 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Ambulance Dispatch Under Contextual Travel-Time Uncertainty
May 22, 2026Ambulance response is time-critical in out-of-hospital cardiac arrest (OHCA), where dispatchers must balance timely arrivals with limited fleet capacity. Static territories and deterministic travel-time estimates are vulnerable to dynamic congestion, while always-dual dispatch adds redundancy but consumes fleet capacity. We propose IDEAL (Intelligent Dual dispatch of Emergency AmbuLances), a selective dual-dispatch framework that sends a second ambulance only when the optimistic gap between primary and secondary paths exceeds a threshold. IDEAL learns context-specific edge travel times from trip-level dispatch records, including unobserved routes, using a weakly supervised bilevel representation network. We train the nonsmooth model with mini-batch conservative gradients and prove an asymptotic convergence guarantee. IDEAL models uncertainty via Burg-divergence perturbations to a shared metric in the learned representation space, thereby inducing correlated changes in edge travel times and learning context-specific radii from historical underprediction errors. For real-time decisions, IDEAL casts optimistic-gap computation as a difference-of-convex program and derives an efficient oracle with complexity guarantees. In collaboration with the Hong Kong Fire Services Department, we evaluate IDEAL using historical OHCA records and real-time adaptive simulations. The results achieve a stronger response-time/resource trade-off relative to all region-based and Google-based baselines.
Provably Data-driven Lagrangian Relaxation for Mixed Integer Linear Programming
May 18, 2026Lagrangian Relaxation (LR) is a powerful technique for solving large-scale Mixed Integer Linear Programming (MILP), particularly those with decomposable structures, such as vehicle routing or unit commitment problems. By relaxing the coupling constraints, LR enables parallel subproblem solving and often yields tighter dual bounds than standard linear programming relaxations, which is crucial for efficient branch-and-bound pruning. While recent empirical work has shown promising results using machine learning to predict these multipliers, a theoretical understanding of such methods remains an open question. In this work, we bridge this gap by analyzing the problem of learning LR through the lens of Data-driven Algorithm Design, i.e., a statistical learning problem over a distribution of problem instances. Our contributions are as follows: first, we derive a generalization bound of $\mathcal{O}(s^{1.5}/\sqrt{N})$ for the learned multipliers, where $s$ is the number of coupling constraints and $N$ is the sample size. Second, we provide a minimax lower-bound of $Ω(s/\sqrt{N})$, proving that a linear dependency is unavoidable. Third, we constructively close this theoretical gap by proving that Stochastic Gradient Ascent (SGA) with averaging achieves the minimax optimal rate $Θ(s/\sqrt{N})$. Finally, we extend our framework to the learning-to-warm-start setting, proving that it achieves a fast, minimax-optimal rate of $Θ(s/N)$ and establishing a theoretical advantage over direct multiplier prediction.
Adaptive Rollout Allocation for Online Reinforcement Learning with Verifiable Rewards
Feb 03, 2026Sampling efficiency is a key bottleneck in reinforcement learning with verifiable rewards. Existing group-based policy optimization methods, such as GRPO, allocate a fixed number of rollouts for all training prompts. This uniform allocation implicitly treats all prompts as equally informative, and could lead to inefficient computational budget usage and impede training progress. We introduce VIP, a Variance-Informed Predictive allocation strategy that allocates a given rollout budget to the prompts in the incumbent batch to minimize the expected gradient variance of the policy update. At each iteration, VIP uses a lightweight Gaussian process model to predict per-prompt success probabilities based on recent rollouts. These probability predictions are translated into variance estimates, which are then fed into a convex optimization problem to determine the optimal rollout allocations under a hard compute budget constraint. Empirical results show that VIP consistently improves sampling efficiency and achieves higher performance than uniform or heuristic allocation strategies in multiple benchmarks.
Provably Data-driven Multiple Hyper-parameter Tuning with Structured Loss Function
Feb 02, 2026Data-driven algorithm design automates hyperparameter tuning, but its statistical foundations remain limited because model performance can depend on hyperparameters in implicit and highly non-smooth ways. Existing guarantees focus on the simple case of a one-dimensional (scalar) hyperparameter. This leaves the practically important, multi-dimensional hyperparameter tuning setting unresolved. We address this open question by establishing the first general framework for establishing generalization guarantees for tuning multi-dimensional hyperparameters in data-driven settings. Our approach strengthens the generalization guarantee framework for semi-algebraic function classes by exploiting tools from real algebraic geometry, yielding sharper, more broadly applicable guarantees. We then extend the analysis to hyperparameter tuning using the validation loss under minimal assumptions, and derive improved bounds when additional structure is available. Finally, we demonstrate the scope of the framework with new learnability results, including data-driven weighted group lasso and weighted fused lasso.
Exploring Diverse Generation Paths via Inference-time Stiefel Activation Steering
Jan 29, 2026Language models often default to a narrow set of high-probability outputs, leaving their generation paths homogeneous and prone to mode collapse. Sampling-based strategies inject randomness but still struggle to guarantee diversity across multiple concurrent generation runs. We address this limitation by introducing STARS ($\textbf{St}$iefel-based $\textbf{A}$ctivation Steering for Diverse $\textbf{R}$ea$\textbf{S}$oning), a training-free, inference-time intervention method that transforms activation steering into an exploration engine. At each token, STARS collects the hidden activations of concurrent generation runs and optimizes multiple additive steering directions jointly on the Stiefel manifold. STARS maximizes the geometric volume of the steered activations, while the Stiefel manifold induces orthogonality of the steering interventions. This formulation explicitly promotes divergent activation vectors of concurrent generation runs, and implicitly promotes divergent generation trajectories. This manifold optimization formulation can be solved using a Riemannian gradient descent algorithm with convergence guarantees, but this algorithm is too time-consuming for real-time inference. To guarantee low latency, we further design a lightweight one-step update with an aggressive, closed-form stepsize. For test case generation and scientific discovery benchmarks, STARS consistently outperforms standard sampling methods, achieving greater diversity without sacrificing qualitative performance.
SCOPE: Spectral Concentration by Distributionally Robust Joint Covariance-Precision Estimation
Nov 18, 2025We propose a distributionally robust formulation for simultaneously estimating the covariance matrix and the precision matrix of a random vector.The proposed model minimizes the worst-case weighted sum of the Frobenius loss of the covariance estimator and Stein's loss of the precision matrix estimator against all distributions from an ambiguity set centered at the nominal distribution. The radius of the ambiguity set is measured via convex spectral divergence. We demonstrate that the proposed distributionally robust estimation model can be reduced to a convex optimization problem, thereby yielding quasi-analytical estimators. The joint estimators are shown to be nonlinear shrinkage estimators. The eigenvalues of the estimators are shrunk nonlinearly towards a positive scalar, where the scalar is determined by the weight coefficient of the loss terms. By tuning the coefficient carefully, the shrinkage corrects the spectral bias of the empirical covariance/precision matrix estimator. By this property, we call the proposed joint estimator the Spectral concentrated COvariance and Precision matrix Estimator (SCOPE). We demonstrate that the shrinkage effect improves the condition number of the estimator. We provide a parameter-tuning scheme that adjusts the shrinkage target and intensity that is asymptotically optimal. Numerical experiments on synthetic and real data show that our shrinkage estimators perform competitively against state-of-the-art estimators in practical applications.
Test-time Diverse Reasoning by Riemannian Activation Steering
Nov 11, 2025



Best-of-$N$ reasoning improves the accuracy of language models in solving complex tasks by sampling multiple candidate solutions and then selecting the best one based on some criteria. A critical bottleneck for this strategy is the output diversity limit, which occurs when the model generates similar outputs despite stochastic sampling, and hence recites the same error. To address this lack of variance in reasoning paths, we propose a novel unsupervised activation steering strategy that simultaneously optimizes the steering vectors for multiple reasoning trajectories at test time. At any synchronization anchor along the batch generation process, we find the steering vectors that maximize the total volume spanned by all possible intervened activation subsets. We demonstrate that these steering vectors can be determined by solving a Riemannian optimization problem over the product of spheres with a log-determinant objective function. We then use a Riemannian block-coordinate descent algorithm with a well-tuned learning rate to obtain a stationary point of the problem, and we apply these steering vectors until the generation process reaches the subsequent synchronization anchor. Empirical evaluations on popular mathematical benchmarks demonstrate that our test-time Riemannian activation steering strategy outperforms vanilla sampling techniques in terms of generative diversity and solution accuracy.
Structured Pruning for Diverse Best-of-N Reasoning Optimization
Jun 09, 2025Model pruning in transformer-based language models, traditionally viewed as a means of achieving computational savings, can enhance the model's reasoning capabilities. In this work, we uncover a surprising phenomenon: the selective pruning of certain attention heads leads to improvements in reasoning performance, particularly on challenging tasks. Motivated by this observation, we propose SPRINT, a novel contrastive learning framework that dynamically selects the optimal head and layer to prune during inference. By aligning question embeddings with head embeddings, SPRINT identifies those pruned-head configurations that result in more accurate reasoning. Extensive experiments demonstrate that our method significantly outperforms traditional best-of-$N$ and random head selection strategies on the MATH500 and GSM8K datasets.
Mixture-of-Personas Language Models for Population Simulation
Apr 07, 2025


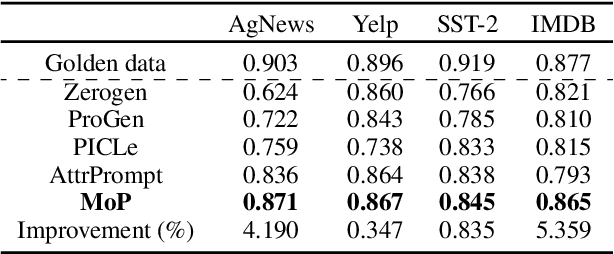
Advances in Large Language Models (LLMs) paved the way for their emerging applications in various domains, such as human behavior simulations, where LLMs could augment human-generated data in social science research and machine learning model training. However, pretrained LLMs often fail to capture the behavioral diversity of target populations due to the inherent variability across individuals and groups. To address this, we propose \textit{Mixture of Personas} (MoP), a \textit{probabilistic} prompting method that aligns the LLM responses with the target population. MoP is a contextual mixture model, where each component is an LM agent characterized by a persona and an exemplar representing subpopulation behaviors. The persona and exemplar are randomly chosen according to the learned mixing weights to elicit diverse LLM responses during simulation. MoP is flexible, requires no model finetuning, and is transferable across base models. Experiments for synthetic data generation show that MoP outperforms competing methods in alignment and diversity metrics.
Task-driven Layerwise Additive Activation Intervention
Feb 10, 2025



Modern language models (LMs) have significantly advanced generative modeling in natural language processing (NLP). Despite their success, LMs often struggle with adaptation to new contexts in real-time applications. A promising approach to task adaptation is activation intervention, which steers the LMs' generation process by identifying and manipulating the activations. However, existing interventions are highly dependent on heuristic rules or require many prompt inputs to determine effective interventions. This paper proposes a layer-wise additive activation intervention framework that optimizes the intervention process, thus enhancing the sample efficiency. We benchmark our framework on various datasets, demonstrating improvements in the accuracy of pre-trained LMs and competing intervention baselines.