 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceSIR: A Multi-Agent Framework for Structured Analysis and Reporting of Agentic Execution Traces
Feb 28, 2026Agentic systems augment large language models with external tools and iterative decision making, enabling complex tasks such as deep research, function calling, and coding. However, their long and intricate execution traces make failure diagnosis and root cause analysis extremely challenging. Manual inspection does not scale, while directly applying LLMs to raw traces is hindered by input length limits and unreliable reasoning. Focusing solely on final task outcomes further discards critical behavioral information required for accurate issue localization. To address these issues, we propose TraceSIR, a multi-agent framework for structured analysis and reporting of agentic execution traces. TraceSIR coordinates three specialized agents: (1) StructureAgent, which introduces a novel abstraction format, TraceFormat, to compress execution traces while preserving essential behavioral information; (2) InsightAgent, which performs fine-grained diagnosis including issue localization, root cause analysis, and optimization suggestions; (3) ReportAgent, which aggregates insights across task instances and generates comprehensive analysis reports. To evaluate TraceSIR, we construct TraceBench, covering three real-world agentic scenarios, and introduce ReportEval, an evaluation protocol for assessing the quality and usability of analysis reports aligned with industry needs. Experiments show that TraceSIR consistently produces coherent, informative, and actionable reports, significantly outperforming existing approaches across all evaluation dimensions. Our project and video are publicly available at https://github.com/SHU-XUN/TraceSIR.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
UXNet: Searching Multi-level Feature Aggregation for 3D Medical Image Segmentation
Sep 16, 2020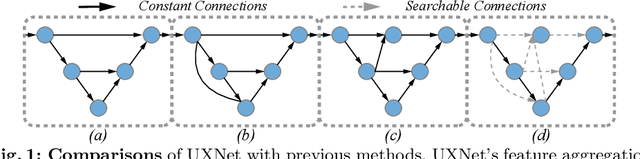
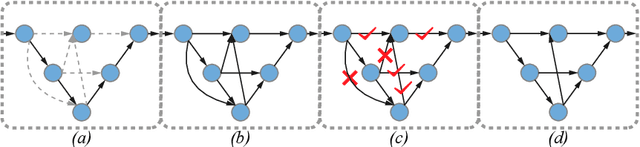


Aggregating multi-level feature representation plays a critical role in achieving robust volumetric medical image segmentation, which is important for the auxiliary diagnosis and treatment. Unlike the recent neural architecture search (NAS) methods that typically searched the optimal operators in each network layer, but missed a good strategy to search for feature aggregations, this paper proposes a novel NAS method for 3D medical image segmentation, named UXNet, which searches both the scale-wise feature aggregation strategies as well as the block-wise operators in the encoder-decoder network. UXNet has several appealing benefits. (1) It significantly improves flexibility of the classical UNet architecture, which only aggregates feature representations of encoder and decoder in equivalent resolution. (2) A continuous relaxation of UXNet is carefully designed, enabling its searching scheme performed in an efficient differentiable manner. (3) Extensive experiments demonstrate the effectiveness of UXNet compared with recent NAS methods for medical image segmentation. The architecture discovered by UXNet outperforms existing state-of-the-art models in terms of Dice on several public 3D medical image segmentation benchmarks, especially for the boundary locations and tiny tissues. The searching computational complexity of UXNet is cheap, enabling to search a network with the best performance less than 1.5 days on two TitanXP GPUs.
Switchable Normalization for Learning-to-Normalize Deep Representation
Jul 22, 2019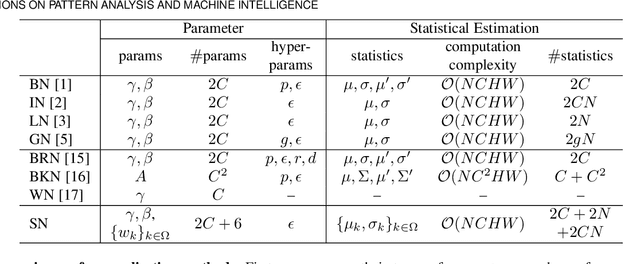

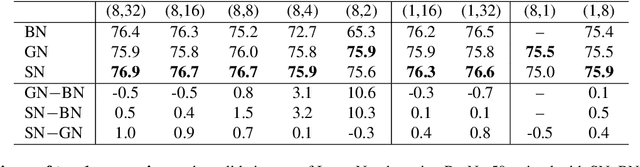
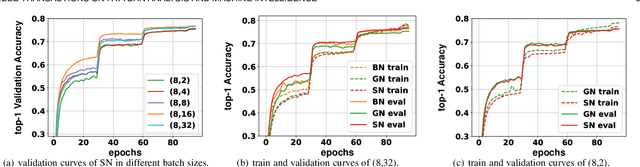
We address a learning-to-normalize problem by proposing Switchable Normalization (SN), which learns to select different normalizers for different normalization layers of a deep neural network. SN employs three distinct scopes to compute statistics (means and variances) including a channel, a layer, and a minibatch. SN switches between them by learning their importance weights in an end-to-end manner. It has several good properties. First, it adapts to various network architectures and tasks. Second, it is robust to a wide range of batch sizes, maintaining high performance even when small minibatch is presented (e.g. 2 images/GPU). Third, SN does not have sensitive hyper-parameter, unlike group normalization that searches the number of groups as a hyper-parameter. Without bells and whistles, SN outperforms its counterparts on various challenging benchmarks, such as ImageNet, COCO, CityScapes, ADE20K, MegaFace, and Kinetics. Analyses of SN are also presented to answer the following three questions: (a) Is it useful to allow each normalization layer to select its own normalizer? (b) What impacts the choices of normalizers? (c) Do different tasks and datasets prefer different normalizers? We hope SN will help ease the usage and understand the normalization techniques in deep learning. The code of SN has been released at https://github.com/switchablenorms.
Do Normalization Layers in a Deep ConvNet Really Need to Be Distinct?
Nov 19, 2018


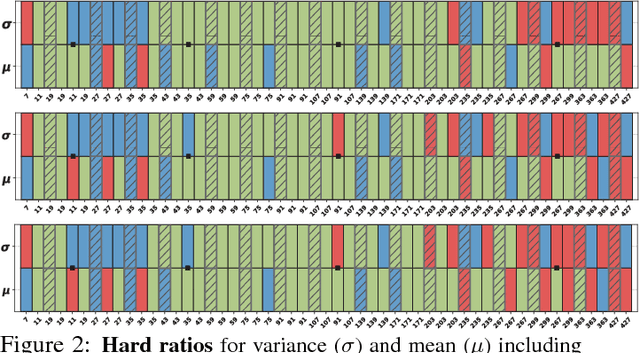
Yes, they do. This work investigates a perspective for deep learning: whether different normalization layers in a ConvNet require different normalizers. This is the first step towards understanding this phenomenon. We allow each convolutional layer to be stacked before a switchable normalization (SN) that learns to choose a normalizer from a pool of normalization methods. Through systematic experiments in ImageNet, COCO, Cityscapes, and ADE20K, we answer three questions: (a) Is it useful to allow each normalization layer to select its own normalizer? (b) What impacts the choices of normalizers? (c) Do different tasks and datasets prefer different normalizers? Our results suggest that (1) using distinct normalizers improves both learning and generalization of a ConvNet; (2) the choices of normalizers are more related to depth and batch size, but less relevant to parameter initialization, learning rate decay, and solver; (3) different tasks and datasets have different behaviors when learning to select normalizers.
Differentiable Learning-to-Normalize via Switchable Normalization
Sep 30, 2018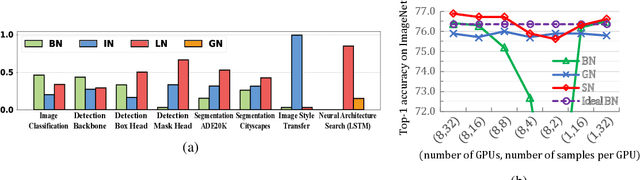
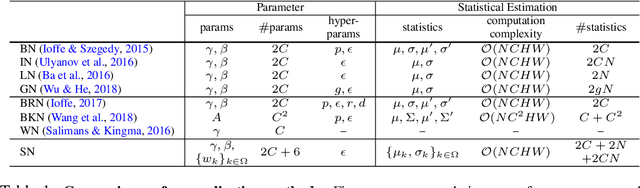
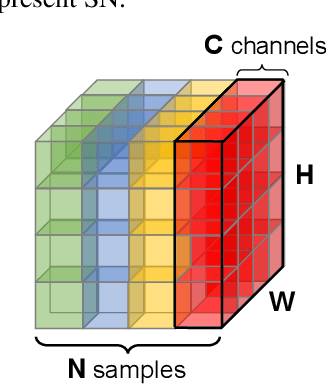

We address a learning-to-normalize problem by proposing Switchable Normalization (SN), which learns to select different normalizers for different normalization layers of a deep neural network. SN employs three distinct scopes to compute statistics (means and variances) including a channel, a layer, and a minibatch. SN switches between them by learning their importance weights in an end-to-end manner. It has several good properties. First, it adapts to various network architectures and tasks (see Fig.1). Second, it is robust to a wide range of batch sizes, maintaining high performance even when small minibatch is presented (e.g. 2 images/GPU). Third, SN does not have sensitive hyper-parameter, unlike group normalization that searches the number of groups as a hyper-parameter. Without bells and whistles, SN outperforms its counterparts on various challenging benchmarks, such as ImageNet, COCO, CityScapes, ADE20K, and Kinetics. Analyses of SN are also presented. We hope SN will help ease the usage and understand the normalization techniques in deep learning. The code of SN has been made available in https://github.com/switchablenorms/.