 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Protocol: A Coordination Layer for Agentic Society
May 22, 2026Autonomous agents are moving from tools into a layer of social infrastructure: they browse, purchase, deploy software, manage systems, and increasingly interact with one another. As these systems scale, the bottleneck shifts away from raw model capability toward coordination. Agents need to form reliable relationships, organize multi-agent work, exchange value, support an AI economy, and stay safe and accountable under real-world oversight. This paper introduces the Foundation Protocol (FP), a graph-first coordination layer for an emerging human-AI society. FP unifies heterogeneous entities, including agents, tools, resources, humans, institutions, and organizations, and supports native multi-party organization and event-based collaboration. It also provides economic primitives for metering, receipts, and settlement, and treats policy, provenance, and audit as first-class concerns. FP is designed to wrap and bridge existing protocols rather than replace them, enabling incremental adoption while reducing integration and governance overhead. The aim is to keep autonomous agency composable while keeping accountability non-negotiable, so that coordination itself can become shared infrastructure for a human-AI society that is open, pluralistic, and governable.
Neural Operators for Multi-Task Control and Adaptation
Apr 03, 2026Neural operator methods have emerged as powerful tools for learning mappings between infinite-dimensional function spaces, yet their potential in optimal control remains largely unexplored. We focus on multi-task control problems, whose solution is a mapping from task description (e.g., cost or dynamics functions) to optimal control law (e.g., feedback policy). We approximate these solution operators using a permutation-invariant neural operator architecture. Across a range of parametric optimal control environments and a locomotion benchmark, a single operator trained via behavioral cloning accurately approximates the solution operator and generalizes to unseen tasks, out-of-distribution settings, and varying amounts of task observations. We further show that the branch-trunk structure of our neural operator architecture enables efficient and flexible adaptation to new tasks. We develop structured adaptation strategies ranging from lightweight updates to full-network fine-tuning, achieving strong performance across different data and compute settings. Finally, we introduce meta-trained operator variants that optimize the initialization for few-shot adaptation. These methods enable rapid task adaptation with limited data and consistently outperform a popular meta-learning baseline. Together, our results demonstrate that neural operators provide a unified and efficient framework for multi-task control and adaptation.
Mind the Rarities: Can Rare Skin Diseases Be Reliably Diagnosed via Diagnostic Reasoning?
Mar 19, 2026Large vision-language models (LVLMs) demonstrate strong performance in dermatology; however, evaluating diagnostic reasoning for rare conditions remains largely unexplored. Existing benchmarks focus on common diseases and assess only final accuracy, overlooking the clinical reasoning process, which is critical for complex cases. We address this gap by constructing DermCase, a long-context benchmark derived from peer-reviewed case reports. Our dataset contains 26,030 multi-modal image-text pairs and 6,354 clinically challenging cases, each annotated with comprehensive clinical information and step-by-step reasoning chains. To enable reliable evaluation, we establish DermLIP-based similarity metrics that achieve stronger alignment with dermatologists for assessing differential diagnosis quality. Benchmarking 22 leading LVLMs exposes significant deficiencies across diagnosis accuracy, differential diagnosis, and clinical reasoning. Fine-tuning experiments demonstrate that instruction tuning substantially improves performance while Direct Preference Optimization (DPO) yields minimal gains. Systematic error analysis further reveals critical limitations in current models' reasoning capabilities.
Beyond Medical Diagnostics: How Medical Multimodal Large Language Models Think in Space
Mar 14, 2026Visual spatial intelligence is critical for medical image interpretation, yet remains largely unexplored in Multimodal Large Language Models (MLLMs) for 3D imaging. This gap persists due to a systemic lack of datasets featuring structured 3D spatial annotations beyond basic labels. In this study, we introduce an agentic pipeline that autonomously synthesizes spatial visual question-answering (VQA) data by orchestrating computational tools such as volume and distance calculators with multi-agent collaboration and expert radiologist validation. We present SpatialMed, the first comprehensive benchmark for evaluating 3D spatial intelligence in medical MLLMs, comprising nearly 10K question-answer pairs across multiple organs and tumor types. Our evaluations on 14 state-of-the-art MLLMs and extensive analyses reveal that current models lack robust spatial reasoning capabilities for medical imaging.
SKETCH: Semantic Key-Point Conditioning for Long-Horizon Vessel Trajectory Prediction
Jan 26, 2026Accurate long-horizon vessel trajectory prediction remains challenging due to compounded uncertainty from complex navigation behaviors and environmental factors. Existing methods often struggle to maintain global directional consistency, leading to drifting or implausible trajectories when extrapolated over long time horizons. To address this issue, we propose a semantic-key-point-conditioned trajectory modeling framework, in which future trajectories are predicted by conditioning on a high-level Next Key Point (NKP) that captures navigational intent. This formulation decomposes long-horizon prediction into global semantic decision-making and local motion modeling, effectively restricting the support of future trajectories to semantically feasible subsets. To efficiently estimate the NKP prior from historical observations, we adopt a pretrain-finetune strategy. Extensive experiments on real-world AIS data demonstrate that the proposed method consistently outperforms state-of-the-art approaches, particularly for long travel durations, directional accuracy, and fine-grained trajectory prediction.
From Specialist to Generalist: Unlocking SAM's Learning Potential on Unlabeled Medical Images
Jan 25, 2026Foundation models like the Segment Anything Model (SAM) show strong generalization, yet adapting them to medical images remains difficult due to domain shift, scarce labels, and the inability of Parameter-Efficient Fine-Tuning (PEFT) to exploit unlabeled data. While conventional models like U-Net excel in semi-supervised medical learning, their potential to assist a PEFT SAM has been largely overlooked. We introduce SC-SAM, a specialist-generalist framework where U-Net provides point-based prompts and pseudo-labels to guide SAM's adaptation, while SAM serves as a powerful generalist supervisor to regularize U-Net. This reciprocal guidance forms a bidirectional co-training loop that allows both models to effectively exploit the unlabeled data. Across prostate MRI and polyp segmentation benchmarks, our method achieves state-of-the-art results, outperforming other existing semi-supervised SAM variants and even medical foundation models like MedSAM, highlighting the value of specialist-generalist cooperation for label-efficient medical image segmentation. Our code is available at https://github.com/vnlvi2k3/SC-SAM.
Zero-Shot Function Encoder-Based Differentiable Predictive Control
Nov 11, 2025We introduce a differentiable framework for zero-shot adaptive control over parametric families of nonlinear dynamical systems. Our approach integrates a function encoder-based neural ODE (FE-NODE) for modeling system dynamics with a differentiable predictive control (DPC) for offline self-supervised learning of explicit control policies. The FE-NODE captures nonlinear behaviors in state transitions and enables zero-shot adaptation to new systems without retraining, while the DPC efficiently learns control policies across system parameterizations, thus eliminating costly online optimization common in classical model predictive control. We demonstrate the efficiency, accuracy, and online adaptability of the proposed method across a range of nonlinear systems with varying parametric scenarios, highlighting its potential as a general-purpose tool for fast zero-shot adaptive control.
DiLO: Disentangled Latent Optimization for Learning Shape and Deformation in Grouped Deforming 3D Objects
Nov 08, 2025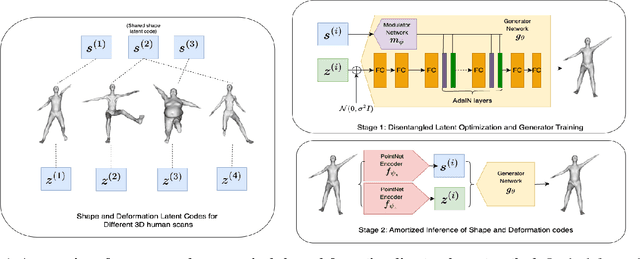
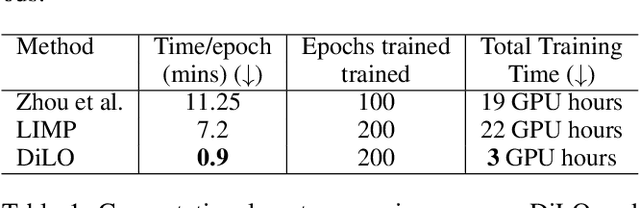

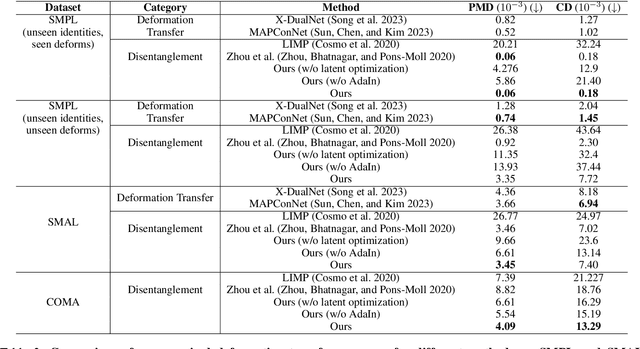
In this work, we propose a disentangled latent optimization-based method for parameterizing grouped deforming 3D objects into shape and deformation factors in an unsupervised manner. Our approach involves the joint optimization of a generator network along with the shape and deformation factors, supported by specific regularization techniques. For efficient amortized inference of disentangled shape and deformation codes, we train two order-invariant PoinNet-based encoder networks in the second stage of our method. We demonstrate several significant downstream applications of our method, including unsupervised deformation transfer, deformation classification, and explainability analysis. Extensive experiments conducted on 3D human, animal, and facial expression datasets demonstrate that our simple approach is highly effective in these downstream tasks, comparable or superior to existing methods with much higher complexity.
Semi-MoE: Mixture-of-Experts meets Semi-Supervised Histopathology Segmentation
Sep 17, 2025Semi-supervised learning has been employed to alleviate the need for extensive labeled data for histopathology image segmentation, but existing methods struggle with noisy pseudo-labels due to ambiguous gland boundaries and morphological misclassification. This paper introduces Semi-MOE, to the best of our knowledge, the first multi-task Mixture-of-Experts framework for semi-supervised histopathology image segmentation. Our approach leverages three specialized expert networks: A main segmentation expert, a signed distance field regression expert, and a boundary prediction expert, each dedicated to capturing distinct morphological features. Subsequently, the Multi-Gating Pseudo-labeling module dynamically aggregates expert features, enabling a robust fuse-and-refine pseudo-labeling mechanism. Furthermore, to eliminate manual tuning while dynamically balancing multiple learning objectives, we propose an Adaptive Multi-Objective Loss. Extensive experiments on GlaS and CRAG benchmarks show that our method outperforms state-of-the-art approaches in low-label settings, highlighting the potential of MoE-based architectures in advancing semi-supervised segmentation. Our code is available at https://github.com/vnlvi2k3/Semi-MoE.
Describe Anything Model for Visual Question Answering on Text-rich Images
Jul 16, 2025Recent progress has been made in region-aware vision-language modeling, particularly with the emergence of the Describe Anything Model (DAM). DAM is capable of generating detailed descriptions of any specific image areas or objects without the need for additional localized image-text alignment supervision. We hypothesize that such region-level descriptive capability is beneficial for the task of Visual Question Answering (VQA), especially in challenging scenarios involving images with dense text. In such settings, the fine-grained extraction of textual information is crucial to producing correct answers. Motivated by this, we introduce DAM-QA, a framework with a tailored evaluation protocol, developed to investigate and harness the region-aware capabilities from DAM for the text-rich VQA problem that requires reasoning over text-based information within images. DAM-QA incorporates a mechanism that aggregates answers from multiple regional views of image content, enabling more effective identification of evidence that may be tied to text-related elements. Experiments on six VQA benchmarks show that our approach consistently outperforms the baseline DAM, with a notable 7+ point gain on DocVQA. DAM-QA also achieves the best overall performance among region-aware models with fewer parameters, significantly narrowing the gap with strong generalist VLMs. These results highlight the potential of DAM-like models for text-rich and broader VQA tasks when paired with efficient usage and integration strategies. Our code is publicly available at https://github.com/Linvyl/DAM-QA.git.