 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontierOR: Benchmarking LLMs' Capacity for Efficient Algorithm Design in Large-Scale Optimization
May 26, 2026Large language models (LLMs) are increasingly used for optimization modeling and solver-code generation, yet practical operations research and optimization problems often require a harder capability: designing scalable algorithms that exploit problem structure and outperform direct formulation-and-solve baselines. Existing benchmarks are limited to small or simplified examples far below real-world scale and complexity. We introduce FrontierOR, among the first benchmarks to systematically evaluate LLM-based efficient algorithm design for realistic large-scale optimization problems. FrontierOR includes 180 tasks derived from methodologically diverse papers published in top-tier operations research venues, each with standardized instances and a hidden, expert-verified evaluation suite. We evaluate seven LLMs spanning frontier, cost-effective, and open-source models both in one-shot and test-time evolution settings. The results reveal that frontier models still struggle to move from executable formulations to efficient optimization algorithms: the strongest one-shot model outperforms Gurobi in only 31% of cases in both solution quality and computational efficiency, and even strong coding agents with test-time evolution achieve only 50% on selected hard tasks. FrontierOR establishes a practical evaluation platform for LLM-based optimization algorithm design, which enables future LLMs and agents to be systematically tested on whether they can move beyond correct formulation toward a feasible, high-quality, and efficient algorithm.
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Apr 26, 2026Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Apr 02, 2026Large language model (LLM)-based evolution is a promising approach for open-ended discovery, where progress requires sustained search and knowledge accumulation. Existing methods still rely heavily on fixed heuristics and hard-coded exploration rules, which limit the autonomy of LLM agents. We present CORAL, the first framework for autonomous multi-agent evolution on open-ended problems. CORAL replaces rigid control with long-running agents that explore, reflect, and collaborate through shared persistent memory, asynchronous multi-agent execution, and heartbeat-based interventions. It also provides practical safeguards, including isolated workspaces, evaluator separation, resource management, and agent session and health management. Evaluated on diverse mathematical, algorithmic, and systems optimization tasks, CORAL sets new state-of-the-art results on 10 tasks, achieving 3-10 times higher improvement rates with far fewer evaluations than fixed evolutionary search baselines across tasks. On Anthropic's kernel engineering task, four co-evolving agents improve the best known score from 1363 to 1103 cycles. Mechanistic analyses further show how these gains arise from knowledge reuse and multi-agent exploration and communication. Together, these results suggest that greater agent autonomy and multi-agent evolution can substantially improve open-ended discovery. Code is available at https://github.com/Human-Agent-Society/CORAL.
Probe-Free Low-Rank Activation Intervention
Feb 06, 2025



Language models (LMs) can produce texts that appear accurate and coherent but contain untruthful or toxic content. Inference-time interventions that edit the hidden activations have shown promising results in steering the LMs towards desirable generations. Existing activation intervention methods often comprise an activation probe to detect undesirable generation, triggering the activation modification to steer subsequent generation. This paper proposes a probe-free intervention method FLORAIN for all attention heads in a specific activation layer. It eliminates the need to train classifiers for probing purposes. The intervention function is parametrized by a sample-wise nonlinear low-rank mapping, which is trained by minimizing the distance between the modified activations and their projection onto the manifold of desirable content. Under specific constructions of the manifold and projection distance, we show that the intervention strategy can be computed efficiently by solving a smooth optimization problem. The empirical results, benchmarked on multiple base models, demonstrate that FLORAIN consistently outperforms several baseline methods in enhancing model truthfulness and quality across generation and multiple-choice tasks.
GETS: Ensemble Temperature Scaling for Calibration in Graph Neural Networks
Oct 12, 2024



Graph Neural Networks deliver strong classification results but often suffer from poor calibration performance, leading to overconfidence or underconfidence. This is particularly problematic in high stakes applications where accurate uncertainty estimates are essential. Existing post hoc methods, such as temperature scaling, fail to effectively utilize graph structures, while current GNN calibration methods often overlook the potential of leveraging diverse input information and model ensembles jointly. In the paper, we propose Graph Ensemble Temperature Scaling, a novel calibration framework that combines input and model ensemble strategies within a Graph Mixture of Experts archi SOTA calibration techniques, reducing expected calibration error by 25 percent across 10 GNN benchmark datasets. Additionally, GETS is computationally efficient, scalable, and capable of selecting effective input combinations for improved calibration performance.
On the Estimation Performance of Generalized Power Method for Heteroscedastic Probabilistic PCA
Dec 06, 2023The heteroscedastic probabilistic principal component analysis (PCA) technique, a variant of the classic PCA that considers data heterogeneity, is receiving more and more attention in the data science and signal processing communities. In this paper, to estimate the underlying low-dimensional linear subspace (simply called \emph{ground truth}) from available heterogeneous data samples, we consider the associated non-convex maximum-likelihood estimation problem, which involves maximizing a sum of heterogeneous quadratic forms over an orthogonality constraint (HQPOC). We propose a first-order method -- generalized power method (GPM) -- to tackle the problem and establish its \emph{estimation performance} guarantee. Specifically, we show that, given a suitable initialization, the distances between the iterates generated by GPM and the ground truth decrease at least geometrically to some threshold associated with the residual part of certain "population-residual decomposition". In establishing the estimation performance result, we prove a novel local error bound property of another closely related optimization problem, namely quadratic optimization with orthogonality constraint (QPOC), which is new and can be of independent interest. Numerical experiments are conducted to demonstrate the superior performance of GPM in both Gaussian noise and sub-Gaussian noise settings.
Foundation Model is Efficient Multimodal Multitask Model Selector
Aug 11, 2023
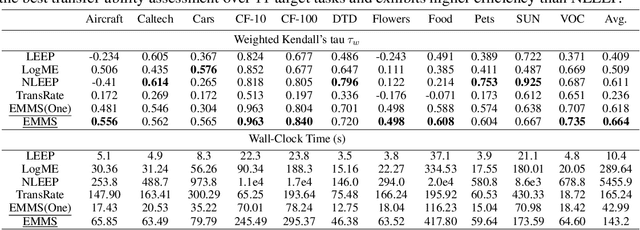
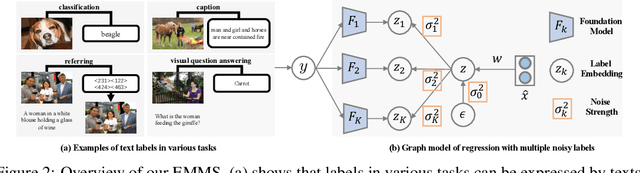
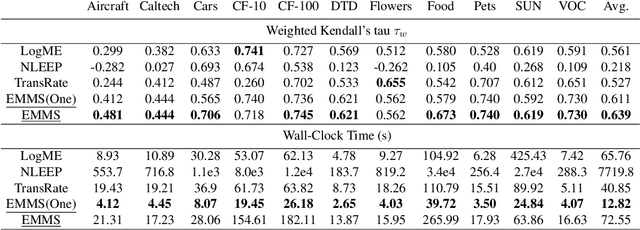
This paper investigates an under-explored but important problem: given a collection of pre-trained neural networks, predicting their performance on each multi-modal task without fine-tuning them, such as image recognition, referring, captioning, visual question answering, and text question answering. A brute-force approach is to finetune all models on all target datasets, bringing high computational costs. Although recent-advanced approaches employed lightweight metrics to measure models' transferability,they often depend heavily on the prior knowledge of a single task, making them inapplicable in a multi-modal multi-task scenario. To tackle this issue, we propose an efficient multi-task model selector (EMMS), which employs large-scale foundation models to transform diverse label formats such as categories, texts, and bounding boxes of different downstream tasks into a unified noisy label embedding. EMMS can estimate a model's transferability through a simple weighted linear regression, which can be efficiently solved by an alternating minimization algorithm with a convergence guarantee. Extensive experiments on 5 downstream tasks with 24 datasets show that EMMS is fast, effective, and generic enough to assess the transferability of pre-trained models, making it the first model selection method in the multi-task scenario. For instance, compared with the state-of-the-art method LogME enhanced by our label embeddings, EMMS achieves 9.0\%, 26.3\%, 20.1\%, 54.8\%, 12.2\% performance gain on image recognition, referring, captioning, visual question answering, and text question answering, while bringing 5.13x, 6.29x, 3.59x, 6.19x, and 5.66x speedup in wall-clock time, respectively. The code is available at https://github.com/OpenGVLab/Multitask-Model-Selector.