 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopycat vs. Original: Multi-modal Pretraining and Variable Importance in Box-office Prediction
Sep 18, 2025The movie industry is associated with an elevated level of risk, which necessitates the use of automated tools to predict box-office revenue and facilitate human decision-making. In this study, we build a sophisticated multimodal neural network that predicts box offices by grounding crowdsourced descriptive keywords of each movie in the visual information of the movie posters, thereby enhancing the learned keyword representations, resulting in a substantial reduction of 14.5% in box-office prediction error. The advanced revenue prediction model enables the analysis of the commercial viability of "copycat movies," or movies with substantial similarity to successful movies released recently. We do so by computing the influence of copycat features in box-office prediction. We find a positive relationship between copycat status and movie revenue. However, this effect diminishes when the number of similar movies and the similarity of their content increase. Overall, our work develops sophisticated deep learning tools for studying the movie industry and provides valuable business insight.
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025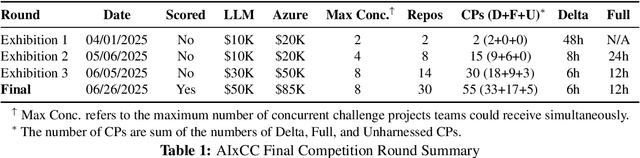
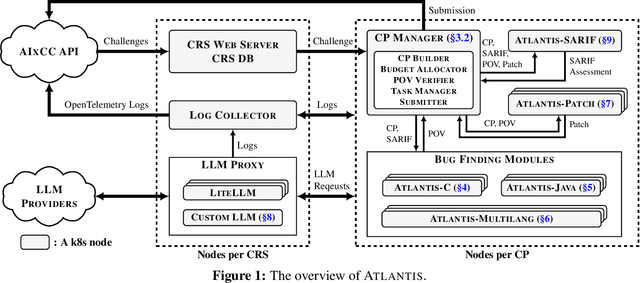
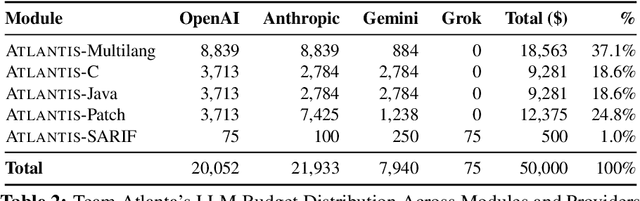
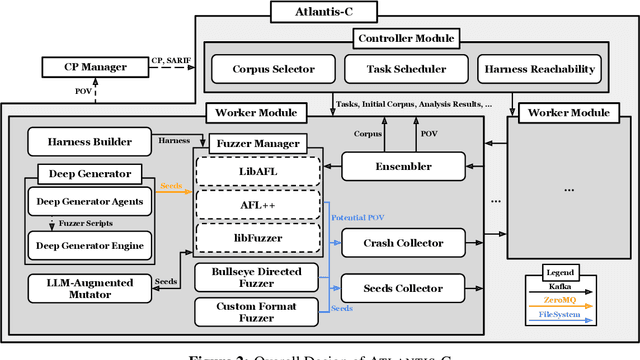
We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
Movie Box Office Prediction With Self-Supervised and Visually Grounded Pretraining
Apr 20, 2023Investments in movie production are associated with a high level of risk as movie revenues have long-tailed and bimodal distributions. Accurate prediction of box-office revenue may mitigate the uncertainty and encourage investment. However, learning effective representations for actors, directors, and user-generated content-related keywords remains a challenging open problem. In this work, we investigate the effects of self-supervised pretraining and propose visual grounding of content keywords in objects from movie posters as a pertaining objective. Experiments on a large dataset of 35,794 movies demonstrate significant benefits of self-supervised training and visual grounding. In particular, visual grounding pretraining substantially improves learning on movies with content keywords and achieves 14.5% relative performance gains compared to a finetuned BERT model with identical architecture.