 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyeMVP: OCT-Informed Fundus Representation Learning via Paired CFP--OCT Pretraining
Jun 13, 2026Color fundus photography (CFP) is the mainstay for large-scale retinal screening, yet its diagnostic capacity is constrained by the lack of depth-resolved structural information. Optical coherence tomography (OCT) provides cross-sectional retinal anatomy, but is less accessible in population-level screening. Here, we present EyeMVP, a cross-modal retinal foundation model that uses paired CFP--OCT pretraining to learn OCT-informed CFP representations. EyeMVP is pretrained on 674,893 strict same-eye same-day paired CFP--OCT image triples from 112,642 patients across eight hospitals in China. The model uses cross-modal masked reconstruction to enrich CFP representations with OCT-associated supervision, while requiring only CFP images at inference. To accommodate the non-aligned imaging geometry between en-face CFP and cross-sectional OCT, EyeMVP combines source-constrained cross-attention with CFP-derived structural masks. Across 16 downstream tasks, including classification, segmentation, few-shot adaptation, and cross-modal retrieval, EyeMVP outperforms representative retinal foundation models and shows consistent gains on tasks involving macular and optic nerve structure. For CFP-challenging macular diseases, EyeMVP achieves an AUROC of 0.948 for macular edema (vs.~0.852 for EyeCLIP) and 0.825 for myopic macular schisis. In an exploratory reader study, EyeMVP exceeds junior and intermediate ophthalmologist groups but does not reach senior ophthalmologist performance on macular edema, while showing numerically higher balanced accuracy than all reader groups on myopic macular schisis. These results suggest that pixel-level cross-modal reconstruction can enrich CFP representations with OCT-associated supervision, providing a practical route toward stronger CFP-based retinal analysis in screening settings.
Arbor: Tree Search as a Cognition Layer for Autonomous Agents
Jun 10, 2026Arbor is a multi-agent framework that introduces structured tree search as a cognition layer for autonomous agents operating in large, stateful action spaces. Prior autonomous optimization systems operate on isolated targets with stateless evaluation. Arbor instead maintains an explicit search tree of scored hypotheses that serves as the shared working memory across agents, evolving with every measurement, treating failures as diagnostic signal that reshapes subsequent exploration, and expanding as prior successes shift the bottleneck distribution. We validate Arbor on full-stack LLM inference optimization, a domain where achieving peak performance has historically required coordinated effort from engineering teams across the application, framework, compiler, kernel, and hardware stack. Arbor pairs an Orchestrator agent, which drives optimization by delegating to Domain Specialists across the inference stack, with a Critic agent that safeguards stability through root-cause analysis, introspection, and measurement validation -- a checks-and-balances architecture where neither agent can unilaterally drive the system. Agent capabilities are decomposed into hard skills (domain expertise) and soft skills (coordination protocols that determine how contributions compose), enabling fully autonomous multi-day campaigns. Arbor achieves up to 193% inference throughput-latency Pareto improvement over vendor-optimized baselines, while a single agent without the harness plateaus at +33% throughput improvement and crashes irrecoverably within hours. Arbor generalizes to multiple generations of hardware platform, and run-to-run variance is within 2 percentage points demonstrating that the method is hardware-agnostic and reproducible.
Frequency-Enhanced Hilbert Scanning Mamba for Short-Term Arctic Sea Ice Concentration Prediction
Feb 13, 2026While Mamba models offer efficient sequence modeling, vanilla versions struggle with temporal correlations and boundary details in Arctic sea ice concentration (SIC) prediction. To address these limitations, we propose Frequency-enhanced Hilbert scanning Mamba Framework (FH-Mamba) for short-term Arctic SIC prediction. Specifically, we introduce a 3D Hilbert scan mechanism that traverses the 3D spatiotemporal grid along a locality-preserving path, ensuring that adjacent indices in the flattened sequence correspond to neighboring voxels in both spatial and temporal dimensions. Additionally, we incorporate wavelet transform to amplify high-frequency details and we also design a Hybrid Shuffle Attention module to adaptively aggregate sequence and frequency features. Experiments conducted on the OSI-450a1 and AMSR2 datasets demonstrate that our FH-Mamba achieves superior prediction performance compared with state-of-the-art baselines. The results confirm the effectiveness of Hilbert scanning and frequency-aware attention in improving both temporal consistency and edge reconstruction for Arctic SIC forecasting. Our codes are publicly available at https://github.com/oucailab/FH-Mamba.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Enabling Real-Time Colonoscopic Polyp Segmentation on Commodity CPUs via Ultra-Lightweight Architecture
Feb 04, 2026Early detection of colorectal cancer hinges on real-time, accurate polyp identification and resection. Yet current high-precision segmentation models rely on GPUs, making them impractical to deploy in primary hospitals, mobile endoscopy units, or capsule robots. To bridge this gap, we present the UltraSeg family, operating in an extreme-compression regime (<0.3 M parameters). UltraSeg-108K (0.108 M parameters) is optimized for single-center data, while UltraSeg-130K (0.13 M parameters) generalizes to multi-center, multi-modal images. By jointly optimizing encoder-decoder widths, incorporating constrained dilated convolutions to enlarge receptive fields, and integrating a cross-layer lightweight fusion module, the models achieve 90 FPS on a single CPU core without sacrificing accuracy. Evaluated on seven public datasets, UltraSeg retains >94% of the Dice score of a 31 M-parameter U-Net while utilizing only 0.4% of its parameters, establishing a strong, clinically viable baseline for the extreme-compression domain and offering an immediately deployable solution for resource-constrained settings. This work provides not only a CPU-native solution for colonoscopy but also a reproducible blueprint for broader minimally invasive surgical vision applications. Source code is publicly available to ensure reproducibility and facilitate future benchmarking.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025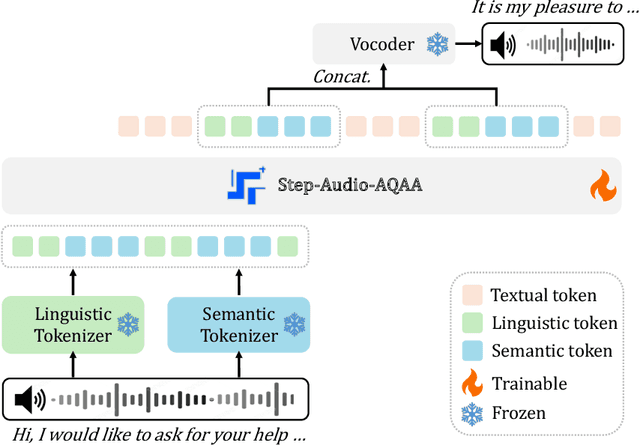
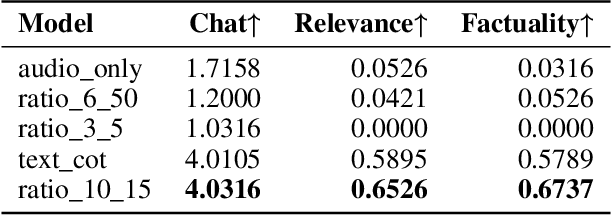
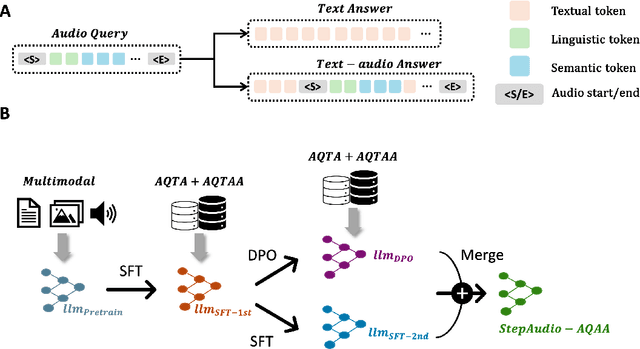

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
A New Deep-learning-Based Approach For mRNA Optimization: High Fidelity, Computation Efficiency, and Multiple Optimization Factors
May 29, 2025The mRNA optimization is critical for therapeutic and biotechnological applications, since sequence features directly govern protein expression levels and efficacy. However, current methods face significant challenges in simultaneously achieving three key objectives: (1) fidelity (preventing unintended amino acid changes), (2) computational efficiency (speed and scalability), and (3) the scope of optimization variables considered (multi-objective capability). Furthermore, existing methods often fall short of comprehensively incorporating the factors related to the mRNA lifecycle and translation process, including intrinsic mRNA sequence properties, secondary structure, translation elongation kinetics, and tRNA availability. To address these limitations, we introduce \textbf{RNop}, a novel deep learning-based method for mRNA optimization. We collect a large-scale dataset containing over 3 million sequences and design four specialized loss functions, the GPLoss, CAILoss, tAILoss, and MFELoss, which simultaneously enable explicit control over sequence fidelity while optimizing species-specific codon adaptation, tRNA availability, and desirable mRNA secondary structure features. Then, we demonstrate RNop's effectiveness through extensive in silico and in vivo experiments. RNop ensures high sequence fidelity, achieves significant computational throughput up to 47.32 sequences/s, and yields optimized mRNA sequences resulting in a significant increase in protein expression for functional proteins compared to controls. RNop surpasses current methodologies in both quantitative metrics and experimental validation, enlightening a new dawn for efficient and effective mRNA design. Code and models will be available at https://github.com/HudenJear/RPLoss.
Reach-Avoid-Stabilize Using Admissible Control Sets
May 14, 2025Hamilton-Jacobi Reachability (HJR) analysis has been successfully used in many robotics and control tasks, and is especially effective in computing reach-avoid sets and control laws that enable an agent to reach a goal while satisfying state constraints. However, the original HJR formulation provides no guarantees of safety after a) the prescribed time horizon, or b) goal satisfaction. The reach-avoid-stabilize (RAS) problem has therefore gained a lot of focus: find the set of initial states (the RAS set), such that the trajectory can reach the target, and stabilize to some point of interest (POI) while avoiding obstacles. Solving RAS problems using HJR usually requires defining a new value function, whose zero sub-level set is the RAS set. The existing methods do not consider the problem when there are a series of targets to reach and/or obstacles to avoid. We propose a method that uses the idea of admissible control sets; we guarantee that the system will reach each target while avoiding obstacles as prescribed by the given time series. Moreover, we guarantee that the trajectory ultimately stabilizes to the POI. The proposed method provides an under-approximation of the RAS set, guaranteeing safety. Numerical examples are provided to validate the theory.
Solving Reach- and Stabilize-Avoid Problems Using Discounted Reachability
May 14, 2025In this article, we consider the infinite-horizon reach-avoid (RA) and stabilize-avoid (SA) zero-sum game problems for general nonlinear continuous-time systems, where the goal is to find the set of states that can be controlled to reach or stabilize to a target set, without violating constraints even under the worst-case disturbance. Based on the Hamilton-Jacobi reachability method, we address the RA problem by designing a new Lipschitz continuous RA value function, whose zero sublevel set exactly characterizes the RA set. We establish that the associated Bellman backup operator is contractive and that the RA value function is the unique viscosity solution of a Hamilton-Jacobi variational inequality. Finally, we develop a two-step framework for the SA problem by integrating our RA strategies with a recently proposed Robust Control Lyapunov-Value Function, thereby ensuring both target reachability and long-term stability. We numerically verify our RA and SA frameworks on a 3D Dubins car system to demonstrate the efficacy of the proposed approach.