 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWuDaoMM: A large-scale Multi-Modal Dataset for Pre-training models
Paper and Code
Mar 30, 2022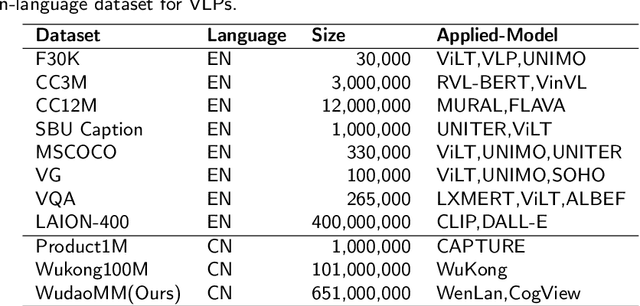


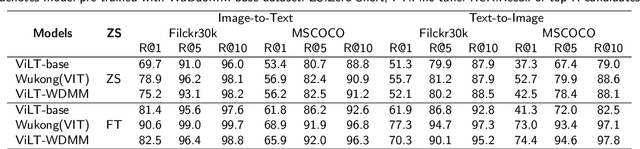
Compared with the domain-specific model, the vision-language pre-training models (VLPMs) have shown superior performance on downstream tasks with fast fine-tuning process. For example, ERNIE-ViL, Oscar and UNIMO trained VLPMs with a uniform transformers stack architecture and large amounts of image-text paired data, achieving remarkable results on downstream tasks such as image-text reference(IR and TR), vision question answering (VQA) and image captioning (IC) etc. During the training phase, VLPMs are always fed with a combination of multiple public datasets to meet the demand of large-scare training data. However, due to the unevenness of data distribution including size, task type and quality, using the mixture of multiple datasets for model training can be problematic. In this work, we introduce a large-scale multi-modal corpora named WuDaoMM, totally containing more than 650M image-text pairs. Specifically, about 600 million pairs of data are collected from multiple webpages in which image and caption present weak correlation, and the other 50 million strong-related image-text pairs are collected from some high-quality graphic websites. We also release a base version of WuDaoMM with 5 million strong-correlated image-text pairs, which is sufficient to support the common cross-modal model pre-training. Besides, we trained both an understanding and a generation vision-language (VL) model to test the dataset effectiveness. The results show that WuDaoMM can be applied as an efficient dataset for VLPMs, especially for the model in text-to-image generation task. The data is released at https://data.wudaoai.cn