 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Beyond: Streaming LLM Updates via Activation-Guided Rotations
Feb 03, 2026The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.
Read As Human: Compressing Context via Parallelizable Close Reading and Skimming
Feb 02, 2026Large Language Models (LLMs) demonstrate exceptional capability across diverse tasks. However, their deployment in long-context scenarios is hindered by two challenges: computational inefficiency and redundant information. We propose RAM (Read As HuMan), a context compression framework that adopts an adaptive hybrid reading strategy, to address these challenges. Inspired by human reading behavior (i.e., close reading important content while skimming less relevant content), RAM partitions the context into segments and encodes them with the input query in parallel. High-relevance segments are fully retained (close reading), while low-relevance ones are query-guided compressed into compact summary vectors (skimming). Both explicit textual segments and implicit summary vectors are concatenated and fed into decoder to achieve both superior performance and natural language format interpretability. To refine the decision boundary between close reading and skimming, we further introduce a contrastive learning objective based on positive and negative query-segment pairs. Experiments demonstrate that RAM outperforms existing baselines on multiple question answering and summarization benchmarks across two backbones, while delivering up to a 12x end-to-end speedup on long inputs (average length 16K; maximum length 32K).
FGP: Feature-Gradient-Prune for Efficient Convolutional Layer Pruning
Nov 19, 2024



To reduce computational overhead while maintaining model performance, model pruning techniques have been proposed. Among these, structured pruning, which removes entire convolutional channels or layers, significantly enhances computational efficiency and is compatible with hardware acceleration. However, existing pruning methods that rely solely on image features or gradients often result in the retention of redundant channels, negatively impacting inference efficiency. To address this issue, this paper introduces a novel pruning method called Feature-Gradient Pruning (FGP). This approach integrates both feature-based and gradient-based information to more effectively evaluate the importance of channels across various target classes, enabling a more accurate identification of channels that are critical to model performance. Experimental results demonstrate that the proposed method improves both model compactness and practicality while maintaining stable performance. Experiments conducted across multiple tasks and datasets show that FGP significantly reduces computational costs and minimizes accuracy loss compared to existing methods, highlighting its effectiveness in optimizing pruning outcomes. The source code is available at: https://github.com/FGP-code/FGP.
CogVLM2: Visual Language Models for Image and Video Understanding
Aug 29, 2024

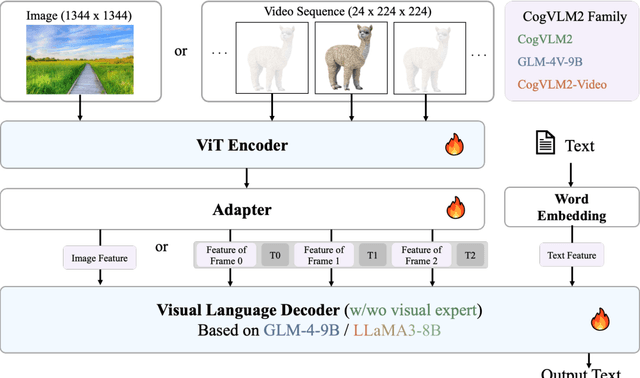
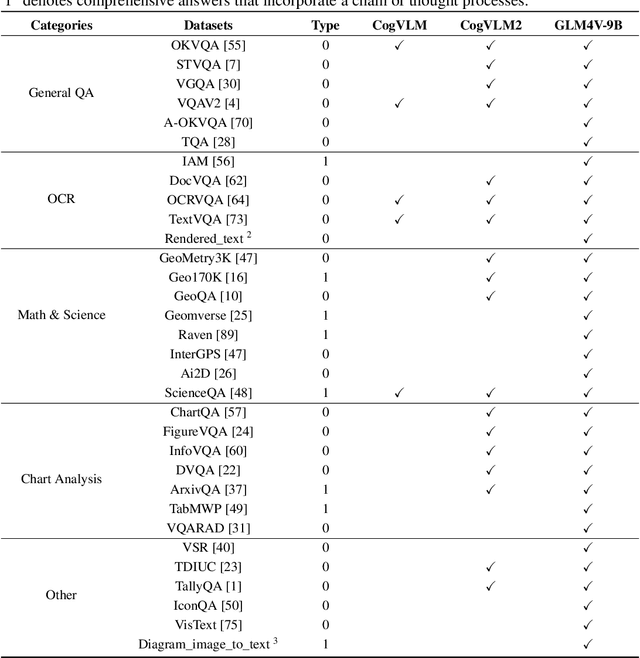
Beginning with VisualGLM and CogVLM, we are continuously exploring VLMs in pursuit of enhanced vision-language fusion, efficient higher-resolution architecture, and broader modalities and applications. Here we propose the CogVLM2 family, a new generation of visual language models for image and video understanding including CogVLM2, CogVLM2-Video and GLM-4V. As an image understanding model, CogVLM2 inherits the visual expert architecture with improved training recipes in both pre-training and post-training stages, supporting input resolution up to $1344 \times 1344$ pixels. As a video understanding model, CogVLM2-Video integrates multi-frame input with timestamps and proposes automated temporal grounding data construction. Notably, CogVLM2 family has achieved state-of-the-art results on benchmarks like MMBench, MM-Vet, TextVQA, MVBench and VCGBench. All models are open-sourced in https://github.com/THUDM/CogVLM2 and https://github.com/THUDM/GLM-4, contributing to the advancement of the field.
UltraWiki: Ultra-fine-grained Entity Set Expansion with Negative Seed Entities
Mar 07, 2024



Entity Set Expansion (ESE) aims to identify new entities belonging to the same semantic class as a given set of seed entities. Traditional methods primarily relied on positive seed entities to represent a target semantic class, which poses challenge for the representation of ultra-fine-grained semantic classes. Ultra-fine-grained semantic classes are defined based on fine-grained semantic classes with more specific attribute constraints. Describing it with positive seed entities alone cause two issues: (i) Ambiguity among ultra-fine-grained semantic classes. (ii) Inability to define "unwanted" semantic. Due to these inherent shortcomings, previous methods struggle to address the ultra-fine-grained ESE (Ultra-ESE). To solve this issue, we first introduce negative seed entities in the inputs, which belong to the same fine-grained semantic class as the positive seed entities but differ in certain attributes. Negative seed entities eliminate the semantic ambiguity by contrast between positive and negative attributes. Meanwhile, it provide a straightforward way to express "unwanted". To assess model performance in Ultra-ESE, we constructed UltraWiki, the first large-scale dataset tailored for Ultra-ESE. UltraWiki encompasses 236 ultra-fine-grained semantic classes, where each query of them is represented with 3-5 positive and negative seed entities. A retrieval-based framework RetExpan and a generation-based framework GenExpan are proposed to comprehensively assess the efficacy of large language models from two different paradigms in Ultra-ESE. Moreover, we devised three strategies to enhance models' comprehension of ultra-fine-grained entities semantics: contrastive learning, retrieval augmentation, and chain-of-thought reasoning. Extensive experiments confirm the effectiveness of our proposed strategies and also reveal that there remains a large space for improvement in Ultra-ESE.
CogCoM: Train Large Vision-Language Models Diving into Details through Chain of Manipulations
Feb 06, 2024



Vision-Language Models (VLMs) have demonstrated their widespread viability thanks to extensive training in aligning visual instructions to answers. However, this conclusive alignment leads models to ignore critical visual reasoning, and further result in failures on meticulous visual problems and unfaithful responses. In this paper, we propose Chain of Manipulations, a mechanism that enables VLMs to solve problems with a series of manipulations, where each manipulation refers to an operation on the visual input, either from intrinsic abilities (e.g., grounding) acquired through prior training or from imitating human-like behaviors (e.g., zoom in). This mechanism encourages VLMs to generate faithful responses with evidential visual reasoning, and permits users to trace error causes in the interpretable paths. We thus train CogCoM, a general 17B VLM with a memory-based compatible architecture endowed this reasoning mechanism. Experiments show that our model achieves the state-of-the-art performance across 8 benchmarks from 3 categories, and a limited number of training steps with the data swiftly gains a competitive performance. The code and data are publicly available at https://github.com/THUDM/CogCoM.
CogAgent: A Visual Language Model for GUI Agents
Dec 21, 2023



People are spending an enormous amount of time on digital devices through graphical user interfaces (GUIs), e.g., computer or smartphone screens. Large language models (LLMs) such as ChatGPT can assist people in tasks like writing emails, but struggle to understand and interact with GUIs, thus limiting their potential to increase automation levels. In this paper, we introduce CogAgent, an 18-billion-parameter visual language model (VLM) specializing in GUI understanding and navigation. By utilizing both low-resolution and high-resolution image encoders, CogAgent supports input at a resolution of 1120*1120, enabling it to recognize tiny page elements and text. As a generalist visual language model, CogAgent achieves the state of the art on five text-rich and four general VQA benchmarks, including VQAv2, OK-VQA, Text-VQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet, and POPE. CogAgent, using only screenshots as input, outperforms LLM-based methods that consume extracted HTML text on both PC and Android GUI navigation tasks -- Mind2Web and AITW, advancing the state of the art. The model and codes are available at https://github.com/THUDM/CogVLM .
CogVLM: Visual Expert for Pretrained Language Models
Nov 06, 2023We introduce CogVLM, a powerful open-source visual language foundation model. Different from the popular shallow alignment method which maps image features into the input space of language model, CogVLM bridges the gap between the frozen pretrained language model and image encoder by a trainable visual expert module in the attention and FFN layers. As a result, CogVLM enables deep fusion of vision language features without sacrificing any performance on NLP tasks. CogVLM-17B achieves state-of-the-art performance on 10 classic cross-modal benchmarks, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA and TDIUC, and ranks the 2nd on VQAv2, OKVQA, TextVQA, COCO captioning, etc., surpassing or matching PaLI-X 55B. Codes and checkpoints are available at https://github.com/THUDM/CogVLM.
GPT Can Solve Mathematical Problems Without a Calculator
Sep 12, 2023Previous studies have typically assumed that large language models are unable to accurately perform arithmetic operations, particularly multiplication of >8 digits, and operations involving decimals and fractions, without the use of calculator tools. This paper aims to challenge this misconception. With sufficient training data, a 2 billion-parameter language model can accurately perform multi-digit arithmetic operations with almost 100% accuracy without data leakage, significantly surpassing GPT-4 (whose multi-digit multiplication accuracy is only 4.3%). We also demonstrate that our MathGLM, fine-tuned from GLM-10B on a dataset with additional multi-step arithmetic operations and math problems described in text, achieves similar performance to GPT-4 on a 5,000-samples Chinese math problem test set. Our code and data are public at https://github.com/THUDM/MathGLM.
Parameter-Efficient Tuning Makes a Good Classification Head
Oct 30, 2022



In recent years, pretrained models revolutionized the paradigm of natural language understanding (NLU), where we append a randomly initialized classification head after the pretrained backbone, e.g. BERT, and finetune the whole model. As the pretrained backbone makes a major contribution to the improvement, we naturally expect a good pretrained classification head can also benefit the training. However, the final-layer output of the backbone, i.e. the input of the classification head, will change greatly during finetuning, making the usual head-only pretraining (LP-FT) ineffective. In this paper, we find that parameter-efficient tuning makes a good classification head, with which we can simply replace the randomly initialized heads for a stable performance gain. Our experiments demonstrate that the classification head jointly pretrained with parameter-efficient tuning consistently improves the performance on 9 tasks in GLUE and SuperGLUE.