 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Causally Related Needles in a Video Haystack
May 26, 2025Evaluating the video understanding capabilities of Video-Language Models (VLMs) remains a significant challenge. We propose a long-context video understanding benchmark, Causal2Needles, that assesses two crucial abilities insufficiently evaluated by existing benchmarks: (1) the ability to extract information from two separate locations in a long video and understand them jointly, and (2) the ability to model the world in terms of cause and effect in human behaviors. Specifically, Causal2Needles introduces 2-needle questions, which require extracting information from both the cause and effect human-behavior events in a long video and the associated narration text. To prevent textual bias, these questions comprise two complementary formats: one asking to identify the video clip containing the answer, and one asking for the textual description of an unrelated visual detail from that video clip. Our experiments reveal that models excelling in pre-existing benchmarks struggle with 2-needle visual grounding, and the model performance is negatively correlated with the distance between the two needles. These findings highlight critical limitations in current VLMs.
Rationale-based Ensemble of Multiple QA Strategies for Zero-shot Knowledge-based VQA
Jun 18, 2024Knowledge-based Visual Qustion-answering (K-VQA) necessitates the use of background knowledge beyond what is depicted in the image. Current zero-shot K-VQA methods usually translate an image to a single type of textual decision context and use a text-based model to answer the question based on it, which conflicts with the fact that K-VQA questions often require the combination of multiple question-answering strategies. In light of this, we propose Rationale-based Ensemble of Answer Context Tactics (REACT) to achieve a dynamic ensemble of multiple question-answering tactics, comprising Answer Candidate Generation (ACG) and Rationale-based Strategy Fusion (RSF). In ACG, we generate three distinctive decision contexts to provide different strategies for each question, resulting in the generation of three answer candidates. RSF generates automatic and mechanistic rationales from decision contexts for each candidate, allowing the model to select the correct answer from all candidates. We conduct comprehensive experiments on the OK-VQA and A-OKVQA datasets, and our method significantly outperforms state-of-the-art LLM-based baselines on all datasets.
Pixel Adaptive Deep Unfolding Transformer for Hyperspectral Image Reconstruction
Aug 21, 2023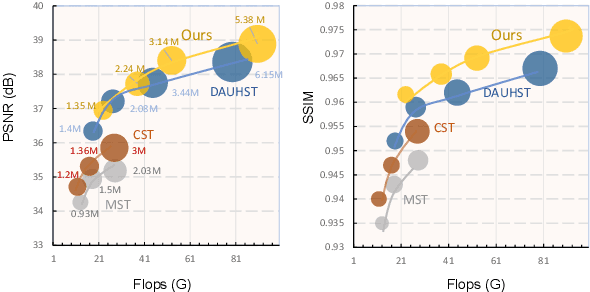



Hyperspectral Image (HSI) reconstruction has made gratifying progress with the deep unfolding framework by formulating the problem into a data module and a prior module. Nevertheless, existing methods still face the problem of insufficient matching with HSI data. The issues lie in three aspects: 1) fixed gradient descent step in the data module while the degradation of HSI is agnostic in the pixel-level. 2) inadequate prior module for 3D HSI cube. 3) stage interaction ignoring the differences in features at different stages. To address these issues, in this work, we propose a Pixel Adaptive Deep Unfolding Transformer (PADUT) for HSI reconstruction. In the data module, a pixel adaptive descent step is employed to focus on pixel-level agnostic degradation. In the prior module, we introduce the Non-local Spectral Transformer (NST) to emphasize the 3D characteristics of HSI for recovering. Moreover, inspired by the diverse expression of features in different stages and depths, the stage interaction is improved by the Fast Fourier Transform (FFT). Experimental results on both simulated and real scenes exhibit the superior performance of our method compared to state-of-the-art HSI reconstruction methods. The code is released at: https://github.com/MyuLi/PADUT.
BEV-DG: Cross-Modal Learning under Bird's-Eye View for Domain Generalization of 3D Semantic Segmentation
Aug 12, 2023Cross-modal Unsupervised Domain Adaptation (UDA) aims to exploit the complementarity of 2D-3D data to overcome the lack of annotation in a new domain. However, UDA methods rely on access to the target domain during training, meaning the trained model only works in a specific target domain. In light of this, we propose cross-modal learning under bird's-eye view for Domain Generalization (DG) of 3D semantic segmentation, called BEV-DG. DG is more challenging because the model cannot access the target domain during training, meaning it needs to rely on cross-modal learning to alleviate the domain gap. Since 3D semantic segmentation requires the classification of each point, existing cross-modal learning is directly conducted point-to-point, which is sensitive to the misalignment in projections between pixels and points. To this end, our approach aims to optimize domain-irrelevant representation modeling with the aid of cross-modal learning under bird's-eye view. We propose BEV-based Area-to-area Fusion (BAF) to conduct cross-modal learning under bird's-eye view, which has a higher fault tolerance for point-level misalignment. Furthermore, to model domain-irrelevant representations, we propose BEV-driven Domain Contrastive Learning (BDCL) with the help of cross-modal learning under bird's-eye view. We design three domain generalization settings based on three 3D datasets, and BEV-DG significantly outperforms state-of-the-art competitors with tremendous margins in all settings.
Spectral Enhanced Rectangle Transformer for Hyperspectral Image Denoising
Apr 03, 2023



Denoising is a crucial step for hyperspectral image (HSI) applications. Though witnessing the great power of deep learning, existing HSI denoising methods suffer from limitations in capturing the non-local self-similarity. Transformers have shown potential in capturing long-range dependencies, but few attempts have been made with specifically designed Transformer to model the spatial and spectral correlation in HSIs. In this paper, we address these issues by proposing a spectral enhanced rectangle Transformer, driving it to explore the non-local spatial similarity and global spectral low-rank property of HSIs. For the former, we exploit the rectangle self-attention horizontally and vertically to capture the non-local similarity in the spatial domain. For the latter, we design a spectral enhancement module that is capable of extracting global underlying low-rank property of spatial-spectral cubes to suppress noise, while enabling the interactions among non-overlapping spatial rectangles. Extensive experiments have been conducted on both synthetic noisy HSIs and real noisy HSIs, showing the effectiveness of our proposed method in terms of both objective metric and subjective visual quality. The code is available at https://github.com/MyuLi/SERT.
Spatial-Spectral Transformer for Hyperspectral Image Denoising
Nov 25, 2022



Hyperspectral image (HSI) denoising is a crucial preprocessing procedure for the subsequent HSI applications. Unfortunately, though witnessing the development of deep learning in HSI denoising area, existing convolution-based methods face the trade-off between computational efficiency and capability to model non-local characteristics of HSI. In this paper, we propose a Spatial-Spectral Transformer (SST) to alleviate this problem. To fully explore intrinsic similarity characteristics in both spatial dimension and spectral dimension, we conduct non-local spatial self-attention and global spectral self-attention with Transformer architecture. The window-based spatial self-attention focuses on the spatial similarity beyond the neighboring region. While, spectral self-attention exploits the long-range dependencies between highly correlative bands. Experimental results show that our proposed method outperforms the state-of-the-art HSI denoising methods in quantitative quality and visual results.