 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSS-CRS: Liberating AIxCC Cyber Reasoning Systems for Real-World Open-Source Security
Mar 09, 2026DARPA's AI Cyber Challenge (AIxCC) showed that cyber reasoning systems (CRSs) can go beyond vulnerability discovery to autonomously confirm and patch bugs: seven teams built such systems and open-sourced them after the competition. Yet all seven open-sourced CRSs remain largely unusable outside their original teams, each bound to the competition cloud infrastructure that no longer exists. We present OSS-CRS, an open, locally deployable framework for running and combining CRS techniques against real-world open-source projects, with budget-aware resource management. We ported the first-place system (Atlantis) and discovered 10 previously unknown bugs (three of high severity) across 8 OSS-Fuzz projects. OSS-CRS is publicly available.
SoK: DARPA's AI Cyber Challenge (AIxCC): Competition Design, Architectures, and Lessons Learned
Feb 07, 2026DARPA's AI Cyber Challenge (AIxCC, 2023--2025) is the largest competition to date for building fully autonomous cyber reasoning systems (CRSs) that leverage recent advances in AI -- particularly large language models (LLMs) -- to discover and remediate vulnerabilities in real-world open-source software. This paper presents the first systematic analysis of AIxCC. Drawing on design documents, source code, execution traces, and discussions with organizers and competing teams, we examine the competition's structure and key design decisions, characterize the architectural approaches of finalist CRSs, and analyze competition results beyond the final scoreboard. Our analysis reveals the factors that truly drove CRS performance, identifies genuine technical advances achieved by teams, and exposes limitations that remain open for future research. We conclude with lessons for organizing future competitions and broader insights toward deploying autonomous CRSs in practice.
Swarm Oracle: Trustless Blockchain Agreements through Robot Swarms
Sep 19, 2025



Blockchain consensus, rooted in the principle ``don't trust, verify'', limits access to real-world data, which may be ambiguous or inaccessible to some participants. Oracles address this limitation by supplying data to blockchains, but existing solutions may reduce autonomy, transparency, or reintroduce the need for trust. We propose Swarm Oracle: a decentralized network of autonomous robots -- that is, a robot swarm -- that use onboard sensors and peer-to-peer communication to collectively verify real-world data and provide it to smart contracts on public blockchains. Swarm Oracle leverages the built-in decentralization, fault tolerance and mobility of robot swarms, which can flexibly adapt to meet information requests on-demand, even in remote locations. Unlike typical cooperative robot swarms, Swarm Oracle integrates robots from multiple stakeholders, protecting the system from single-party biases but also introducing potential adversarial behavior. To ensure the secure, trustless and global consensus required by blockchains, we employ a Byzantine fault-tolerant protocol that enables robots from different stakeholders to operate together, reaching social agreements of higher quality than the estimates of individual robots. Through extensive experiments using both real and simulated robots, we showcase how consensus on uncertain environmental information can be achieved, despite several types of attacks orchestrated by large proportions of the robots, and how a reputation system based on blockchain tokens lets Swarm Oracle autonomously recover from faults and attacks, a requirement for long-term operation.
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025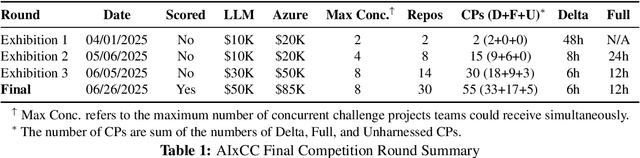
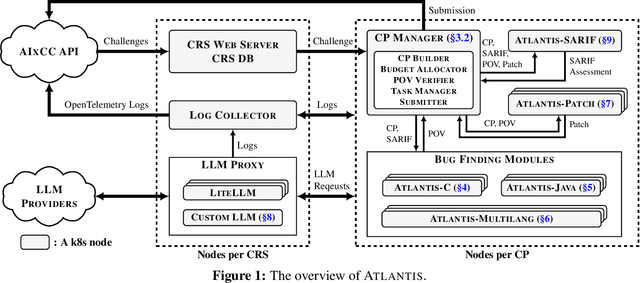
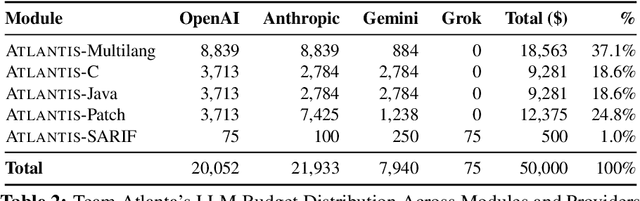
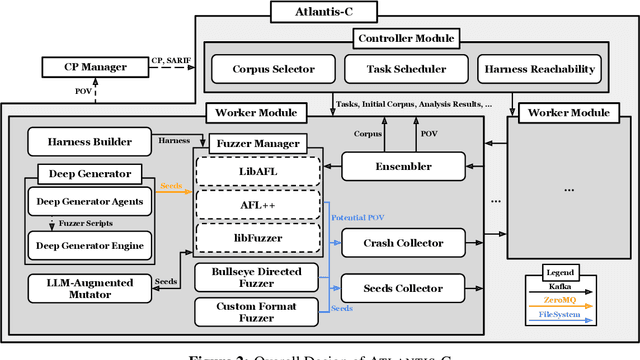
We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Mar 27, 2025The era of intelligent agents is upon us, driven by revolutionary advancements in large language models. Large Language Model (LLM) agents, with goal-driven behaviors and dynamic adaptation capabilities, potentially represent a critical pathway toward artificial general intelligence. This survey systematically deconstructs LLM agent systems through a methodology-centered taxonomy, linking architectural foundations, collaboration mechanisms, and evolutionary pathways. We unify fragmented research threads by revealing fundamental connections between agent design principles and their emergent behaviors in complex environments. Our work provides a unified architectural perspective, examining how agents are constructed, how they collaborate, and how they evolve over time, while also addressing evaluation methodologies, tool applications, practical challenges, and diverse application domains. By surveying the latest developments in this rapidly evolving field, we offer researchers a structured taxonomy for understanding LLM agents and identify promising directions for future research. The collection is available at https://github.com/luo-junyu/Awesome-Agent-Papers.
Versatile Cataract Fundus Image Restoration Model Utilizing Unpaired Cataract and High-quality Images
Nov 19, 2024



Cataract is one of the most common blinding eye diseases and can be treated by surgery. However, because cataract patients may also suffer from other blinding eye diseases, ophthalmologists must diagnose them before surgery. The cloudy lens of cataract patients forms a hazy degeneration in the fundus images, making it challenging to observe the patient's fundus vessels, which brings difficulties to the diagnosis process. To address this issue, this paper establishes a new cataract image restoration method named Catintell. It contains a cataract image synthesizing model, Catintell-Syn, and a restoration model, Catintell-Res. Catintell-Syn uses GAN architecture with fully unsupervised data to generate paired cataract-like images with realistic style and texture rather than the conventional Gaussian degradation algorithm. Meanwhile, Catintell-Res is an image restoration network that can improve the quality of real cataract fundus images using the knowledge learned from synthetic cataract images. Extensive experiments show that Catintell-Res outperforms other cataract image restoration methods in PSNR with 39.03 and SSIM with 0.9476. Furthermore, the universal restoration ability that Catintell-Res gained from unpaired cataract images can process cataract images from various datasets. We hope the models can help ophthalmologists identify other blinding eye diseases of cataract patients and inspire more medical image restoration methods in the future.
UniForensics: Face Forgery Detection via General Facial Representation
Jul 26, 2024



Previous deepfake detection methods mostly depend on low-level textural features vulnerable to perturbations and fall short of detecting unseen forgery methods. In contrast, high-level semantic features are less susceptible to perturbations and not limited to forgery-specific artifacts, thus having stronger generalization. Motivated by this, we propose a detection method that utilizes high-level semantic features of faces to identify inconsistencies in temporal domain. We introduce UniForensics, a novel deepfake detection framework that leverages a transformer-based video classification network, initialized with a meta-functional face encoder for enriched facial representation. In this way, we can take advantage of both the powerful spatio-temporal model and the high-level semantic information of faces. Furthermore, to leverage easily accessible real face data and guide the model in focusing on spatio-temporal features, we design a Dynamic Video Self-Blending (DVSB) method to efficiently generate training samples with diverse spatio-temporal forgery traces using real facial videos. Based on this, we advance our framework with a two-stage training approach: The first stage employs a novel self-supervised contrastive learning, where we encourage the network to focus on forgery traces by impelling videos generated by the same forgery process to have similar representations. On the basis of the representation learned in the first stage, the second stage involves fine-tuning on face forgery detection dataset to build a deepfake detector. Extensive experiments validates that UniForensics outperforms existing face forgery methods in generalization ability and robustness. In particular, our method achieves 95.3\% and 77.2\% cross dataset AUC on the challenging Celeb-DFv2 and DFDC respectively.
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models
Jul 21, 2024



Virtual try-on methods based on diffusion models achieve realistic try-on effects but often replicate the backbone network as a ReferenceNet or use additional image encoders to process condition inputs, leading to high training and inference costs. In this work, we rethink the necessity of ReferenceNet and image encoders and innovate the interaction between garment and person by proposing CatVTON, a simple and efficient virtual try-on diffusion model. CatVTON facilitates the seamless transfer of in-shop or worn garments of any category to target persons by simply concatenating them in spatial dimensions as inputs. The efficiency of our model is demonstrated in three aspects: (1) Lightweight network: Only the original diffusion modules are used, without additional network modules. The text encoder and cross-attentions for text injection in the backbone are removed, reducing the parameters by 167.02M. (2) Parameter-efficient training: We identified the try-on relevant modules through experiments and achieved high-quality try-on effects by training only 49.57M parameters, approximately 5.51 percent of the backbone network's parameters. (3) Simplified inference: CatVTON eliminates all unnecessary conditions and preprocessing steps, including pose estimation, human parsing, and text input, requiring only a garment reference, target person image, and mask for the virtual try-on process. Extensive experiments demonstrate that CatVTON achieves superior qualitative and quantitative results with fewer prerequisites and trainable parameters than baseline methods. Furthermore, CatVTON shows good generalization in in-the-wild scenarios despite using open-source datasets with only 73K samples.
Construction of a Syntactic Analysis Map for Yi Shui School through Text Mining and Natural Language Processing Research
Feb 16, 2024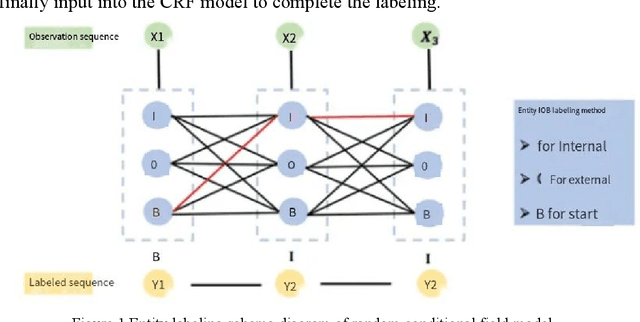
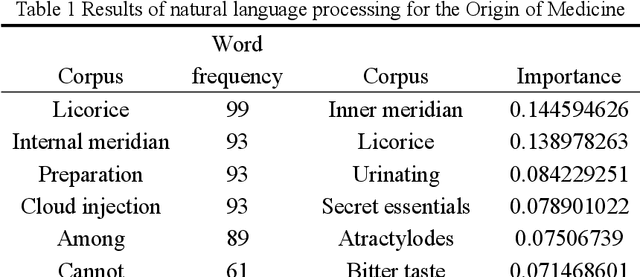
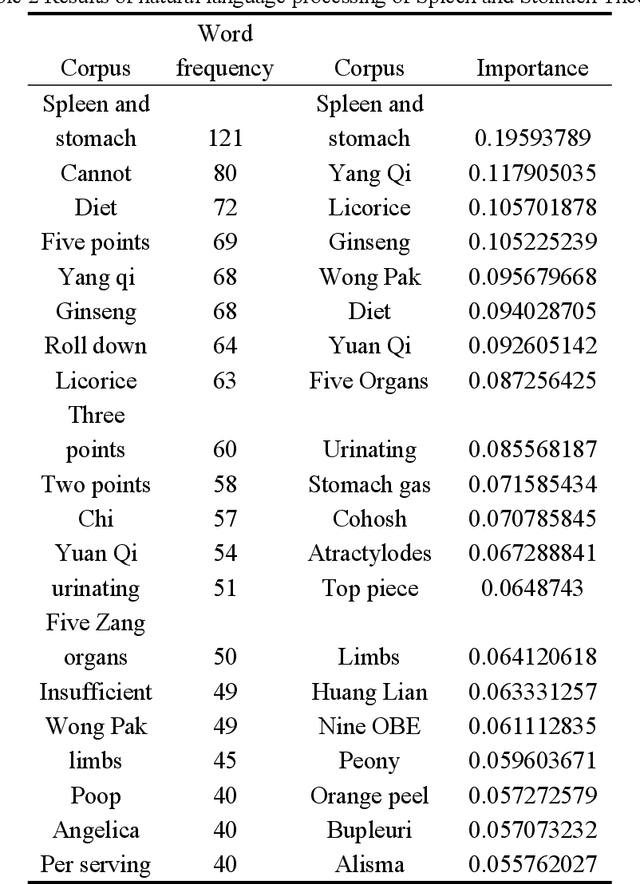

Entity and relationship extraction is a crucial component in natural language processing tasks such as knowledge graph construction, question answering system design, and semantic analysis. Most of the information of the Yishui school of traditional Chinese Medicine (TCM) is stored in the form of unstructured classical Chinese text. The key information extraction of TCM texts plays an important role in mining and studying the academic schools of TCM. In order to solve these problems efficiently using artificial intelligence methods, this study constructs a word segmentation and entity relationship extraction model based on conditional random fields under the framework of natural language processing technology to identify and extract the entity relationship of traditional Chinese medicine texts, and uses the common weighting technology of TF-IDF information retrieval and data mining to extract important key entity information in different ancient books. The dependency syntactic parser based on neural network is used to analyze the grammatical relationship between entities in each ancient book article, and it is represented as a tree structure visualization, which lays the foundation for the next construction of the knowledge graph of Yishui school and the use of artificial intelligence methods to carry out the research of TCM academic schools.
X-Paste: Revisit Copy-Paste at Scale with CLIP and StableDiffusion
Dec 07, 2022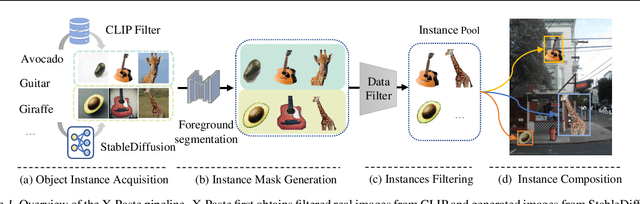



Copy-Paste is a simple and effective data augmentation strategy for instance segmentation. By randomly pasting object instances onto new background images, it creates new training data for free and significantly boosts the segmentation performance, especially for rare object categories. Although diverse, high-quality object instances used in Copy-Paste result in more performance gain, previous works utilize object instances either from human-annotated instance segmentation datasets or rendered from 3D object models, and both approaches are too expensive to scale up to obtain good diversity. In this paper, we revisit Copy-Paste at scale with the power of newly emerged zero-shot recognition models (e.g., CLIP) and text2image models (e.g., StableDiffusion). We demonstrate for the first time that using a text2image model to generate images or zero-shot recognition model to filter noisily crawled images for different object categories is a feasible way to make Copy-Paste truly scalable. To make such success happen, we design a data acquisition and processing framework, dubbed "X-Paste", upon which a systematic study is conducted. On the LVIS dataset, X-Paste provides impressive improvements over the strong baseline CenterNet2 with Swin-L as the backbone. Specifically, it archives +2.6 box AP and +2.1 mask AP gains on all classes and even more significant gains with +6.8 box AP +6.5 mask AP on long-tail classes.