 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnrewarded Exploration in Large Language Models Reveals Latent Learning from Psychology
Jan 30, 2026Latent learning, classically theorized by Tolman, shows that biological agents (e.g., rats) can acquire internal representations of their environment without rewards, enabling rapid adaptation once rewards are introduced. In contrast, from a cognitive science perspective, reward learning remains overly dependent on external feedback, limiting flexibility and generalization. Although recent advances in the reasoning capabilities of large language models (LLMs), such as OpenAI-o1 and DeepSeek-R1, mark a significant breakthrough, these models still rely primarily on reward-centric reinforcement learning paradigms. Whether and how the well-established phenomenon of latent learning in psychology can inform or emerge within LLMs' training remains largely unexplored. In this work, we present novel findings from our experiments that LLMs also exhibit the latent learning dynamics. During an initial phase of unrewarded exploration, LLMs display modest performance improvements, as this phase allows LLMs to organize task-relevant knowledge without being constrained by reward-driven biases, and performance is further enhanced once rewards are introduced. LLMs post-trained under this two-stage exploration regime ultimately achieve higher competence than those post-trained with reward-based reinforcement learning throughout. Beyond these empirical observations, we also provide theoretical analyses for our experiments explaining why unrewarded exploration yields performance gains, offering a mechanistic account of these dynamics. Specifically, we conducted extensive experiments across multiple model families and diverse task domains to establish the existence of the latent learning dynamics in LLMs.
AAPO: Enhance the Reasoning Capabilities of LLMs with Advantage Momentum
May 20, 2025Reinforcement learning (RL) has emerged as an effective approach for enhancing the reasoning capabilities of large language models (LLMs), especially in scenarios where supervised fine-tuning (SFT) falls short due to limited chain-of-thought (CoT) data. Among RL-based post-training methods, group relative advantage estimation, as exemplified by Group Relative Policy Optimization (GRPO), has attracted considerable attention for eliminating the dependency on the value model, thereby simplifying training compared to traditional approaches like Proximal Policy Optimization (PPO). However, we observe that exsiting group relative advantage estimation method still suffers from training inefficiencies, particularly when the estimated advantage approaches zero. To address this limitation, we propose Advantage-Augmented Policy Optimization (AAPO), a novel RL algorithm that optimizes the cross-entropy (CE) loss using advantages enhanced through a momentum-based estimation scheme. This approach effectively mitigates the inefficiencies associated with group relative advantage estimation. Experimental results on multiple mathematical reasoning benchmarks demonstrate the superior performance of AAPO.
Reasoning to Attend: Try to Understand How <SEG> Token Works
Dec 23, 2024Current Large Multimodal Models (LMMs) empowered visual grounding typically rely on $\texttt{<SEG>}$ token as a text prompt to jointly optimize the vision-language model (e.g., LLaVA) and the downstream task-specified model (\eg, SAM). However, we observe that little research has looked into how it works.In this work, we first visualize the similarity maps, which are obtained by computing the semantic similarity between the $\texttt{<SEG>}$ token and the image token embeddings derived from the last hidden layer in both the LLaVA encoder and SAM decoder. Intriguingly, we have found that a striking consistency holds in terms of activation responses in the similarity map,which reveals that what $\texttt{<SEG>}$ token contributes to is the semantic similarity within image-text pairs. Specifically, $\texttt{<SEG>}$ token, a placeholder expanded in text vocabulary, extensively queries among individual tokenized image patches to match the semantics of an object from text to the paired image while the Large Language Models (LLMs) are being fine-tuned. Upon the above findings, we present READ, which facilitates LMMs' resilient $\textbf{REA}$soning capability of where to atten$\textbf{D}$ under the guidance of highly activated points borrowed from similarity maps. Remarkably, READ features an intuitive design, Similarity as Points module (SasP), which can be seamlessly applied to $\texttt{<SEG>}$-like paradigms in a plug-and-play fashion.Also, extensive experiments have been conducted on the ReasonSeg and RefCOCO(+/g) datasets. To validate whether READ suffers from catastrophic forgetting of previous skills after fine-tuning, we further assess its generation ability on an augmented FP-RefCOCO(+/g) dataset. All codes and models are publicly available at https://github.com/rui-qian/READ.
Trustworthy Federated Learning: Privacy, Security, and Beyond
Nov 03, 2024



While recent years have witnessed the advancement in big data and Artificial Intelligence (AI), it is of much importance to safeguard data privacy and security. As an innovative approach, Federated Learning (FL) addresses these concerns by facilitating collaborative model training across distributed data sources without transferring raw data. However, the challenges of robust security and privacy across decentralized networks catch significant attention in dealing with the distributed data in FL. In this paper, we conduct an extensive survey of the security and privacy issues prevalent in FL, underscoring the vulnerability of communication links and the potential for cyber threats. We delve into various defensive strategies to mitigate these risks, explore the applications of FL across different sectors, and propose research directions. We identify the intricate security challenges that arise within the FL frameworks, aiming to contribute to the development of secure and efficient FL systems.
Efficient Federated Learning Using Dynamic Update and Adaptive Pruning with Momentum on Shared Server Data
Aug 11, 2024

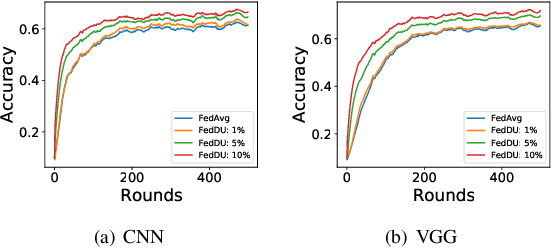
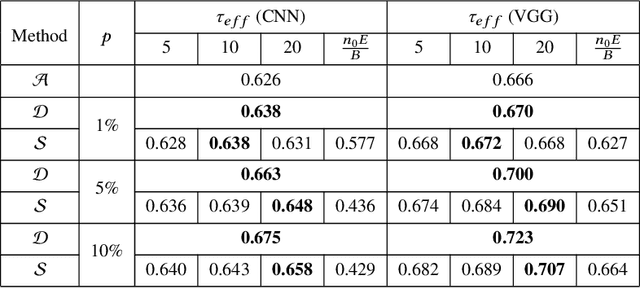
Despite achieving remarkable performance, Federated Learning (FL) encounters two important problems, i.e., low training efficiency and limited computational resources. In this paper, we propose a new FL framework, i.e., FedDUMAP, with three original contributions, to leverage the shared insensitive data on the server in addition to the distributed data in edge devices so as to efficiently train a global model. First, we propose a simple dynamic server update algorithm, which takes advantage of the shared insensitive data on the server while dynamically adjusting the update steps on the server in order to speed up the convergence and improve the accuracy. Second, we propose an adaptive optimization method with the dynamic server update algorithm to exploit the global momentum on the server and each local device for superior accuracy. Third, we develop a layer-adaptive model pruning method to carry out specific pruning operations, which is adapted to the diverse features of each layer so as to attain an excellent trade-off between effectiveness and efficiency. Our proposed FL model, FedDUMAP, combines the three original techniques and has a significantly better performance compared with baseline approaches in terms of efficiency (up to 16.9 times faster), accuracy (up to 20.4% higher), and computational cost (up to 62.6% smaller).
Enhancing Trust and Privacy in Distributed Networks: A Comprehensive Survey on Blockchain-based Federated Learning
Mar 28, 2024



While centralized servers pose a risk of being a single point of failure, decentralized approaches like blockchain offer a compelling solution by implementing a consensus mechanism among multiple entities. Merging distributed computing with cryptographic techniques, decentralized technologies introduce a novel computing paradigm. Blockchain ensures secure, transparent, and tamper-proof data management by validating and recording transactions via consensus across network nodes. Federated Learning (FL), as a distributed machine learning framework, enables participants to collaboratively train models while safeguarding data privacy by avoiding direct raw data exchange. Despite the growing interest in decentralized methods, their application in FL remains underexplored. This paper presents a thorough investigation into Blockchain-based FL (BCFL), spotlighting the synergy between blockchain's security features and FL's privacy-preserving model training capabilities. First, we present the taxonomy of BCFL from three aspects, including decentralized, separate networks, and reputation-based architectures. Then, we summarize the general architecture of BCFL systems, providing a comprehensive perspective on FL architectures informed by blockchain. Afterward, we analyze the application of BCFL in healthcare, IoT, and other privacy-sensitive areas. Finally, we identify future research directions of BCFL.
Efficient Asynchronous Federated Learning with Sparsification and Quantization
Jan 06, 2024While data is distributed in multiple edge devices, Federated Learning (FL) is attracting more and more attention to collaboratively train a machine learning model without transferring raw data. FL generally exploits a parameter server and a large number of edge devices during the whole process of the model training, while several devices are selected in each round. However, straggler devices may slow down the training process or even make the system crash during training. Meanwhile, other idle edge devices remain unused. As the bandwidth between the devices and the server is relatively low, the communication of intermediate data becomes a bottleneck. In this paper, we propose Time-Efficient Asynchronous federated learning with Sparsification and Quantization, i.e., TEASQ-Fed. TEASQ-Fed can fully exploit edge devices to asynchronously participate in the training process by actively applying for tasks. We utilize control parameters to choose an appropriate number of parallel edge devices, which simultaneously execute the training tasks. In addition, we introduce a caching mechanism and weighted averaging with respect to model staleness to further improve the accuracy. Furthermore, we propose a sparsification and quantitation approach to compress the intermediate data to accelerate the training. The experimental results reveal that TEASQ-Fed improves the accuracy (up to 16.67% higher) while accelerating the convergence of model training (up to twice faster).
Dual-space Hierarchical Learning for Goal-guided Conversational Recommendation
Dec 30, 2023

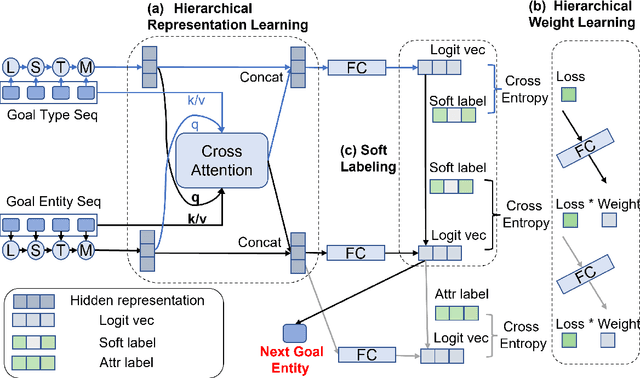

Proactively and naturally guiding the dialog from the non-recommendation context (e.g., Chit-chat) to the recommendation scenario (e.g., Music) is crucial for the Conversational Recommender System (CRS). Prior studies mainly focus on planning the next dialog goal~(e.g., chat on a movie star) conditioned on the previous dialog. However, we find the dialog goals can be simultaneously observed at different levels, which can be utilized to improve CRS. In this paper, we propose Dual-space Hierarchical Learning (DHL) to leverage multi-level goal sequences and their hierarchical relationships for conversational recommendation. Specifically, we exploit multi-level goal sequences from both the representation space and the optimization space. In the representation space, we propose the hierarchical representation learning where a cross attention module derives mutually enhanced multi-level goal representations. In the optimization space, we devise the hierarchical weight learning to reweight lower-level goal sequences, and introduce bi-level optimization for stable update. Additionally, we propose a soft labeling strategy to guide optimization gradually. Experiments on two real-world datasets verify the effectiveness of our approach. Code and data are available here.
AEDFL: Efficient Asynchronous Decentralized Federated Learning with Heterogeneous Devices
Dec 18, 2023Federated Learning (FL) has achieved significant achievements recently, enabling collaborative model training on distributed data over edge devices. Iterative gradient or model exchanges between devices and the centralized server in the standard FL paradigm suffer from severe efficiency bottlenecks on the server. While enabling collaborative training without a central server, existing decentralized FL approaches either focus on the synchronous mechanism that deteriorates FL convergence or ignore device staleness with an asynchronous mechanism, resulting in inferior FL accuracy. In this paper, we propose an Asynchronous Efficient Decentralized FL framework, i.e., AEDFL, in heterogeneous environments with three unique contributions. First, we propose an asynchronous FL system model with an efficient model aggregation method for improving the FL convergence. Second, we propose a dynamic staleness-aware model update approach to achieve superior accuracy. Third, we propose an adaptive sparse training method to reduce communication and computation costs without significant accuracy degradation. Extensive experimentation on four public datasets and four models demonstrates the strength of AEDFL in terms of accuracy (up to 16.3% higher), efficiency (up to 92.9% faster), and computation costs (up to 42.3% lower).
On Mask-based Image Set Desensitization with Recognition Support
Dec 14, 2023In recent years, Deep Neural Networks (DNN) have emerged as a practical method for image recognition. The raw data, which contain sensitive information, are generally exploited within the training process. However, when the training process is outsourced to a third-party organization, the raw data should be desensitized before being transferred to protect sensitive information. Although masks are widely applied to hide important sensitive information, preventing inpainting masked images is critical, which may restore the sensitive information. The corresponding models should be adjusted for the masked images to reduce the degradation of the performance for recognition or classification tasks due to the desensitization of images. In this paper, we propose a mask-based image desensitization approach while supporting recognition. This approach consists of a mask generation algorithm and a model adjustment method. We propose exploiting an interpretation algorithm to maintain critical information for the recognition task in the mask generation algorithm. In addition, we propose a feature selection masknet as the model adjustment method to improve the performance based on the masked images. Extensive experimentation results based on multiple image datasets reveal significant advantages (up to 9.34% in terms of accuracy) of our approach for image desensitization while supporting recognition.