 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Interrupt in Language-based Multi-agent Communication
Apr 07, 2026Multi-agent systems using large language models (LLMs) have demonstrated impressive capabilities across various domains. However, current agent communication suffers from verbose output that overload context and increase computational costs. Although existing approaches focus on compressing the message from the speaker side, they struggle to adapt to different listeners and identify relevant information. An effective way in human communication is to allow the listener to interrupt and express their opinion or ask for clarification. Motivated by this, we propose an interruptible communication framework that allows the agent who is listening to interrupt the current speaker. Through prompting experiments, we find that current LLMs are often overconfident and interrupt before receiving enough information. Therefore, we propose a learning method that predicts the appropriate interruption points based on the estimated future reward and cost. We evaluate our framework across various multi-agent scenarios, including 2-agent text pictionary games, 3-agent meeting scheduling, and 3-agent debate. The results of the experiment show that our HANDRAISER can reduce the communication cost by 32.2% compared to the baseline with comparable or superior task performance. This learned interruption behavior can also be generalized to different agents and tasks.
GLM-OCR Technical Report
Mar 11, 2026GLM-OCR is an efficient 0.9B-parameter compact multimodal model designed for real-world document understanding. It combines a 0.4B-parameter CogViT visual encoder with a 0.5B-parameter GLM language decoder, achieving a strong balance between computational efficiency and recognition performance. To address the inefficiency of standard autoregressive decoding in deterministic OCR tasks, GLM-OCR introduces a Multi-Token Prediction (MTP) mechanism that predicts multiple tokens per step, significantly improving decoding throughput while keeping memory overhead low through shared parameters. At the system level, a two-stage pipeline is adopted: PP-DocLayout-V3 first performs layout analysis, followed by parallel region-level recognition. Extensive evaluations on public benchmarks and industrial scenarios show that GLM-OCR achieves competitive or state-of-the-art performance in document parsing, text and formula transcription, table structure recovery, and key information extraction. Its compact architecture and structured generation make it suitable for both resource-constrained edge deployment and large-scale production systems.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
DialectGen: Benchmarking and Improving Dialect Robustness in Multimodal Generation
Oct 16, 2025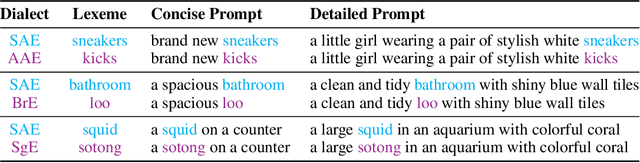
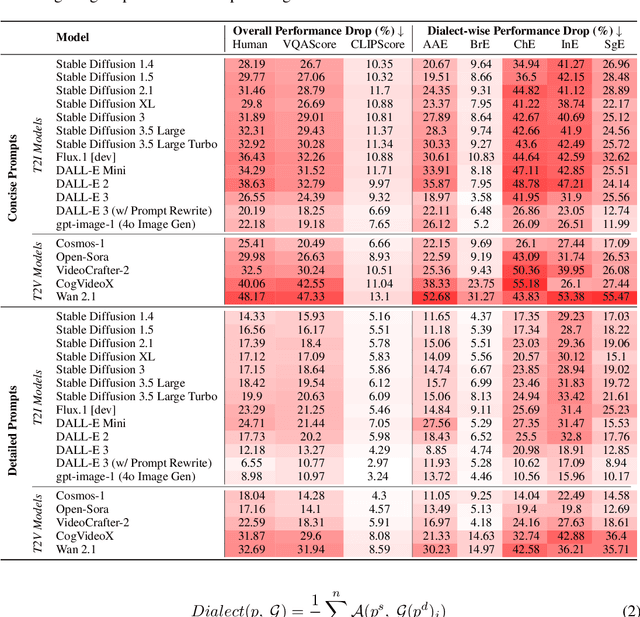
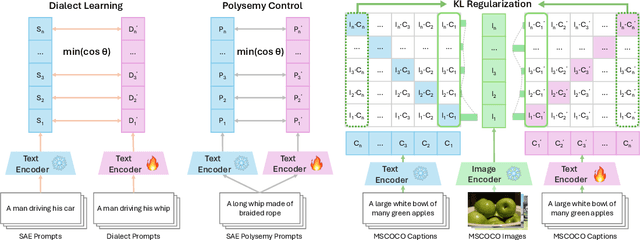
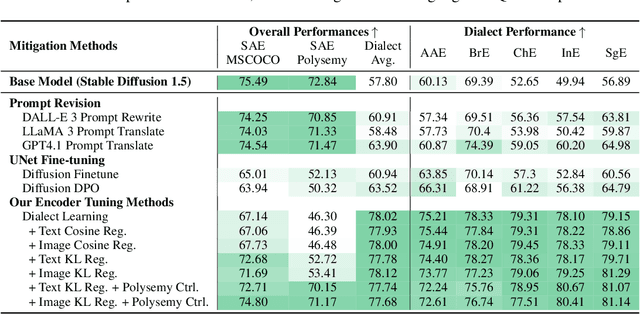
Contact languages like English exhibit rich regional variations in the form of dialects, which are often used by dialect speakers interacting with generative models. However, can multimodal generative models effectively produce content given dialectal textual input? In this work, we study this question by constructing a new large-scale benchmark spanning six common English dialects. We work with dialect speakers to collect and verify over 4200 unique prompts and evaluate on 17 image and video generative models. Our automatic and human evaluation results show that current state-of-the-art multimodal generative models exhibit 32.26% to 48.17% performance degradation when a single dialect word is used in the prompt. Common mitigation methods such as fine-tuning and prompt rewriting can only improve dialect performance by small margins (< 7%), while potentially incurring significant performance degradation in Standard American English (SAE). To this end, we design a general encoder-based mitigation strategy for multimodal generative models. Our method teaches the model to recognize new dialect features while preserving SAE performance. Experiments on models such as Stable Diffusion 1.5 show that our method is able to simultaneously raise performance on five dialects to be on par with SAE (+34.4%), while incurring near zero cost to SAE performance.
LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
Oct 16, 2025
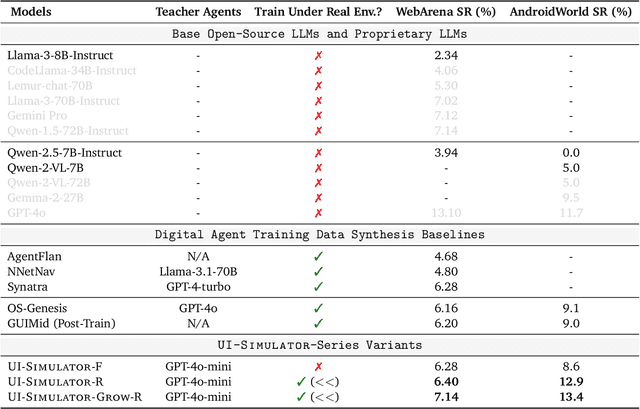

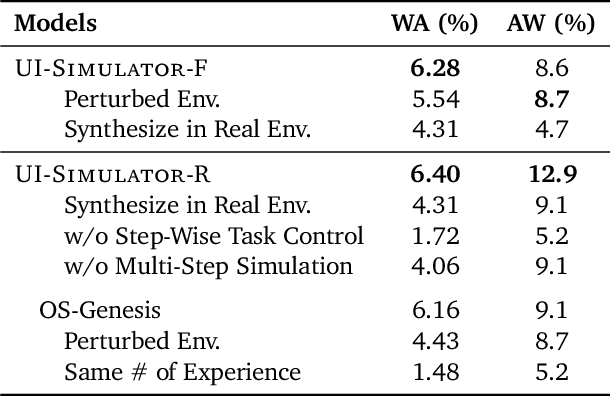
Digital agents require diverse, large-scale UI trajectories to generalize across real-world tasks, yet collecting such data is prohibitively expensive in both human annotation, infra and engineering perspectives. To this end, we introduce $\textbf{UI-Simulator}$, a scalable paradigm that generates structured UI states and transitions to synthesize training trajectories at scale. Our paradigm integrates a digital world simulator for diverse UI states, a guided rollout process for coherent exploration, and a trajectory wrapper that produces high-quality and diverse trajectories for agent training. We further propose $\textbf{UI-Simulator-Grow}$, a targeted scaling strategy that enables more rapid and data-efficient scaling by prioritizing high-impact tasks and synthesizes informative trajectory variants. Experiments on WebArena and AndroidWorld show that UI-Simulator rivals or surpasses open-source agents trained on real UIs with significantly better robustness, despite using weaker teacher models. Moreover, UI-Simulator-Grow matches the performance of Llama-3-70B-Instruct using only Llama-3-8B-Instruct as the base model, highlighting the potential of targeted synthesis scaling paradigm to continuously and efficiently enhance the digital agents.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
Embodied Web Agents: Bridging Physical-Digital Realms for Integrated Agent Intelligence
Jun 18, 2025AI agents today are mostly siloed - they either retrieve and reason over vast amount of digital information and knowledge obtained online; or interact with the physical world through embodied perception, planning and action - but rarely both. This separation limits their ability to solve tasks that require integrated physical and digital intelligence, such as cooking from online recipes, navigating with dynamic map data, or interpreting real-world landmarks using web knowledge. We introduce Embodied Web Agents, a novel paradigm for AI agents that fluidly bridge embodiment and web-scale reasoning. To operationalize this concept, we first develop the Embodied Web Agents task environments, a unified simulation platform that tightly integrates realistic 3D indoor and outdoor environments with functional web interfaces. Building upon this platform, we construct and release the Embodied Web Agents Benchmark, which encompasses a diverse suite of tasks including cooking, navigation, shopping, tourism, and geolocation - all requiring coordinated reasoning across physical and digital realms for systematic assessment of cross-domain intelligence. Experimental results reveal significant performance gaps between state-of-the-art AI systems and human capabilities, establishing both challenges and opportunities at the intersection of embodied cognition and web-scale knowledge access. All datasets, codes and websites are publicly available at our project page https://embodied-web-agent.github.io/.
RefTool: Enhancing Model Reasoning with Reference-Guided Tool Creation
May 27, 2025Tools enhance the reasoning capabilities of large language models (LLMs) in complex problem-solving tasks, but not all tasks have available tools. In the absence of predefined tools, prior works have explored instructing LLMs to generate tools on their own. However, such approaches rely heavily on the models' internal knowledge and would fail in domains beyond the LLMs' knowledge scope. To address this limitation, we propose RefTool, a reference-guided framework for automatic tool creation that leverages structured external materials such as textbooks. RefTool consists of two modules: (1) tool creation, where LLMs generate executable tools from reference content, validate them using illustrative examples, and organize them hierarchically into a toolbox; and (2) tool utilization, where LLMs navigate the toolbox structure to select and apply the appropriate tools to solve problems. Experiments on causality, physics, and chemistry benchmarks demonstrate that RefTool outperforms existing tool-creation and domain-specific reasoning methods by 11.3% on average accuracy, while being cost-efficient and broadly generalizable. Analyses reveal that grounding tool creation in references produces accurate and faithful tools, and that the hierarchical structure facilitates effective tool selection. RefTool enables LLMs to overcome knowledge limitations, demonstrating the value of grounding tool creation in external references for enhanced and generalizable reasoning.
QLASS: Boosting Language Agent Inference via Q-Guided Stepwise Search
Feb 04, 2025



Language agents have become a promising solution to complex interactive tasks. One of the key ingredients to the success of language agents is the reward model on the trajectory of the agentic workflow, which provides valuable guidance during training or inference. However, due to the lack of annotations of intermediate interactions, most existing works use an outcome reward model to optimize policies across entire trajectories. This may lead to sub-optimal policies and hinder the overall performance. To address this, we propose QLASS (Q-guided Language Agent Stepwise Search), to automatically generate annotations by estimating Q-values in a stepwise manner for open language agents. By introducing a reasoning tree and performing process reward modeling, QLASS provides effective intermediate guidance for each step. With the stepwise guidance, we propose a Q-guided generation strategy to enable language agents to better adapt to long-term value, resulting in significant performance improvement during model inference on complex interactive agent tasks. Notably, even with almost half the annotated data, QLASS retains strong performance, demonstrating its efficiency in handling limited supervision. We also empirically demonstrate that QLASS can lead to more effective decision making through qualitative analysis. We will release our code and data.