 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model is Efficient Multimodal Multitask Model Selector
Aug 11, 2023
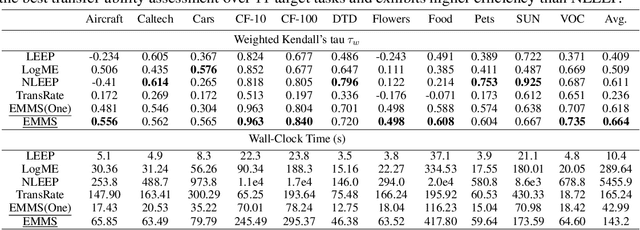
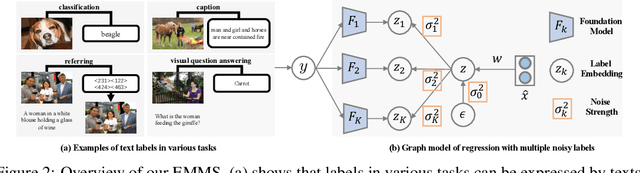
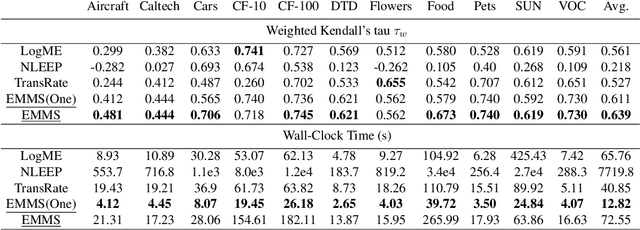
This paper investigates an under-explored but important problem: given a collection of pre-trained neural networks, predicting their performance on each multi-modal task without fine-tuning them, such as image recognition, referring, captioning, visual question answering, and text question answering. A brute-force approach is to finetune all models on all target datasets, bringing high computational costs. Although recent-advanced approaches employed lightweight metrics to measure models' transferability,they often depend heavily on the prior knowledge of a single task, making them inapplicable in a multi-modal multi-task scenario. To tackle this issue, we propose an efficient multi-task model selector (EMMS), which employs large-scale foundation models to transform diverse label formats such as categories, texts, and bounding boxes of different downstream tasks into a unified noisy label embedding. EMMS can estimate a model's transferability through a simple weighted linear regression, which can be efficiently solved by an alternating minimization algorithm with a convergence guarantee. Extensive experiments on 5 downstream tasks with 24 datasets show that EMMS is fast, effective, and generic enough to assess the transferability of pre-trained models, making it the first model selection method in the multi-task scenario. For instance, compared with the state-of-the-art method LogME enhanced by our label embeddings, EMMS achieves 9.0\%, 26.3\%, 20.1\%, 54.8\%, 12.2\% performance gain on image recognition, referring, captioning, visual question answering, and text question answering, while bringing 5.13x, 6.29x, 3.59x, 6.19x, and 5.66x speedup in wall-clock time, respectively. The code is available at https://github.com/OpenGVLab/Multitask-Model-Selector.
Multi-Stage Spatio-Temporal Aggregation Transformer for Video Person Re-identification
Jan 02, 2023



In recent years, the Transformer architecture has shown its superiority in the video-based person re-identification task. Inspired by video representation learning, these methods mainly focus on designing modules to extract informative spatial and temporal features. However, they are still limited in extracting local attributes and global identity information, which are critical for the person re-identification task. In this paper, we propose a novel Multi-Stage Spatial-Temporal Aggregation Transformer (MSTAT) with two novel designed proxy embedding modules to address the above issue. Specifically, MSTAT consists of three stages to encode the attribute-associated, the identity-associated, and the attribute-identity-associated information from the video clips, respectively, achieving the holistic perception of the input person. We combine the outputs of all the stages for the final identification. In practice, to save the computational cost, the Spatial-Temporal Aggregation (STA) modules are first adopted in each stage to conduct the self-attention operations along the spatial and temporal dimensions separately. We further introduce the Attribute-Aware and Identity-Aware Proxy embedding modules (AAP and IAP) to extract the informative and discriminative feature representations at different stages. All of them are realized by employing newly designed self-attention operations with specific meanings. Moreover, temporal patch shuffling is also introduced to further improve the robustness of the model. Extensive experimental results demonstrate the effectiveness of the proposed modules in extracting the informative and discriminative information from the videos, and illustrate the MSTAT can achieve state-of-the-art accuracies on various standard benchmarks.
Active Domain Adaptation with Multi-level Contrastive Units for Semantic Segmentation
May 25, 2022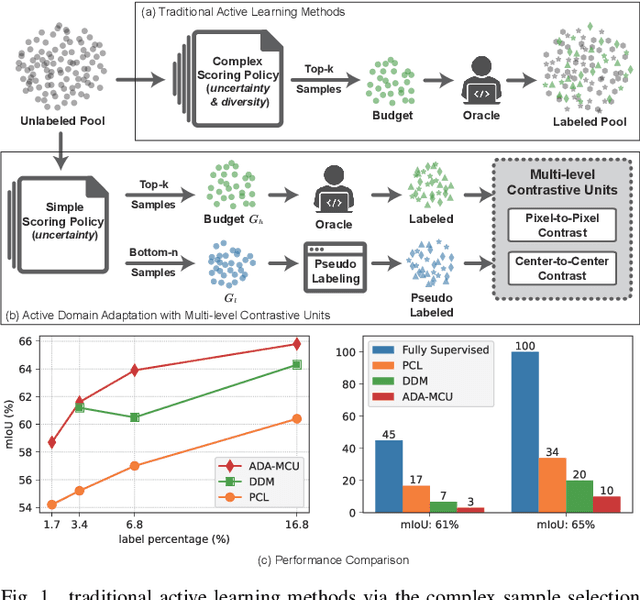
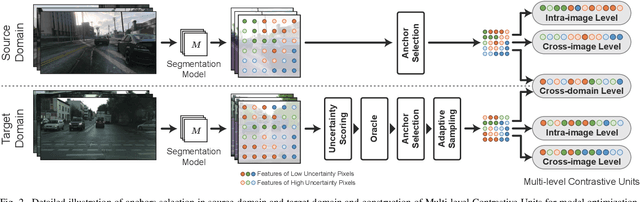
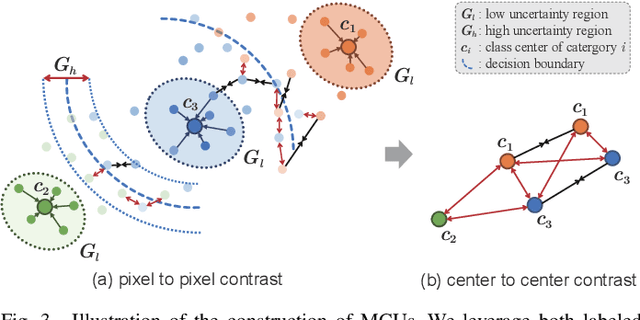
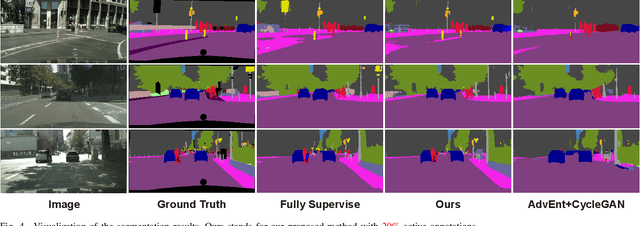
To further reduce the cost of semi-supervised domain adaptation (SSDA) labeling, a more effective way is to use active learning (AL) to annotate a selected subset with specific properties. However, domain adaptation tasks are always addressed in two interactive aspects: domain transfer and the enhancement of discrimination, which requires the selected data to be both uncertain under the model and diverse in feature space. Contrary to active learning in classification tasks, it is usually challenging to select pixels that contain both the above properties in segmentation tasks, leading to the complex design of pixel selection strategy. To address such an issue, we propose a novel Active Domain Adaptation scheme with Multi-level Contrastive Units (ADA-MCU) for semantic image segmentation. A simple pixel selection strategy followed with the construction of multi-level contrastive units is introduced to optimize the model for both domain adaptation and active supervised learning. In practice, MCUs are constructed from intra-image, cross-image, and cross-domain levels by using both labeled and unlabeled pixels. At each level, we define contrastive losses from center-to-center and pixel-to-pixel manners, with the aim of jointly aligning the category centers and reducing outliers near the decision boundaries. In addition, we also introduce a categories correlation matrix to implicitly describe the relationship between categories, which are used to adjust the weights of the losses for MCUs. Extensive experimental results on standard benchmarks show that the proposed method achieves competitive performance against state-of-the-art SSDA methods with 50% fewer labeled pixels and significantly outperforms state-of-the-art with a large margin by using the same level of annotation cost.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
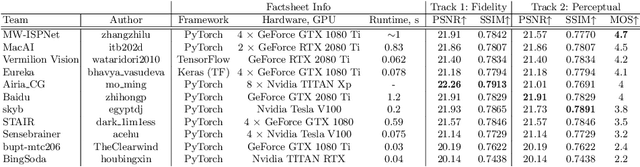
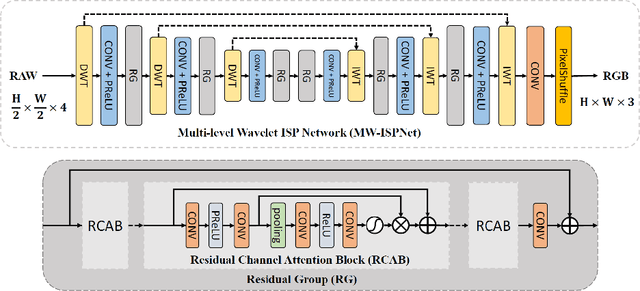
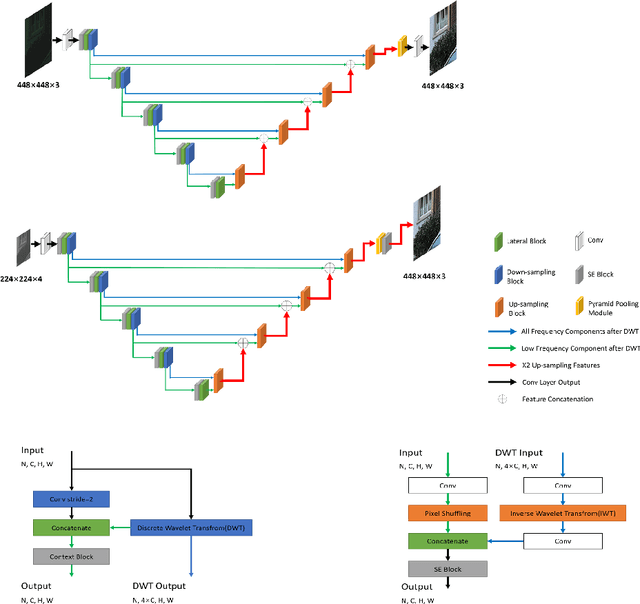
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.
Exemplar Normalization for Learning Deep Representation
Mar 20, 2020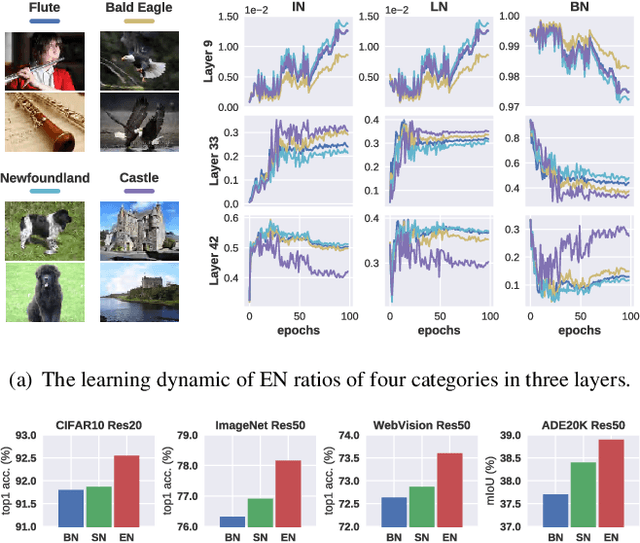
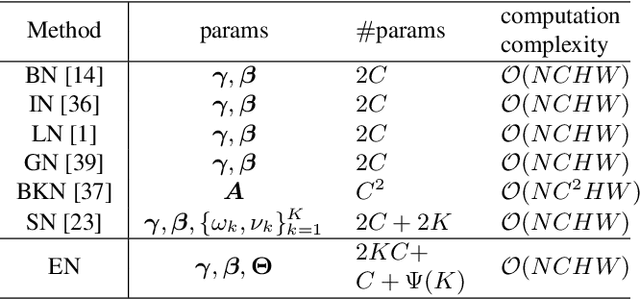
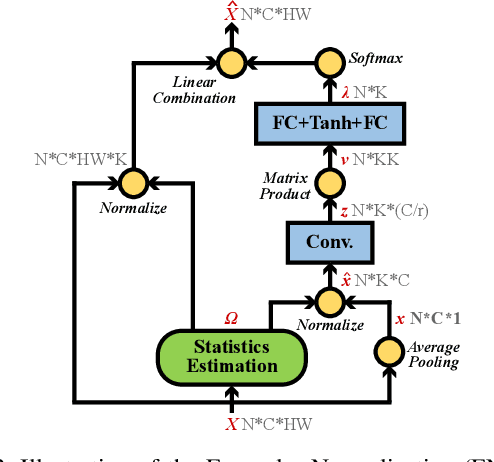
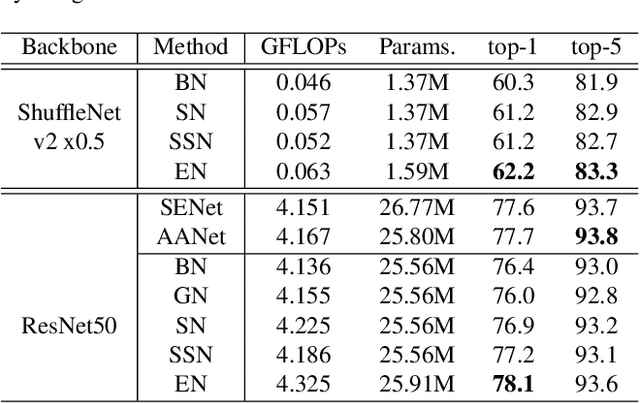
Normalization techniques are important in different advanced neural networks and different tasks. This work investigates a novel dynamic learning-to-normalize (L2N) problem by proposing Exemplar Normalization (EN), which is able to learn different normalization methods for different convolutional layers and image samples of a deep network. EN significantly improves flexibility of the recently proposed switchable normalization (SN), which solves a static L2N problem by linearly combining several normalizers in each normalization layer (the combination is the same for all samples). Instead of directly employing a multi-layer perceptron (MLP) to learn data-dependent parameters as conditional batch normalization (cBN) did, the internal architecture of EN is carefully designed to stabilize its optimization, leading to many appealing benefits. (1) EN enables different convolutional layers, image samples, categories, benchmarks, and tasks to use different normalization methods, shedding light on analyzing them in a holistic view. (2) EN is effective for various network architectures and tasks. (3) It could replace any normalization layers in a deep network and still produce stable model training. Extensive experiments demonstrate the effectiveness of EN in a wide spectrum of tasks including image recognition, noisy label learning, and semantic segmentation. For example, by replacing BN in the ordinary ResNet50, improvement produced by EN is 300% more than that of SN on both ImageNet and the noisy WebVision dataset.
Differentiable Learning-to-Group Channels via Groupable Convolutional Neural Networks
Aug 19, 2019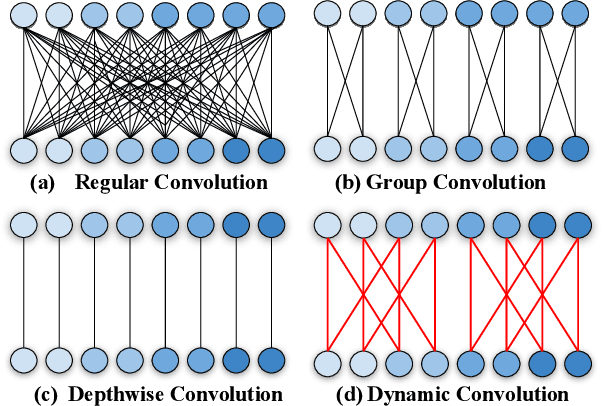
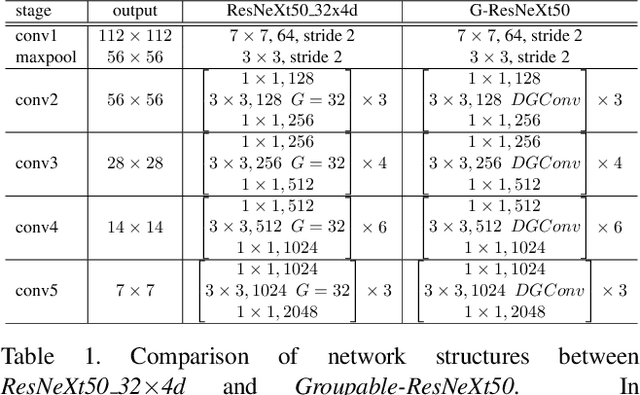
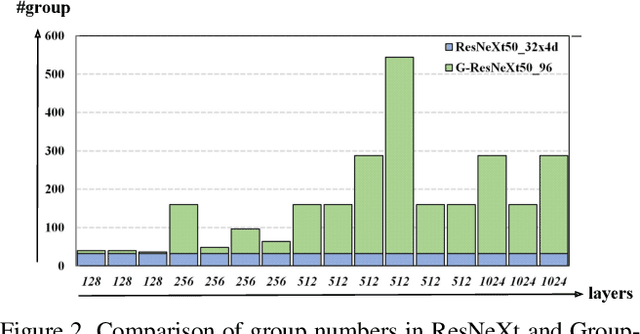
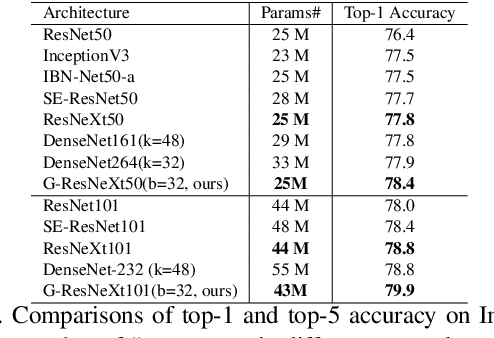
Group convolution, which divides the channels of ConvNets into groups, has achieved impressive improvement over the regular convolution operation. However, existing models, eg. ResNeXt, still suffers from the sub-optimal performance due to manually defining the number of groups as a constant over all of the layers. Toward addressing this issue, we present Groupable ConvNet (GroupNet) built by using a novel dynamic grouping convolution (DGConv) operation, which is able to learn the number of groups in an end-to-end manner. The proposed approach has several appealing benefits. (1) DGConv provides a unified convolution representation and covers many existing convolution operations such as regular dense convolution, group convolution, and depthwise convolution. (2) DGConv is a differentiable and flexible operation which learns to perform various convolutions from training data. (3) GroupNet trained with DGConv learns different number of groups for different convolution layers. Extensive experiments demonstrate that GroupNet outperforms its counterparts such as ResNet and ResNeXt in terms of accuracy and computational complexity. We also present introspection and reproducibility study, for the first time, showing the learning dynamics of training group numbers.
Switchable Normalization for Learning-to-Normalize Deep Representation
Jul 22, 2019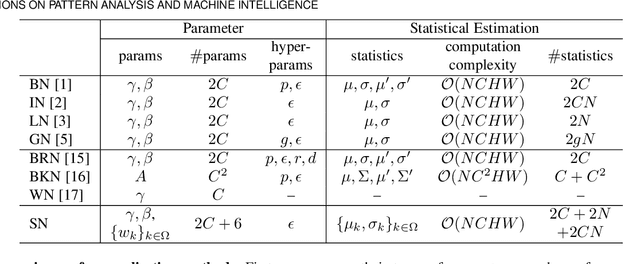

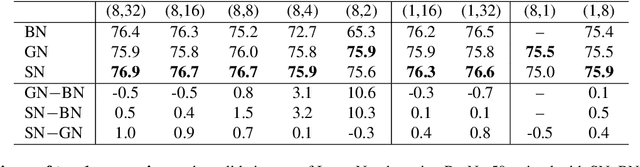
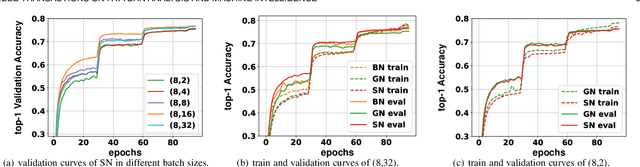
We address a learning-to-normalize problem by proposing Switchable Normalization (SN), which learns to select different normalizers for different normalization layers of a deep neural network. SN employs three distinct scopes to compute statistics (means and variances) including a channel, a layer, and a minibatch. SN switches between them by learning their importance weights in an end-to-end manner. It has several good properties. First, it adapts to various network architectures and tasks. Second, it is robust to a wide range of batch sizes, maintaining high performance even when small minibatch is presented (e.g. 2 images/GPU). Third, SN does not have sensitive hyper-parameter, unlike group normalization that searches the number of groups as a hyper-parameter. Without bells and whistles, SN outperforms its counterparts on various challenging benchmarks, such as ImageNet, COCO, CityScapes, ADE20K, MegaFace, and Kinetics. Analyses of SN are also presented to answer the following three questions: (a) Is it useful to allow each normalization layer to select its own normalizer? (b) What impacts the choices of normalizers? (c) Do different tasks and datasets prefer different normalizers? We hope SN will help ease the usage and understand the normalization techniques in deep learning. The code of SN has been released at https://github.com/switchablenorms.
Do Normalization Layers in a Deep ConvNet Really Need to Be Distinct?
Nov 19, 2018


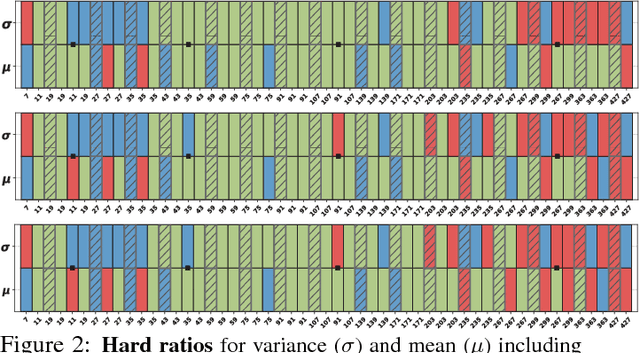
Yes, they do. This work investigates a perspective for deep learning: whether different normalization layers in a ConvNet require different normalizers. This is the first step towards understanding this phenomenon. We allow each convolutional layer to be stacked before a switchable normalization (SN) that learns to choose a normalizer from a pool of normalization methods. Through systematic experiments in ImageNet, COCO, Cityscapes, and ADE20K, we answer three questions: (a) Is it useful to allow each normalization layer to select its own normalizer? (b) What impacts the choices of normalizers? (c) Do different tasks and datasets prefer different normalizers? Our results suggest that (1) using distinct normalizers improves both learning and generalization of a ConvNet; (2) the choices of normalizers are more related to depth and batch size, but less relevant to parameter initialization, learning rate decay, and solver; (3) different tasks and datasets have different behaviors when learning to select normalizers.
Towards Understanding Regularization in Batch Normalization
Sep 30, 2018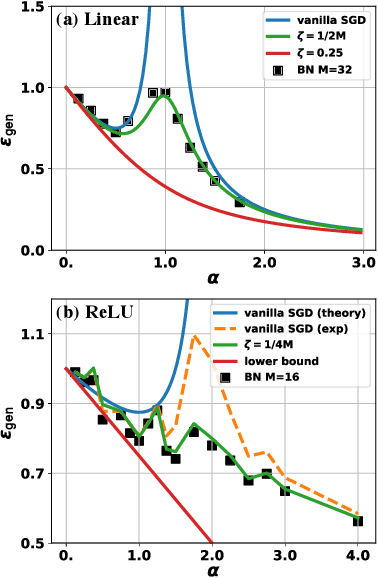
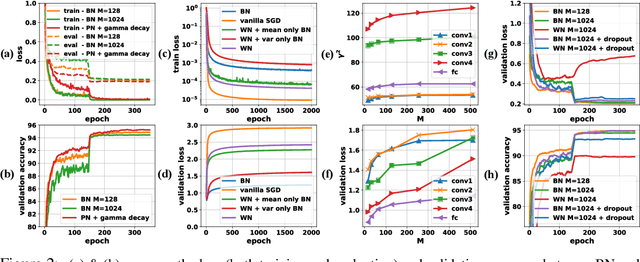

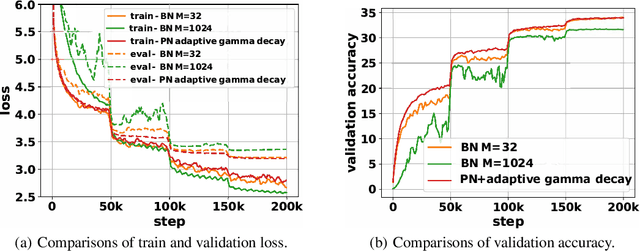
Batch Normalization (BN) improves both convergence and generalization in training neural networks. This work understands these phenomena theoretically. We analyze BN by using a basic block of neural networks, consisting of a kernel layer, a BN layer, and a nonlinear activation function. This basic network helps us understand the impacts of BN in three aspects. First, by viewing BN as an implicit regularizer, BN can be decomposed into population normalization (PN) and gamma decay as an explicit regularization. Second, learning dynamics of BN and the regularization show that training converged with large maximum and effective learning rate. Third, generalization of BN is explored by using statistical mechanics. Experiments demonstrate that BN in convolutional neural networks share the same traits of regularization as the above analyses.
Differentiable Learning-to-Normalize via Switchable Normalization
Sep 30, 2018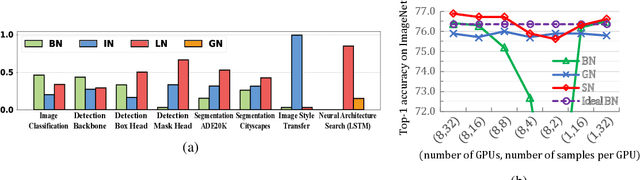
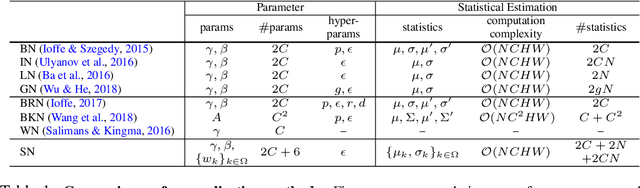

We address a learning-to-normalize problem by proposing Switchable Normalization (SN), which learns to select different normalizers for different normalization layers of a deep neural network. SN employs three distinct scopes to compute statistics (means and variances) including a channel, a layer, and a minibatch. SN switches between them by learning their importance weights in an end-to-end manner. It has several good properties. First, it adapts to various network architectures and tasks (see Fig.1). Second, it is robust to a wide range of batch sizes, maintaining high performance even when small minibatch is presented (e.g. 2 images/GPU). Third, SN does not have sensitive hyper-parameter, unlike group normalization that searches the number of groups as a hyper-parameter. Without bells and whistles, SN outperforms its counterparts on various challenging benchmarks, such as ImageNet, COCO, CityScapes, ADE20K, and Kinetics. Analyses of SN are also presented. We hope SN will help ease the usage and understand the normalization techniques in deep learning. The code of SN has been made available in https://github.com/switchablenorms/.