that align with these principles. Through examples and mathematical formulations, it illustrates practical strategies and available tools for efficiently solving MIO problems for responsible ML. It concludes with a discussion on current limitations and open research questions, providing suggestions for future work.
Mixed-feature Logistic Regression Robust to Distribution Shifts
Mar 15, 2025Logistic regression models are widely used in the social and behavioral sciences and in high-stakes domains, due to their simplicity and interpretability properties. At the same time, such domains are permeated by distribution shifts, where the distribution generating the data changes between training and deployment. In this paper, we study a distributionally robust logistic regression problem that seeks the model that will perform best against adversarial realizations of the data distribution drawn from a suitably constructed Wasserstein ambiguity set. Our model and solution approach differ from prior work in that we can capture settings where the likelihood of distribution shifts can vary across features, significantly broadening the applicability of our model relative to the state-of-the-art. We propose a graph-based solution approach that can be integrated into off-the-shelf optimization solvers. We evaluate the performance of our model and algorithms on numerous publicly available datasets. Our solution achieves a 408x speed-up relative to the state-of-the-art. Additionally, compared to the state-of-the-art, our model reduces average calibration error by up to 36.19% and worst-case calibration error by up to 41.70%, while increasing the average area under the ROC curve (AUC) by up to 18.02% and worst-case AUC by up to 48.37%.
Learning Fair Policies for Multi-stage Selection Problems from Observational Data
Dec 20, 2023We consider the problem of learning fair policies for multi-stage selection problems from observational data. This problem arises in several high-stakes domains such as company hiring, loan approval, or bail decisions where outcomes (e.g., career success, loan repayment, recidivism) are only observed for those selected. We propose a multi-stage framework that can be augmented with various fairness constraints, such as demographic parity or equal opportunity. This problem is a highly intractable infinite chance-constrained program involving the unknown joint distribution of covariates and outcomes. Motivated by the potential impact of selection decisions on people's lives and livelihoods, we propose to focus on interpretable linear selection rules. Leveraging tools from causal inference and sample average approximation, we obtain an asymptotically consistent solution to this selection problem by solving a mixed binary conic optimization problem, which can be solved using standard off-the-shelf solvers. We conduct extensive computational experiments on a variety of datasets adapted from the UCI repository on which we show that our proposed approaches can achieve an 11.6% improvement in precision and a 38% reduction in the measure of unfairness compared to the existing selection policy.
Learning Optimal and Fair Policies for Online Allocation of Scarce Societal Resources from Data Collected in Deployment
Nov 23, 2023We study the problem of allocating scarce societal resources of different types (e.g., permanent housing, deceased donor kidneys for transplantation, ventilators) to heterogeneous allocatees on a waitlist (e.g., people experiencing homelessness, individuals suffering from end-stage renal disease, Covid-19 patients) based on their observed covariates. We leverage administrative data collected in deployment to design an online policy that maximizes expected outcomes while satisfying budget constraints, in the long run. Our proposed policy waitlists each individual for the resource maximizing the difference between their estimated mean treatment outcome and the estimated resource dual-price or, roughly, the opportunity cost of using the resource. Resources are then allocated as they arrive, in a first-come first-serve fashion. We demonstrate that our data-driven policy almost surely asymptotically achieves the expected outcome of the optimal out-of-sample policy under mild technical assumptions. We extend our framework to incorporate various fairness constraints. We evaluate the performance of our approach on the problem of designing policies for allocating scarce housing resources to people experiencing homelessness in Los Angeles based on data from the homeless management information system. In particular, we show that using our policies improves rates of exit from homelessness by 1.9% and that policies that are fair in either allocation or outcomes by race come at a very low price of fairness.
Learning Optimal Classification Trees Robust to Distribution Shifts
Oct 26, 2023We consider the problem of learning classification trees that are robust to distribution shifts between training and testing/deployment data. This problem arises frequently in high stakes settings such as public health and social work where data is often collected using self-reported surveys which are highly sensitive to e.g., the framing of the questions, the time when and place where the survey is conducted, and the level of comfort the interviewee has in sharing information with the interviewer. We propose a method for learning optimal robust classification trees based on mixed-integer robust optimization technology. In particular, we demonstrate that the problem of learning an optimal robust tree can be cast as a single-stage mixed-integer robust optimization problem with a highly nonlinear and discontinuous objective. We reformulate this problem equivalently as a two-stage linear robust optimization problem for which we devise a tailored solution procedure based on constraint generation. We evaluate the performance of our approach on numerous publicly available datasets, and compare the performance to a regularized, non-robust optimal tree. We show an increase of up to 12.48% in worst-case accuracy and of up to 4.85% in average-case accuracy across several datasets and distribution shifts from using our robust solution in comparison to the non-robust one.
ODTlearn: A Package for Learning Optimal Decision Trees for Prediction and Prescription
Jul 28, 2023

ODTLearn is an open-source Python package that provides methods for learning optimal decision trees for high-stakes predictive and prescriptive tasks based on the mixed-integer optimization (MIO) framework proposed in Aghaei et al. (2019) and several of its extensions. The current version of the package provides implementations for learning optimal classification trees, optimal fair classification trees, optimal classification trees robust to distribution shifts, and optimal prescriptive trees from observational data. We have designed the package to be easy to maintain and extend as new optimal decision tree problem classes, reformulation strategies, and solution algorithms are introduced. To this end, the package follows object-oriented design principles and supports both commercial (Gurobi) and open source (COIN-OR branch and cut) solvers. The package documentation and an extensive user guide can be found at https://d3m-research-group.github.io/odtlearn/. Additionally, users can view the package source code and submit feature requests and bug reports by visiting https://github.com/D3M-Research-Group/odtlearn.
Deploying a Robust Active Preference Elicitation Algorithm: Experiment Design, Interface, and Evaluation for COVID-19 Patient Prioritization
Jun 06, 2023



Preference elicitation leverages AI or optimization to learn stakeholder preferences in settings ranging from marketing to public policy. The online robust preference elicitation procedure of arXiv:2003.01899 has been shown in simulation to outperform various other elicitation procedures in terms of effectively learning individuals' true utilities. However, as with any simulation, the method makes a series of assumptions that cannot easily be verified to hold true beyond simulation. Thus, we propose to validate the robust method's performance in deployment, focused on the particular challenge of selecting policies for prioritizing COVID-19 patients for scarce hospital resources during the pandemic. To this end, we develop an online platform for preference elicitation where users report their preferences between alternatives over a moderate number of pairwise comparisons chosen by a particular elicitation procedure. We recruit Amazon Mechanical Turk workers ($n$ = 193) to report their preferences and demonstrate that the robust method outperforms asking random queries by 21%, the next best performing method in the simulated results of arXiv:2003.01899, in terms of recommending policies with a higher utility.
Fairness in Contextual Resource Allocation Systems: Metrics and Incompatibility Results
Dec 04, 2022We study critical systems that allocate scarce resources to satisfy basic needs, such as homeless services that provide housing. These systems often support communities disproportionately affected by systemic racial, gender, or other injustices, so it is crucial to design these systems with fairness considerations in mind. To address this problem, we propose a framework for evaluating fairness in contextual resource allocation systems that is inspired by fairness metrics in machine learning. This framework can be applied to evaluate the fairness properties of a historical policy, as well as to impose constraints in the design of new (counterfactual) allocation policies. Our work culminates with a set of incompatibility results that investigate the interplay between the different fairness metrics we propose. Notably, we demonstrate that: 1) fairness in allocation and fairness in outcomes are usually incompatible; 2) policies that prioritize based on a vulnerability score will usually result in unequal outcomes across groups, even if the score is perfectly calibrated; 3) policies using contextual information beyond what is needed to characterize baseline risk and treatment effects can be fairer in their outcomes than those using just baseline risk and treatment effects; and 4) policies using group status in addition to baseline risk and treatment effects are as fair as possible given all available information. Our framework can help guide the discussion among stakeholders in deciding which fairness metrics to impose when allocating scarce resources.
Learning Resource Allocation Policies from Observational Data with an Application to Homeless Services Delivery
Jan 25, 2022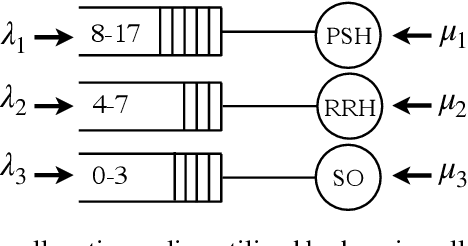
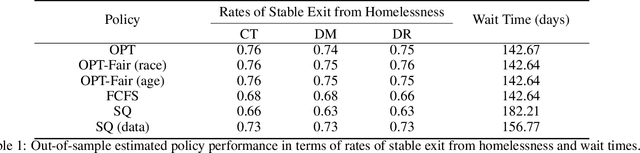
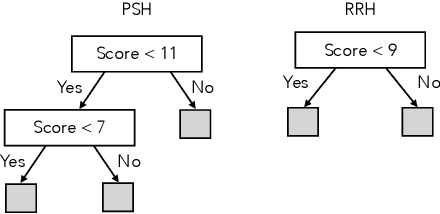
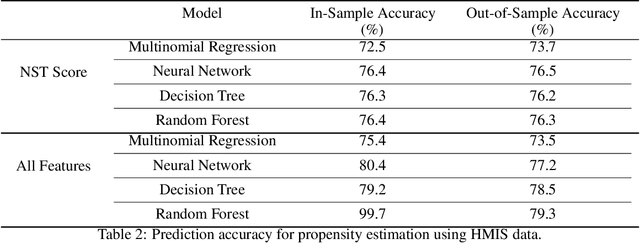
We study the problem of learning, from observational data, fair and interpretable policies that effectively match heterogeneous individuals to scarce resources of different types. We model this problem as a multi-class multi-server queuing system where both individuals and resources arrive stochastically over time. Each individual, upon arrival, is assigned to a queue where they wait to be matched to a resource. The resources are assigned in a first come first served (FCFS) fashion according to an eligibility structure that encodes the resource types that serve each queue. We propose a methodology based on techniques in modern causal inference to construct the individual queues as well as learn the matching outcomes and provide a mixed-integer optimization (MIO) formulation to optimize the eligibility structure. The MIO problem maximizes policy outcome subject to wait time and fairness constraints. It is very flexible, allowing for additional linear domain constraints. We conduct extensive analyses using synthetic and real-world data. In particular, we evaluate our framework using data from the U.S. Homeless Management Information System (HMIS). We obtain wait times as low as an FCFS policy while improving the rate of exit from homelessness for underserved or vulnerable groups (7% higher for the Black individuals and 15% higher for those below 17 years old) and overall.