 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Rollout Allocation for Online Reinforcement Learning with Verifiable Rewards
Feb 03, 2026Sampling efficiency is a key bottleneck in reinforcement learning with verifiable rewards. Existing group-based policy optimization methods, such as GRPO, allocate a fixed number of rollouts for all training prompts. This uniform allocation implicitly treats all prompts as equally informative, and could lead to inefficient computational budget usage and impede training progress. We introduce VIP, a Variance-Informed Predictive allocation strategy that allocates a given rollout budget to the prompts in the incumbent batch to minimize the expected gradient variance of the policy update. At each iteration, VIP uses a lightweight Gaussian process model to predict per-prompt success probabilities based on recent rollouts. These probability predictions are translated into variance estimates, which are then fed into a convex optimization problem to determine the optimal rollout allocations under a hard compute budget constraint. Empirical results show that VIP consistently improves sampling efficiency and achieves higher performance than uniform or heuristic allocation strategies in multiple benchmarks.
Structured Pruning for Diverse Best-of-N Reasoning Optimization
Jun 09, 2025Model pruning in transformer-based language models, traditionally viewed as a means of achieving computational savings, can enhance the model's reasoning capabilities. In this work, we uncover a surprising phenomenon: the selective pruning of certain attention heads leads to improvements in reasoning performance, particularly on challenging tasks. Motivated by this observation, we propose SPRINT, a novel contrastive learning framework that dynamically selects the optimal head and layer to prune during inference. By aligning question embeddings with head embeddings, SPRINT identifies those pruned-head configurations that result in more accurate reasoning. Extensive experiments demonstrate that our method significantly outperforms traditional best-of-$N$ and random head selection strategies on the MATH500 and GSM8K datasets.
Dynamic Context-Aware Streaming Pretrained Language Model For Inverse Text Normalization
May 30, 2025Inverse Text Normalization (ITN) is crucial for converting spoken Automatic Speech Recognition (ASR) outputs into well-formatted written text, enhancing both readability and usability. Despite its importance, the integration of streaming ITN within streaming ASR remains largely unexplored due to challenges in accuracy, efficiency, and adaptability, particularly in low-resource and limited-context scenarios. In this paper, we introduce a streaming pretrained language model for ITN, leveraging pretrained linguistic representations for improved robustness. To address streaming constraints, we propose Dynamic Context-Aware during training and inference, enabling adaptive chunk size adjustments and the integration of right-context information. Experimental results demonstrate that our method achieves accuracy comparable to non-streaming ITN and surpasses existing streaming ITN models on a Vietnamese dataset, all while maintaining low latency, ensuring seamless integration into ASR systems.
Task-driven Layerwise Additive Activation Intervention
Feb 10, 2025



Modern language models (LMs) have significantly advanced generative modeling in natural language processing (NLP). Despite their success, LMs often struggle with adaptation to new contexts in real-time applications. A promising approach to task adaptation is activation intervention, which steers the LMs' generation process by identifying and manipulating the activations. However, existing interventions are highly dependent on heuristic rules or require many prompt inputs to determine effective interventions. This paper proposes a layer-wise additive activation intervention framework that optimizes the intervention process, thus enhancing the sample efficiency. We benchmark our framework on various datasets, demonstrating improvements in the accuracy of pre-trained LMs and competing intervention baselines.
Probe-Free Low-Rank Activation Intervention
Feb 06, 2025



Language models (LMs) can produce texts that appear accurate and coherent but contain untruthful or toxic content. Inference-time interventions that edit the hidden activations have shown promising results in steering the LMs towards desirable generations. Existing activation intervention methods often comprise an activation probe to detect undesirable generation, triggering the activation modification to steer subsequent generation. This paper proposes a probe-free intervention method FLORAIN for all attention heads in a specific activation layer. It eliminates the need to train classifiers for probing purposes. The intervention function is parametrized by a sample-wise nonlinear low-rank mapping, which is trained by minimizing the distance between the modified activations and their projection onto the manifold of desirable content. Under specific constructions of the manifold and projection distance, we show that the intervention strategy can be computed efficiently by solving a smooth optimization problem. The empirical results, benchmarked on multiple base models, demonstrate that FLORAIN consistently outperforms several baseline methods in enhancing model truthfulness and quality across generation and multiple-choice tasks.
Risk-Aware Distributional Intervention Policies for Language Models
Jan 27, 2025Language models are prone to occasionally undesirable generations, such as harmful or toxic content, despite their impressive capability to produce texts that appear accurate and coherent. This paper presents a new two-stage approach to detect and mitigate undesirable content generations by rectifying activations. First, we train an ensemble of layerwise classifiers to detect undesirable content using activations by minimizing a smooth surrogate of the risk-aware score. Then, for contents that are detected as undesirable, we propose layerwise distributional intervention policies that perturb the attention heads minimally while guaranteeing probabilistically the effectiveness of the intervention. Benchmarks on several language models and datasets show that our method outperforms baselines in reducing the generation of undesirable output.
Multi-agent reinforcement learning strategy to maximize the lifetime of Wireless Rechargeable
Nov 21, 2024The thesis proposes a generalized charging framework for multiple mobile chargers to maximize the network lifetime and ensure target coverage and connectivity in large scale WRSNs. Moreover, a multi-point charging model is leveraged to enhance charging efficiency, where the MC can charge multiple sensors simultaneously at each charging location. The thesis proposes an effective Decentralized Partially Observable Semi-Markov Decision Process (Dec POSMDP) model that promotes Mobile Chargers (MCs) cooperation and detects optimal charging locations based on realtime network information. Furthermore, the proposal allows reinforcement algorithms to be applied to different networks without requiring extensive retraining. To solve the Dec POSMDP model, the thesis proposes an Asynchronous Multi Agent Reinforcement Learning algorithm (AMAPPO) based on the Proximal Policy Optimization algorithm (PPO).
Generative Conditional Distributions by Neural (Entropic) Optimal Transport
Jun 04, 2024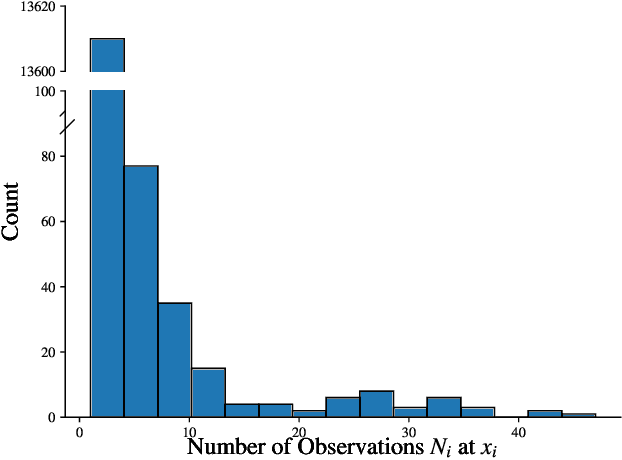
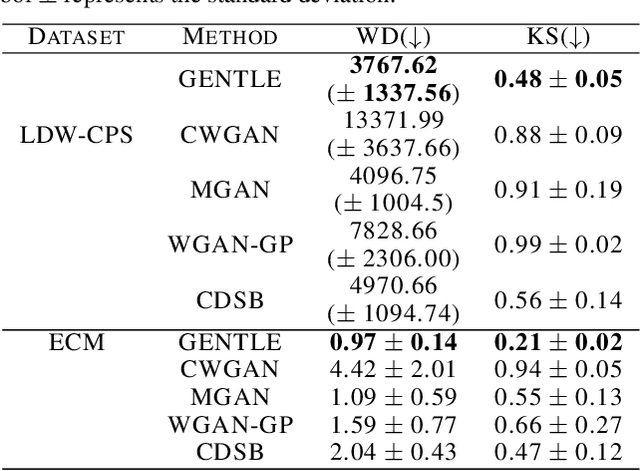
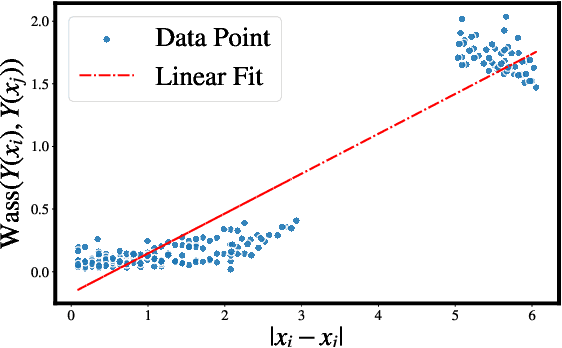
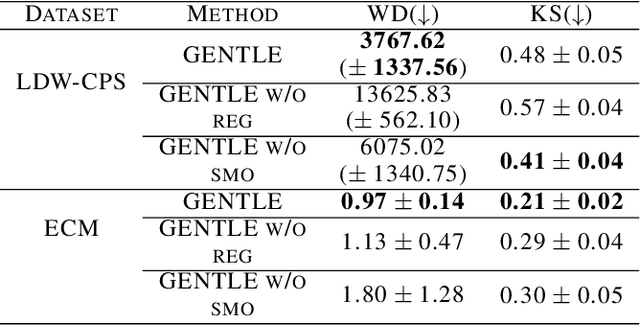
Learning conditional distributions is challenging because the desired outcome is not a single distribution but multiple distributions that correspond to multiple instances of the covariates. We introduce a novel neural entropic optimal transport method designed to effectively learn generative models of conditional distributions, particularly in scenarios characterized by limited sample sizes. Our method relies on the minimax training of two neural networks: a generative network parametrizing the inverse cumulative distribution functions of the conditional distributions and another network parametrizing the conditional Kantorovich potential. To prevent overfitting, we regularize the objective function by penalizing the Lipschitz constant of the network output. Our experiments on real-world datasets show the effectiveness of our algorithm compared to state-of-the-art conditional distribution learning techniques. Our implementation can be found at https://github.com/nguyenngocbaocmt02/GENTLE.
Sheaf HyperNetworks for Personalized Federated Learning
May 31, 2024



Graph hypernetworks (GHNs), constructed by combining graph neural networks (GNNs) with hypernetworks (HNs), leverage relational data across various domains such as neural architecture search, molecular property prediction and federated learning. Despite GNNs and HNs being individually successful, we show that GHNs present problems compromising their performance, such as over-smoothing and heterophily. Moreover, we cannot apply GHNs directly to personalized federated learning (PFL) scenarios, where a priori client relation graph may be absent, private, or inaccessible. To mitigate these limitations in the context of PFL, we propose a novel class of HNs, sheaf hypernetworks (SHNs), which combine cellular sheaf theory with HNs to improve parameter sharing for PFL. We thoroughly evaluate SHNs across diverse PFL tasks, including multi-class classification, traffic and weather forecasting. Additionally, we provide a methodology for constructing client relation graphs in scenarios where such graphs are unavailable. We show that SHNs consistently outperform existing PFL solutions in complex non-IID scenarios. While the baselines' performance fluctuates depending on the task, SHNs show improvements of up to 2.7% in accuracy and 5.3% in lower mean squared error over the best-performing baseline.
Cost-Adaptive Recourse Recommendation by Adaptive Preference Elicitation
Feb 23, 2024



Algorithmic recourse recommends a cost-efficient action to a subject to reverse an unfavorable machine learning classification decision. Most existing methods in the literature generate recourse under the assumption of complete knowledge about the cost function. In real-world practice, subjects could have distinct preferences, leading to incomplete information about the underlying cost function of the subject. This paper proposes a two-step approach integrating preference learning into the recourse generation problem. In the first step, we design a question-answering framework to refine the confidence set of the Mahalanobis matrix cost of the subject sequentially. Then, we generate recourse by utilizing two methods: gradient-based and graph-based cost-adaptive recourse that ensures validity while considering the whole confidence set of the cost matrix. The numerical evaluation demonstrates the benefits of our approach over state-of-the-art baselines in delivering cost-efficient recourse recommendations.