 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
CogVLM2: Visual Language Models for Image and Video Understanding
Aug 29, 2024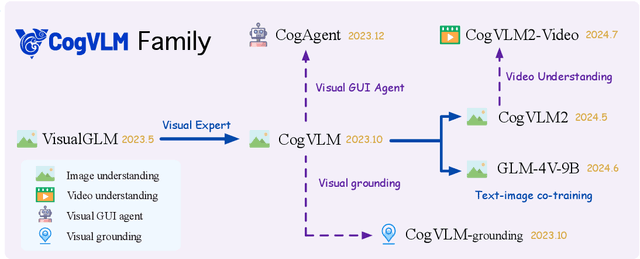

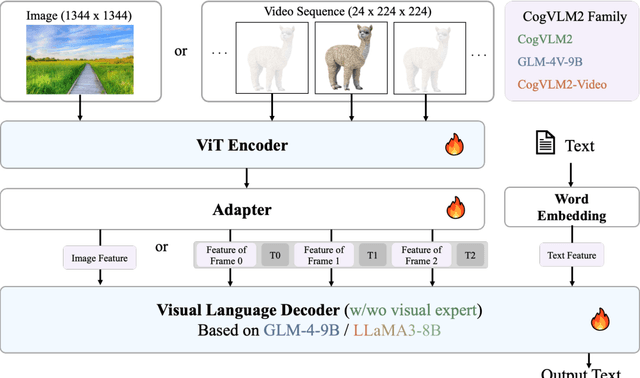
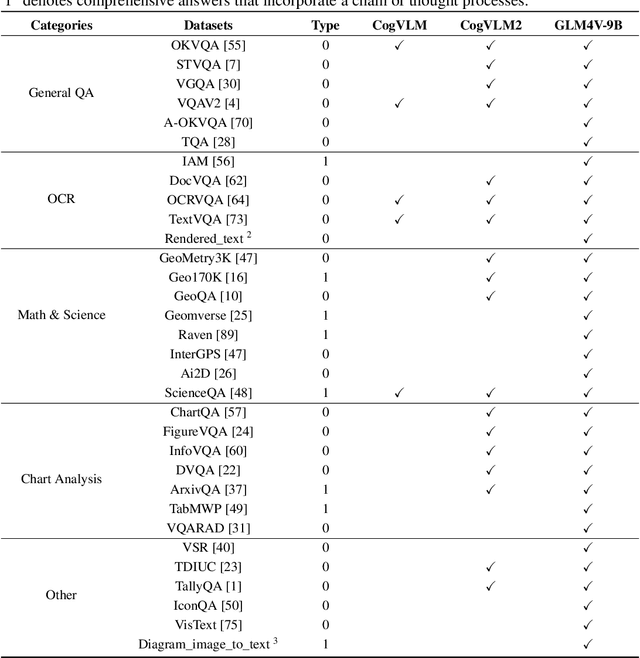
Beginning with VisualGLM and CogVLM, we are continuously exploring VLMs in pursuit of enhanced vision-language fusion, efficient higher-resolution architecture, and broader modalities and applications. Here we propose the CogVLM2 family, a new generation of visual language models for image and video understanding including CogVLM2, CogVLM2-Video and GLM-4V. As an image understanding model, CogVLM2 inherits the visual expert architecture with improved training recipes in both pre-training and post-training stages, supporting input resolution up to $1344 \times 1344$ pixels. As a video understanding model, CogVLM2-Video integrates multi-frame input with timestamps and proposes automated temporal grounding data construction. Notably, CogVLM2 family has achieved state-of-the-art results on benchmarks like MMBench, MM-Vet, TextVQA, MVBench and VCGBench. All models are open-sourced in https://github.com/THUDM/CogVLM2 and https://github.com/THUDM/GLM-4, contributing to the advancement of the field.
WuDaoMM: A large-scale Multi-Modal Dataset for Pre-training models
Mar 30, 2022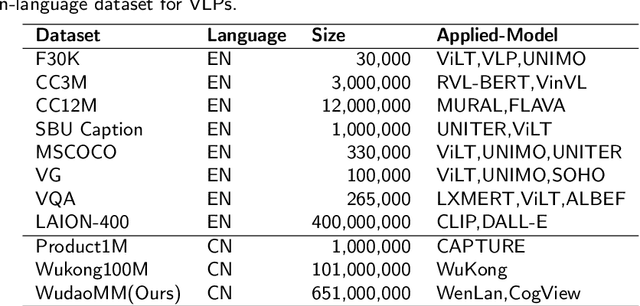


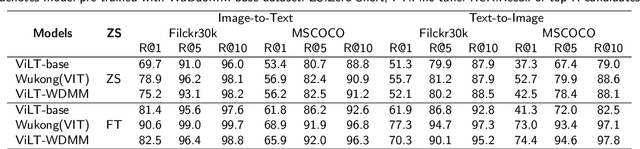
Compared with the domain-specific model, the vision-language pre-training models (VLPMs) have shown superior performance on downstream tasks with fast fine-tuning process. For example, ERNIE-ViL, Oscar and UNIMO trained VLPMs with a uniform transformers stack architecture and large amounts of image-text paired data, achieving remarkable results on downstream tasks such as image-text reference(IR and TR), vision question answering (VQA) and image captioning (IC) etc. During the training phase, VLPMs are always fed with a combination of multiple public datasets to meet the demand of large-scare training data. However, due to the unevenness of data distribution including size, task type and quality, using the mixture of multiple datasets for model training can be problematic. In this work, we introduce a large-scale multi-modal corpora named WuDaoMM, totally containing more than 650M image-text pairs. Specifically, about 600 million pairs of data are collected from multiple webpages in which image and caption present weak correlation, and the other 50 million strong-related image-text pairs are collected from some high-quality graphic websites. We also release a base version of WuDaoMM with 5 million strong-correlated image-text pairs, which is sufficient to support the common cross-modal model pre-training. Besides, we trained both an understanding and a generation vision-language (VL) model to test the dataset effectiveness. The results show that WuDaoMM can be applied as an efficient dataset for VLPMs, especially for the model in text-to-image generation task. The data is released at https://data.wudaoai.cn