 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClip-and-Verify: Linear Constraint-Driven Domain Clipping for Accelerating Neural Network Verification
Dec 11, 2025State-of-the-art neural network (NN) verifiers demonstrate that applying the branch-and-bound (BaB) procedure with fast bounding techniques plays a key role in tackling many challenging verification properties. In this work, we introduce the linear constraint-driven clipping framework, a class of scalable and efficient methods designed to enhance the efficacy of NN verifiers. Under this framework, we develop two novel algorithms that efficiently utilize linear constraints to 1) reduce portions of the input space that are either verified or irrelevant to a subproblem in the context of branch-and-bound, and 2) directly improve intermediate bounds throughout the network. The process novelly leverages linear constraints that often arise from bound propagation methods and is general enough to also incorporate constraints from other sources. It efficiently handles linear constraints using a specialized GPU procedure that can scale to large neural networks without the use of expensive external solvers. Our verification procedure, Clip-and-Verify, consistently tightens bounds across multiple benchmarks and can significantly reduce the number of subproblems handled during BaB. We show that our clipping algorithms can be integrated with BaB-based verifiers such as $α,β$-CROWN, utilizing either the split constraints in activation-space BaB or the output constraints that denote the unverified input space. We demonstrate the effectiveness of our procedure on a broad range of benchmarks where, in some instances, we witness a 96% reduction in the number of subproblems during branch-and-bound, and also achieve state-of-the-art verified accuracy across multiple benchmarks. Clip-and-Verify is part of the $α,β$-CROWN verifier (http://abcrown.org), the VNN-COMP 2025 winner. Code available at https://github.com/Verified-Intelligence/Clip_and_Verify.
DR-SAC: Distributionally Robust Soft Actor-Critic for Reinforcement Learning under Uncertainty
Jun 14, 2025Deep reinforcement learning (RL) has achieved significant success, yet its application in real-world scenarios is often hindered by a lack of robustness to environmental uncertainties. To solve this challenge, some robust RL algorithms have been proposed, but most are limited to tabular settings. In this work, we propose Distributionally Robust Soft Actor-Critic (DR-SAC), a novel algorithm designed to enhance the robustness of the state-of-the-art Soft Actor-Critic (SAC) algorithm. DR-SAC aims to maximize the expected value with entropy against the worst possible transition model lying in an uncertainty set. A distributionally robust version of the soft policy iteration is derived with a convergence guarantee. For settings where nominal distributions are unknown, such as offline RL, a generative modeling approach is proposed to estimate the required nominal distributions from data. Furthermore, experimental results on a range of continuous control benchmark tasks demonstrate our algorithm achieves up to $9.8$ times the average reward of the SAC baseline under common perturbations. Additionally, compared with existing robust reinforcement learning algorithms, DR-SAC significantly improves computing efficiency and applicability to large-scale problems.
Learning Fair Policies for Multi-stage Selection Problems from Observational Data
Dec 20, 2023We consider the problem of learning fair policies for multi-stage selection problems from observational data. This problem arises in several high-stakes domains such as company hiring, loan approval, or bail decisions where outcomes (e.g., career success, loan repayment, recidivism) are only observed for those selected. We propose a multi-stage framework that can be augmented with various fairness constraints, such as demographic parity or equal opportunity. This problem is a highly intractable infinite chance-constrained program involving the unknown joint distribution of covariates and outcomes. Motivated by the potential impact of selection decisions on people's lives and livelihoods, we propose to focus on interpretable linear selection rules. Leveraging tools from causal inference and sample average approximation, we obtain an asymptotically consistent solution to this selection problem by solving a mixed binary conic optimization problem, which can be solved using standard off-the-shelf solvers. We conduct extensive computational experiments on a variety of datasets adapted from the UCI repository on which we show that our proposed approaches can achieve an 11.6% improvement in precision and a 38% reduction in the measure of unfairness compared to the existing selection policy.
Wasserstein Robust Support Vector Machines with Fairness Constraints
Mar 11, 2021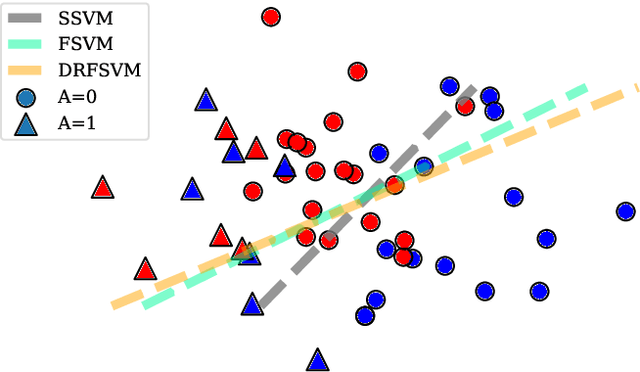

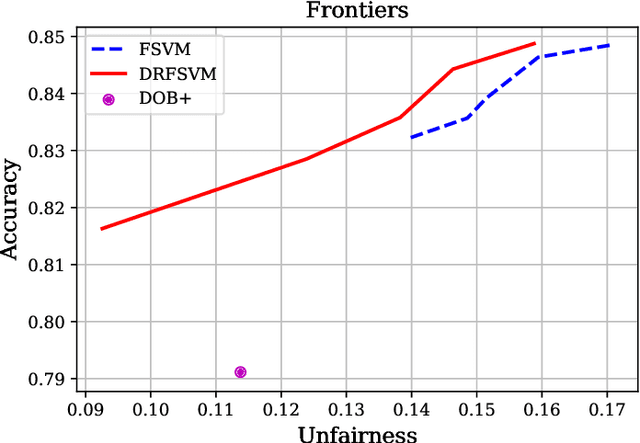
We propose a distributionally robust support vector machine with a fairness constraint that encourages the classifier to be fair in view of the equality of opportunity criterion. We use a type-$\infty$ Wasserstein ambiguity set centered at the empirical distribution to model distributional uncertainty and derive an exact reformulation for worst-case unfairness measure. We establish that the model is equivalent to a mixed-binary optimization problem, which can be solved by standard off-the-shelf solvers. We further prove that the expectation of the hinge loss objective function constitutes an upper bound on the misclassification probability. Finally, we numerically demonstrate that our proposed approach improves fairness with negligible loss of predictive accuracy.
A Robust Spectral Clustering Algorithm for Sub-Gaussian Mixture Models with Outliers
Jan 28, 2020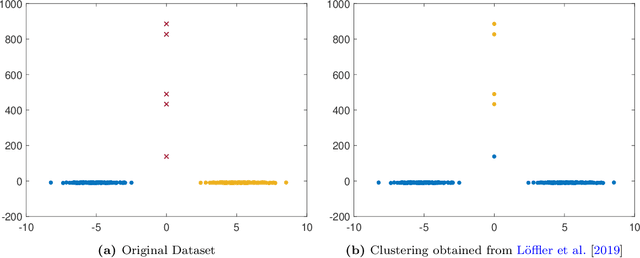


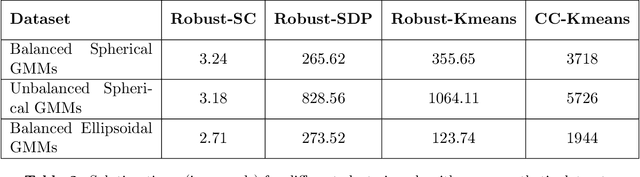
We consider the problem of clustering datasets in the presence of arbitrary outliers. Traditional clustering algorithms such as k-means and spectral clustering are known to perform poorly for datasets contaminated with even a small number of outliers. In this paper, we develop a provably robust spectral clustering algorithm that applies a simple rounding scheme to denoise a Gaussian kernel matrix built from the data points and uses vanilla spectral clustering to recover the cluster labels of data points. We analyze the performance of our algorithm under the assumption that the "good" data points are generated from a mixture of sub-gaussians (we term these "inliers"), while the outlier points can come from any arbitrary probability distribution. For this general class of models, we show that the asymptotic mis-classification error decays at an exponential rate in the signal-to-noise ratio, provided the number of outliers are a small fraction of the inlier points. Surprisingly, this derived error bound matches with the best-known bound for semidefinite programs (SDPs) under the same setting without outliers. We conduct extensive experiments on a variety of simulated and real-world datasets to demonstrate that our algorithm is less sensitive to outliers compared to other state-of-the-art algorithms proposed in the literature.