 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Asynchronous Federated Learning with Sparsification and Quantization
Jan 06, 2024While data is distributed in multiple edge devices, Federated Learning (FL) is attracting more and more attention to collaboratively train a machine learning model without transferring raw data. FL generally exploits a parameter server and a large number of edge devices during the whole process of the model training, while several devices are selected in each round. However, straggler devices may slow down the training process or even make the system crash during training. Meanwhile, other idle edge devices remain unused. As the bandwidth between the devices and the server is relatively low, the communication of intermediate data becomes a bottleneck. In this paper, we propose Time-Efficient Asynchronous federated learning with Sparsification and Quantization, i.e., TEASQ-Fed. TEASQ-Fed can fully exploit edge devices to asynchronously participate in the training process by actively applying for tasks. We utilize control parameters to choose an appropriate number of parallel edge devices, which simultaneously execute the training tasks. In addition, we introduce a caching mechanism and weighted averaging with respect to model staleness to further improve the accuracy. Furthermore, we propose a sparsification and quantitation approach to compress the intermediate data to accelerate the training. The experimental results reveal that TEASQ-Fed improves the accuracy (up to 16.67% higher) while accelerating the convergence of model training (up to twice faster).
Multi-Job Intelligent Scheduling with Cross-Device Federated Learning
Nov 24, 2022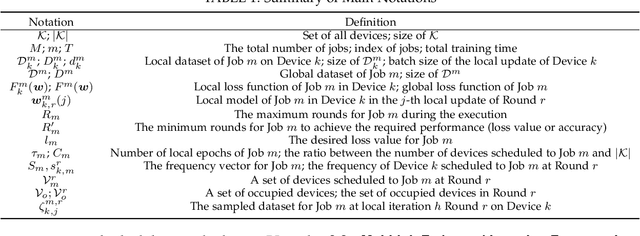
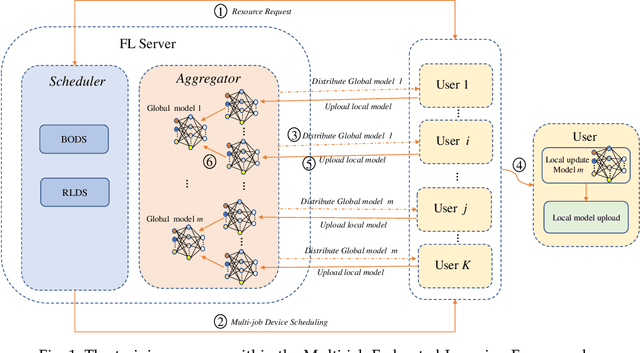
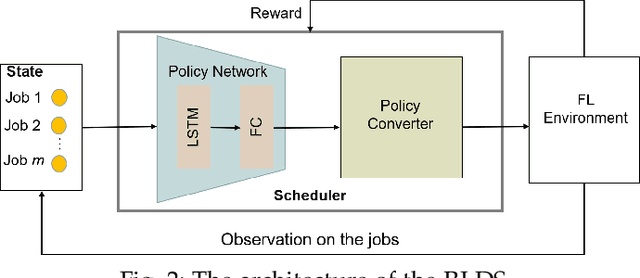
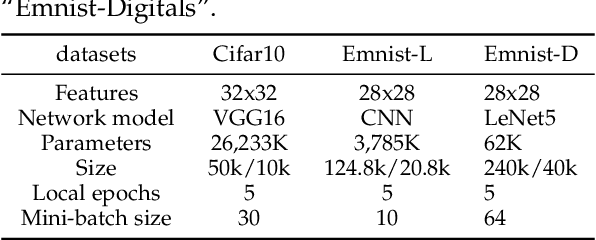
Recent years have witnessed a large amount of decentralized data in various (edge) devices of end-users, while the decentralized data aggregation remains complicated for machine learning jobs because of regulations and laws. As a practical approach to handling decentralized data, Federated Learning (FL) enables collaborative global machine learning model training without sharing sensitive raw data. The servers schedule devices to jobs within the training process of FL. In contrast, device scheduling with multiple jobs in FL remains a critical and open problem. In this paper, we propose a novel multi-job FL framework, which enables the training process of multiple jobs in parallel. The multi-job FL framework is composed of a system model and a scheduling method. The system model enables a parallel training process of multiple jobs, with a cost model based on the data fairness and the training time of diverse devices during the parallel training process. We propose a novel intelligent scheduling approach based on multiple scheduling methods, including an original reinforcement learning-based scheduling method and an original Bayesian optimization-based scheduling method, which corresponds to a small cost while scheduling devices to multiple jobs. We conduct extensive experimentation with diverse jobs and datasets. The experimental results reveal that our proposed approaches significantly outperform baseline approaches in terms of training time (up to 12.73 times faster) and accuracy (up to 46.4% higher).
Efficient Device Scheduling with Multi-Job Federated Learning
Dec 15, 2021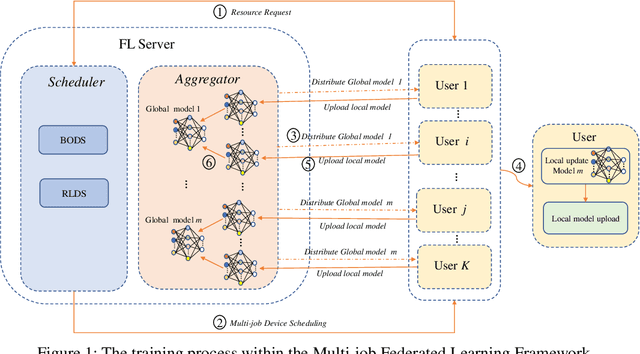
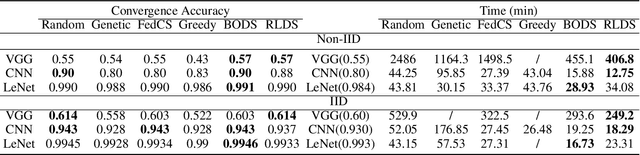
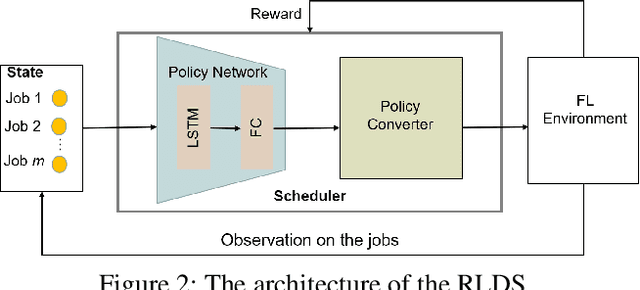
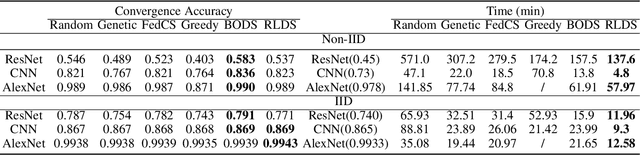
Recent years have witnessed a large amount of decentralized data in multiple (edge) devices of end-users, while the aggregation of the decentralized data remains difficult for machine learning jobs due to laws or regulations. Federated Learning (FL) emerges as an effective approach to handling decentralized data without sharing the sensitive raw data, while collaboratively training global machine learning models. The servers in FL need to select (and schedule) devices during the training process. However, the scheduling of devices for multiple jobs with FL remains a critical and open problem. In this paper, we propose a novel multi-job FL framework to enable the parallel training process of multiple jobs. The framework consists of a system model and two scheduling methods. In the system model, we propose a parallel training process of multiple jobs, and construct a cost model based on the training time and the data fairness of various devices during the training process of diverse jobs. We propose a reinforcement learning-based method and a Bayesian optimization-based method to schedule devices for multiple jobs while minimizing the cost. We conduct extensive experimentation with multiple jobs and datasets. The experimental results show that our proposed approaches significantly outperform baseline approaches in terms of training time (up to 8.67 times faster) and accuracy (up to 44.6% higher).