 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopycat vs. Original: Multi-modal Pretraining and Variable Importance in Box-office Prediction
Sep 18, 2025The movie industry is associated with an elevated level of risk, which necessitates the use of automated tools to predict box-office revenue and facilitate human decision-making. In this study, we build a sophisticated multimodal neural network that predicts box offices by grounding crowdsourced descriptive keywords of each movie in the visual information of the movie posters, thereby enhancing the learned keyword representations, resulting in a substantial reduction of 14.5% in box-office prediction error. The advanced revenue prediction model enables the analysis of the commercial viability of "copycat movies," or movies with substantial similarity to successful movies released recently. We do so by computing the influence of copycat features in box-office prediction. We find a positive relationship between copycat status and movie revenue. However, this effect diminishes when the number of similar movies and the similarity of their content increase. Overall, our work develops sophisticated deep learning tools for studying the movie industry and provides valuable business insight.
STRATA-TS: Selective Knowledge Transfer for Urban Time Series Forecasting with Retrieval-Guided Reasoning
Aug 26, 2025Urban forecasting models often face a severe data imbalance problem: only a few cities have dense, long-span records, while many others expose short or incomplete histories. Direct transfer from data-rich to data-scarce cities is unreliable because only a limited subset of source patterns truly benefits the target domain, whereas indiscriminate transfer risks introducing noise and negative transfer. We present STRATA-TS (Selective TRAnsfer via TArget-aware retrieval for Time Series), a framework that combines domain-adapted retrieval with reasoning-capable large models to improve forecasting in scarce data regimes. STRATA-TS employs a patch-based temporal encoder to identify source subsequences that are semantically and dynamically aligned with the target query. These retrieved exemplars are then injected into a retrieval-guided reasoning stage, where an LLM performs structured inference over target inputs and retrieved support. To enable efficient deployment, we distill the reasoning process into a compact open model via supervised fine-tuning. Extensive experiments on three parking availability datasets across Singapore, Nottingham, and Glasgow demonstrate that STRATA-TS consistently outperforms strong forecasting and transfer baselines, while providing interpretable knowledge transfer pathways.
Two Causally Related Needles in a Video Haystack
May 26, 2025Evaluating the video understanding capabilities of Video-Language Models (VLMs) remains a significant challenge. We propose a long-context video understanding benchmark, Causal2Needles, that assesses two crucial abilities insufficiently evaluated by existing benchmarks: (1) the ability to extract information from two separate locations in a long video and understand them jointly, and (2) the ability to model the world in terms of cause and effect in human behaviors. Specifically, Causal2Needles introduces 2-needle questions, which require extracting information from both the cause and effect human-behavior events in a long video and the associated narration text. To prevent textual bias, these questions comprise two complementary formats: one asking to identify the video clip containing the answer, and one asking for the textual description of an unrelated visual detail from that video clip. Our experiments reveal that models excelling in pre-existing benchmarks struggle with 2-needle visual grounding, and the model performance is negatively correlated with the distance between the two needles. These findings highlight critical limitations in current VLMs.
UrbanLLM: Autonomous Urban Activity Planning and Management with Large Language Models
Jun 18, 2024



Location-based services play an critical role in improving the quality of our daily lives. Despite the proliferation of numerous specialized AI models within spatio-temporal context of location-based services, these models struggle to autonomously tackle problems regarding complex urban planing and management. To bridge this gap, we introduce UrbanLLM, a fine-tuned large language model (LLM) designed to tackle diverse problems in urban scenarios. UrbanLLM functions as a problem-solver by decomposing urban-related queries into manageable sub-tasks, identifying suitable spatio-temporal AI models for each sub-task, and generating comprehensive responses to the given queries. Our experimental results indicate that UrbanLLM significantly outperforms other established LLMs, such as Llama and the GPT series, in handling problems concerning complex urban activity planning and management. UrbanLLM exhibits considerable potential in enhancing the effectiveness of solving problems in urban scenarios, reducing the workload and reliance for human experts.
Event Causality Is Key to Computational Story Understanding
Nov 16, 2023Psychological research suggests the central role of event causality in human story understanding. Further, event causality has been heavily utilized in symbolic story generation. However, few machine learning systems for story understanding employ event causality, partially due to the lack of reliable methods for identifying open-world causal event relations. Leveraging recent progress in large language models (LLMs), we present the first method for event causality identification that leads to material improvements in computational story understanding. We design specific prompts for extracting event causal relations from GPT. Against human-annotated event causal relations in the GLUCOSE dataset, our technique performs on par with supervised models, while being easily generalizable to stories of different types and lengths. The extracted causal relations lead to 5.7\% improvements on story quality evaluation and 8.7\% on story video-text alignment. Our findings indicate enormous untapped potential for event causality in computational story understanding.
Movie Box Office Prediction With Self-Supervised and Visually Grounded Pretraining
Apr 20, 2023Investments in movie production are associated with a high level of risk as movie revenues have long-tailed and bimodal distributions. Accurate prediction of box-office revenue may mitigate the uncertainty and encourage investment. However, learning effective representations for actors, directors, and user-generated content-related keywords remains a challenging open problem. In this work, we investigate the effects of self-supervised pretraining and propose visual grounding of content keywords in objects from movie posters as a pertaining objective. Experiments on a large dataset of 35,794 movies demonstrate significant benefits of self-supervised training and visual grounding. In particular, visual grounding pretraining substantially improves learning on movies with content keywords and achieves 14.5% relative performance gains compared to a finetuned BERT model with identical architecture.
Synopses of Movie Narratives: a Video-Language Dataset for Story Understanding
Mar 11, 2022

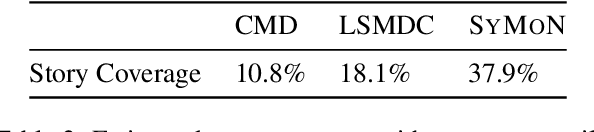
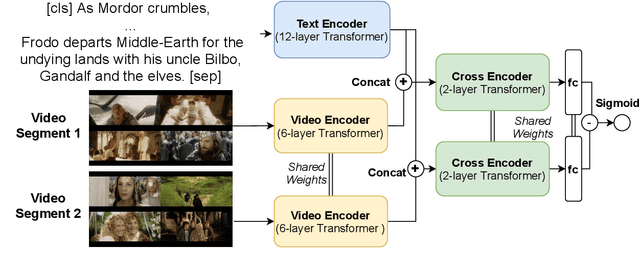
Despite recent advances of AI, story understanding remains an open and under-investigated problem. We collect, preprocess, and publicly release a video-language story dataset, Synopses of Movie Narratives(SyMoN), containing 5,193 video summaries of popular movies and TV series. SyMoN captures naturalistic storytelling videos for human audience made by human creators, and has higher story coverage and more frequent mental-state references than similar video-language story datasets. Differing from most existing video-text datasets, SyMoN features large semantic gaps between the visual and the textual modalities due to the prevalence of reporting bias and mental state descriptions. We establish benchmarks on video-text retrieval and zero-shot alignment on movie summary videos. With SyMoN, we hope to lay the groundwork for progress in multimodal story understanding.