 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRACE: Step-Level Benchmark for Faithful Reasoning over Context
Jun 15, 2026Many reasoning tasks require models to reason over input context, from document-grounded question answering to rule-based deduction. Chain-of-Thought (CoT) prompting produces traces that appear transparent, yet individual steps can silently deviate from the source evidence, even when the final answer is correct. Existing methods detect hallucinations at the response level but fail to identify where in the chain a failure occurs or what type it is. We introduce GRACE, the first human-annotated step-level faithfulness benchmark with a data-driven error taxonomy for context-grounded textual reasoning. GRACE covers CoT traces from 10 models across 4 source datasets, with each step annotated for faithfulness, error category, and natural language explanation. A data-driven taxonomy, discovered bottom-up via unsupervised clustering, organizes failures into two tracks: GRACE-Inference (deductive errors) and GRACE-Grounding (factual grounding errors), with four categories each. The evaluation set is human-annotated and challenging by design. Our experiments reveal substantial headroom for current models. In addition, integrating step-level faithfulness signals into reinforcement learning pipelines improves both downstream accuracy and reasoning reliability.
ByteRover: Agent-Native Memory Through LLM-Curated Hierarchical Context
Apr 02, 2026Memory-Augmented Generation (MAG) extends large language models with external memory to support long-context reasoning, but existing approaches universally treat memory as an external service that agents call into, delegating storage to separate pipelines of chunking, embedding, and graph extraction. This architectural separation means the system that stores knowledge does not understand it, leading to semantic drift between what the agent intended to remember and what the pipeline actually captured, loss of coordination context across agents, and fragile recovery after failures. In this paper, we propose ByteRover, an agent-native memory architecture that inverts the memory pipeline: the same LLM that reasons about a task also curates, structures, and retrieves knowledge. ByteRover represents knowledge in a hierarchical Context Tree, a file-based knowledge graph organized as Domain, Topic, Subtopic, and Entry, where each entry carries explicit relations, provenance, and an Adaptive Knowledge Lifecycle (AKL) with importance scoring, maturity tiers, and recency decay. Retrieval uses a 5-tier progressive strategy that resolves most queries at sub-100 ms latency without LLM calls, escalating to agentic reasoning only for novel questions. Experiments on LoCoMo and LongMemEval demonstrate that ByteRover achieves state-of-the-art accuracy on LoCoMo and competitive results on LongMemEval while requiring zero external infrastructure, no vector database, no graph database, no embedding service, with all knowledge stored as human-readable markdown files on the local filesystem.
Pruning at Initialisation through the lens of Graphon Limit: Convergence, Expressivity, and Generalisation
Feb 06, 2026Pruning at Initialisation methods discover sparse, trainable subnetworks before training, but their theoretical mechanisms remain elusive. Existing analyses are often limited to finite-width statistics, lacking a rigorous characterisation of the global sparsity patterns that emerge as networks grow large. In this work, we connect discrete pruning heuristics to graph limit theory via graphons, establishing the graphon limit of PaI masks. We introduce a Factorised Saliency Model that encompasses popular pruning criteria and prove that, under regularity conditions, the discrete masks generated by these algorithms converge to deterministic bipartite graphons. This limit framework establishes a novel topological taxonomy for sparse networks: while unstructured methods (e.g., Random, Magnitude) converge to homogeneous graphons representing uniform connectivity, data-driven methods (e.g., SNIP, GraSP) converge to heterogeneous graphons that encode implicit feature selection. Leveraging this continuous characterisation, we derive two fundamental theoretical results: (i) a Universal Approximation Theorem for sparse networks that depends only on the intrinsic dimension of active coordinate subspaces; and (ii) a Graphon-NTK generalisation bound demonstrating how the limit graphon modulates the kernel geometry to align with informative features. Our results transform the study of sparse neural networks from combinatorial graph problems into a rigorous framework of continuous operators, offering a new mechanism for analysing expressivity and generalisation in sparse neural networks.
Verify-in-the-Graph: Entity Disambiguation Enhancement for Complex Claim Verification with Interactive Graph Representation
May 29, 2025Claim verification is a long-standing and challenging task that demands not only high accuracy but also explainability of the verification process. This task becomes an emerging research issue in the era of large language models (LLMs) since real-world claims are often complex, featuring intricate semantic structures or obfuscated entities. Traditional approaches typically address this by decomposing claims into sub-claims and querying a knowledge base to resolve hidden or ambiguous entities. However, the absence of effective disambiguation strategies for these entities can compromise the entire verification process. To address these challenges, we propose Verify-in-the-Graph (VeGraph), a novel framework leveraging the reasoning and comprehension abilities of LLM agents. VeGraph operates in three phases: (1) Graph Representation - an input claim is decomposed into structured triplets, forming a graph-based representation that integrates both structured and unstructured information; (2) Entity Disambiguation -VeGraph iteratively interacts with the knowledge base to resolve ambiguous entities within the graph for deeper sub-claim verification; and (3) Verification - remaining triplets are verified to complete the fact-checking process. Experiments using Meta-Llama-3-70B (instruct version) show that VeGraph achieves competitive performance compared to baselines on two benchmarks HoVer and FEVEROUS, effectively addressing claim verification challenges. Our source code and data are available for further exploitation.
* Published at NAACL 2025 Main Conference
Agent-UniRAG: A Trainable Open-Source LLM Agent Framework for Unified Retrieval-Augmented Generation Systems
May 29, 2025This paper presents a novel approach for unified retrieval-augmented generation (RAG) systems using the recent emerging large language model (LLM) agent concept. Specifically, Agent LLM, which utilizes LLM as fundamental controllers, has become a promising approach to enable the interpretability of RAG tasks, especially for complex reasoning question-answering systems (e.g., multi-hop queries). Nonetheless, previous works mainly focus on solving RAG systems with either single-hop or multi-hop approaches separately, which limits the application of those approaches to real-world applications. In this study, we propose a trainable agent framework called Agent-UniRAG for unified retrieval-augmented LLM systems, which enhances the effectiveness and interpretability of RAG systems. The main idea is to design an LLM agent framework to solve RAG tasks step-by-step based on the complexity of the inputs, simultaneously including single-hop and multi-hop queries in an end-to-end manner. Furthermore, we introduce SynAgent-RAG, a synthetic dataset to enable the proposed agent framework for small open-source LLMs (e.g., Llama-3-8B). The results show comparable performances with closed-source and larger open-source LLMs across various RAG benchmarks. Our source code and dataset are publicly available for further exploitation.
ClaimPKG: Enhancing Claim Verification via Pseudo-Subgraph Generation with Lightweight Specialized LLM
May 28, 2025Integrating knowledge graphs (KGs) to enhance the reasoning capabilities of large language models (LLMs) is an emerging research challenge in claim verification. While KGs provide structured, semantically rich representations well-suited for reasoning, most existing verification methods rely on unstructured text corpora, limiting their ability to effectively leverage KGs. Additionally, despite possessing strong reasoning abilities, modern LLMs struggle with multi-step modular pipelines and reasoning over KGs without adaptation. To address these challenges, we propose ClaimPKG, an end-to-end framework that seamlessly integrates LLM reasoning with structured knowledge from KGs. Specifically, the main idea of ClaimPKG is to employ a lightweight, specialized LLM to represent the input claim as pseudo-subgraphs, guiding a dedicated subgraph retrieval module to identify relevant KG subgraphs. These retrieved subgraphs are then processed by a general-purpose LLM to produce the final verdict and justification. Extensive experiments on the FactKG dataset demonstrate that ClaimPKG achieves state-of-the-art performance, outperforming strong baselines in this research field by 9%-12% accuracy points across multiple categories. Furthermore, ClaimPKG exhibits zero-shot generalizability to unstructured datasets such as HoVer and FEVEROUS, effectively combining structured knowledge from KGs with LLM reasoning across various LLM backbones.
* Accepted by ACL 2025 findings
Flatness-aware Sequential Learning Generates Resilient Backdoors
Jul 20, 2024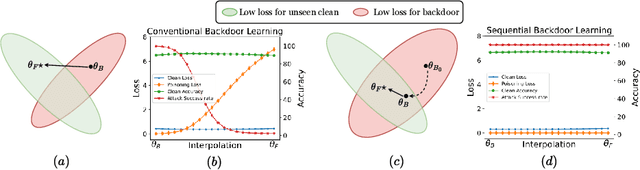
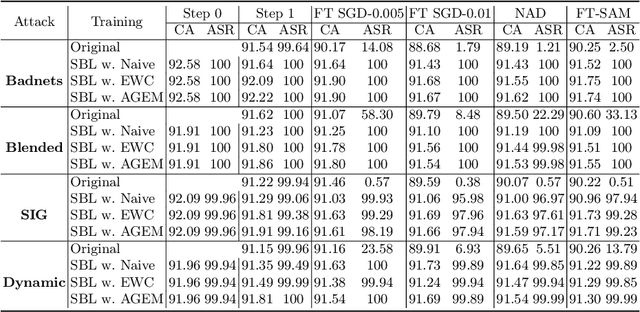
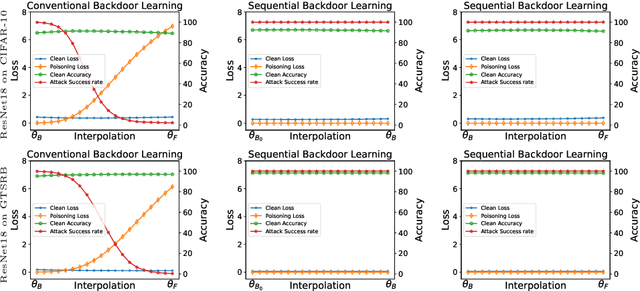
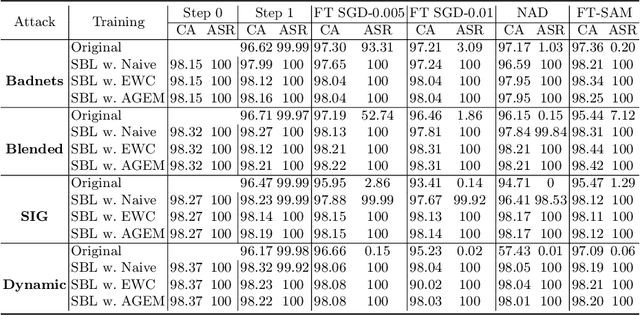
Recently, backdoor attacks have become an emerging threat to the security of machine learning models. From the adversary's perspective, the implanted backdoors should be resistant to defensive algorithms, but some recently proposed fine-tuning defenses can remove these backdoors with notable efficacy. This is mainly due to the catastrophic forgetting (CF) property of deep neural networks. This paper counters CF of backdoors by leveraging continual learning (CL) techniques. We begin by investigating the connectivity between a backdoored and fine-tuned model in the loss landscape. Our analysis confirms that fine-tuning defenses, especially the more advanced ones, can easily push a poisoned model out of the backdoor regions, making it forget all about the backdoors. Based on this finding, we re-formulate backdoor training through the lens of CL and propose a novel framework, named Sequential Backdoor Learning (SBL), that can generate resilient backdoors. This framework separates the backdoor poisoning process into two tasks: the first task learns a backdoored model, while the second task, based on the CL principles, moves it to a backdoored region resistant to fine-tuning. We additionally propose to seek flatter backdoor regions via a sharpness-aware minimizer in the framework, further strengthening the durability of the implanted backdoor. Finally, we demonstrate the effectiveness of our method through extensive empirical experiments on several benchmark datasets in the backdoor domain. The source code is available at https://github.com/mail-research/SBL-resilient-backdoors
Forget but Recall: Incremental Latent Rectification in Continual Learning
Jun 25, 2024



Intrinsic capability to continuously learn a changing data stream is a desideratum of deep neural networks (DNNs). However, current DNNs suffer from catastrophic forgetting, which hinders remembering past knowledge. To mitigate this issue, existing Continual Learning (CL) approaches either retain exemplars for replay, regularize learning, or allocate dedicated capacity for new tasks. This paper investigates an unexplored CL direction for incremental learning called Incremental Latent Rectification or ILR. In a nutshell, ILR learns to propagate with correction (or rectify) the representation from the current trained DNN backward to the representation space of the old task, where performing predictive decisions is easier. This rectification process only employs a chain of small representation mapping networks, called rectifier units. Empirical experiments on several continual learning benchmarks, including CIFAR10, CIFAR100, and Tiny ImageNet, demonstrate the effectiveness and potential of this novel CL direction compared to existing representative CL methods.