 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-MoE: Mixture-of-Experts meets Semi-Supervised Histopathology Segmentation
Sep 17, 2025Semi-supervised learning has been employed to alleviate the need for extensive labeled data for histopathology image segmentation, but existing methods struggle with noisy pseudo-labels due to ambiguous gland boundaries and morphological misclassification. This paper introduces Semi-MOE, to the best of our knowledge, the first multi-task Mixture-of-Experts framework for semi-supervised histopathology image segmentation. Our approach leverages three specialized expert networks: A main segmentation expert, a signed distance field regression expert, and a boundary prediction expert, each dedicated to capturing distinct morphological features. Subsequently, the Multi-Gating Pseudo-labeling module dynamically aggregates expert features, enabling a robust fuse-and-refine pseudo-labeling mechanism. Furthermore, to eliminate manual tuning while dynamically balancing multiple learning objectives, we propose an Adaptive Multi-Objective Loss. Extensive experiments on GlaS and CRAG benchmarks show that our method outperforms state-of-the-art approaches in low-label settings, highlighting the potential of MoE-based architectures in advancing semi-supervised segmentation. Our code is available at https://github.com/vnlvi2k3/Semi-MoE.
SHREC 2025: Protein surface shape retrieval including electrostatic potential
Sep 16, 2025



This SHREC 2025 track dedicated to protein surface shape retrieval involved 9 participating teams. We evaluated the performance in retrieval of 15 proposed methods on a large dataset of 11,555 protein surfaces with calculated electrostatic potential (a key molecular surface descriptor). The performance in retrieval of the proposed methods was evaluated through different metrics (Accuracy, Balanced accuracy, F1 score, Precision and Recall). The best retrieval performance was achieved by the proposed methods that used the electrostatic potential complementary to molecular surface shape. This observation was also valid for classes with limited data which highlights the importance of taking into account additional molecular surface descriptors.
* Published in Computers & Graphics, Elsevier. 59 pages, 12 figures
Vox-UDA: Voxel-wise Unsupervised Domain Adaptation for Cryo-Electron Subtomogram Segmentation with Denoised Pseudo Labeling
Jun 25, 2024Cryo-Electron Tomography (cryo-ET) is a 3D imaging technology facilitating the study of macromolecular structures at near-atomic resolution. Recent volumetric segmentation approaches on cryo-ET images have drawn widespread interest in biological sector. However, existing methods heavily rely on manually labeled data, which requires highly professional skills, thereby hindering the adoption of fully-supervised approaches for cryo-ET images. Some unsupervised domain adaptation (UDA) approaches have been designed to enhance the segmentation network performance using unlabeled data. However, applying these methods directly to cryo-ET images segmentation tasks remains challenging due to two main issues: 1) the source data, usually obtained through simulation, contain a certain level of noise, while the target data, directly collected from raw-data from real-world scenario, have unpredictable noise levels. 2) the source data used for training typically consists of known macromoleculars, while the target domain data are often unknown, causing the model's segmenter to be biased towards these known macromolecules, leading to a domain shift problem. To address these challenges, in this work, we introduce the first voxel-wise unsupervised domain adaptation approach, termed Vox-UDA, specifically for cryo-ET subtomogram segmentation. Vox-UDA incorporates a noise generation module to simulate target-like noises in the source dataset for cross-noise level adaptation. Additionally, we propose a denoised pseudo-labeling strategy based on improved Bilateral Filter to alleviate the domain shift problem. Experimental results on both simulated and real cryo-ET subtomogram datasets demonstrate the superiority of our proposed approach compared to state-of-the-art UDA methods.
Fusion of regional and sparse attention in Vision Transformers
Jun 13, 2024Modern vision transformers leverage visually inspired local interaction between pixels through attention computed within window or grid regions, in contrast to the global attention employed in the original ViT. Regional attention restricts pixel interactions within specific regions, while sparse attention disperses them across sparse grids. These differing approaches pose a challenge between maintaining hierarchical relationships vs. capturing a global context. In this study, drawing inspiration from atrous convolution, we propose Atrous Attention, a blend of regional and sparse attention that dynamically integrates both local and global information while preserving hierarchical structures. Based on this, we introduce a versatile, hybrid vision transformer backbone called ACC-ViT, tailored for standard vision tasks. Our compact model achieves approximately 84% accuracy on ImageNet-1K with fewer than 28.5 million parameters, outperforming the state-of-the-art MaxViT by 0.42% while requiring 8.4% fewer parameters.
ACC-ViT : Atrous Convolution's Comeback in Vision Transformers
Mar 07, 2024Transformers have elevated to the state-of-the-art vision architectures through innovations in attention mechanism inspired from visual perception. At present two classes of attentions prevail in vision transformers, regional and sparse attention. The former bounds the pixel interactions within a region; the latter spreads them across sparse grids. The opposing natures of them have resulted in a dilemma between either preserving hierarchical relation or attaining a global context. In this work, taking inspiration from atrous convolution, we introduce Atrous Attention, a fusion of regional and sparse attention, which can adaptively consolidate both local and global information, while maintaining hierarchical relations. As a further tribute to atrous convolution, we redesign the ubiquitous inverted residual convolution blocks with atrous convolution. Finally, we propose a generalized, hybrid vision transformer backbone, named ACC-ViT, following conventional practices for standard vision tasks. Our tiny version model achieves $\sim 84 \%$ accuracy on ImageNet-1K, with less than $28.5$ million parameters, which is $0.42\%$ improvement over state-of-the-art MaxViT while having $8.4\%$ less parameters. In addition, we have investigated the efficacy of ACC-ViT backbone under different evaluation settings, such as finetuning, linear probing, and zero-shot learning on tasks involving medical image analysis, object detection, and language-image contrastive learning. ACC-ViT is therefore a strong vision backbone, which is also competitive in mobile-scale versions, ideal for niche applications with small datasets.
ACC-UNet: A Completely Convolutional UNet model for the 2020s
Aug 25, 2023This decade is marked by the introduction of Vision Transformer, a radical paradigm shift in broad computer vision. A similar trend is followed in medical imaging, UNet, one of the most influential architectures, has been redesigned with transformers. Recently, the efficacy of convolutional models in vision is being reinvestigated by seminal works such as ConvNext, which elevates a ResNet to Swin Transformer level. Deriving inspiration from this, we aim to improve a purely convolutional UNet model so that it can be on par with the transformer-based models, e.g, Swin-Unet or UCTransNet. We examined several advantages of the transformer-based UNet models, primarily long-range dependencies and cross-level skip connections. We attempted to emulate them through convolution operations and thus propose, ACC-UNet, a completely convolutional UNet model that brings the best of both worlds, the inherent inductive biases of convnets with the design decisions of transformers. ACC-UNet was evaluated on 5 different medical image segmentation benchmarks and consistently outperformed convnets, transformers, and their hybrids. Notably, ACC-UNet outperforms state-of-the-art models Swin-Unet and UCTransNet by $2.64 \pm 2.54\%$ and $0.45 \pm 1.61\%$ in terms of dice score, respectively, while using a fraction of their parameters ($59.26\%$ and $24.24\%$). Our codes are available at https://github.com/kiharalab/ACC-UNet.
On the Importance of Asymmetry for Siamese Representation Learning
Apr 01, 2022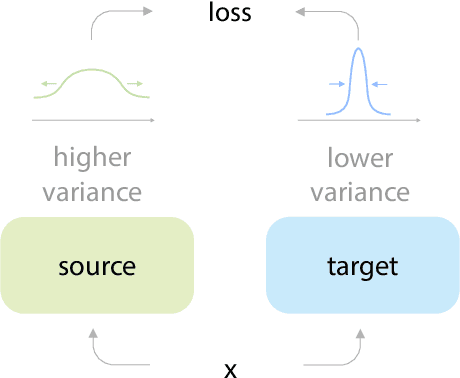



Many recent self-supervised frameworks for visual representation learning are based on certain forms of Siamese networks. Such networks are conceptually symmetric with two parallel encoders, but often practically asymmetric as numerous mechanisms are devised to break the symmetry. In this work, we conduct a formal study on the importance of asymmetry by explicitly distinguishing the two encoders within the network -- one produces source encodings and the other targets. Our key insight is keeping a relatively lower variance in target than source generally benefits learning. This is empirically justified by our results from five case studies covering different variance-oriented designs, and is aligned with our preliminary theoretical analysis on the baseline. Moreover, we find the improvements from asymmetric designs generalize well to longer training schedules, multiple other frameworks and newer backbones. Finally, the combined effect of several asymmetric designs achieves a state-of-the-art accuracy on ImageNet linear probing and competitive results on downstream transfer. We hope our exploration will inspire more research in exploiting asymmetry for Siamese representation learning.
SHREC 2021: Classification in cryo-electron tomograms
Mar 18, 2022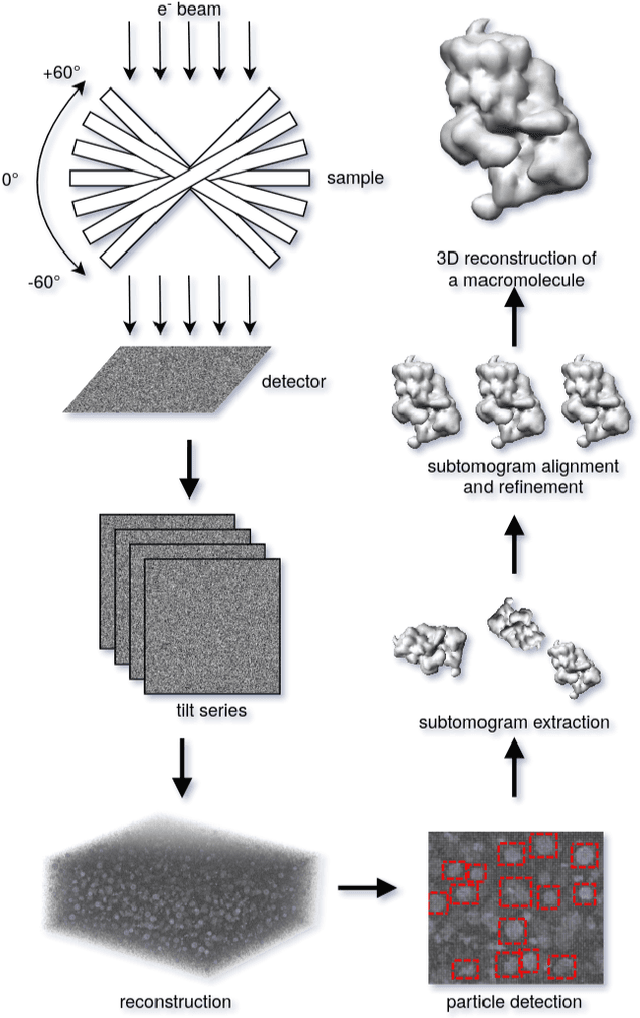
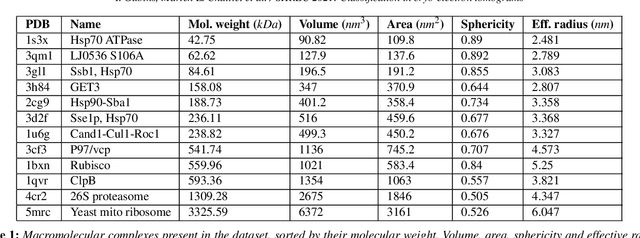
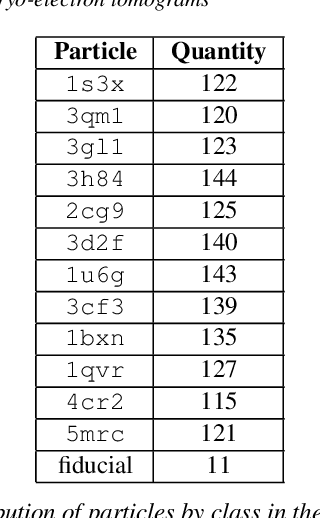
Cryo-electron tomography (cryo-ET) is an imaging technique that allows three-dimensional visualization of macro-molecular assemblies under near-native conditions. Cryo-ET comes with a number of challenges, mainly low signal-to-noise and inability to obtain images from all angles. Computational methods are key to analyze cryo-electron tomograms. To promote innovation in computational methods, we generate a novel simulated dataset to benchmark different methods of localization and classification of biological macromolecules in tomograms. Our publicly available dataset contains ten tomographic reconstructions of simulated cell-like volumes. Each volume contains twelve different types of complexes, varying in size, function and structure. In this paper, we have evaluated seven different methods of finding and classifying proteins. Seven research groups present results obtained with learning-based methods and trained on the simulated dataset, as well as a baseline template matching (TM), a traditional method widely used in cryo-ET research. We show that learning-based approaches can achieve notably better localization and classification performance than TM. We also experimentally confirm that there is a negative relationship between particle size and performance for all methods.
EnAET: Self-Trained Ensemble AutoEncoding Transformations for Semi-Supervised Learning
Nov 21, 2019


Deep neural networks have been successfully applied to many real-world applications. However, these successes rely heavily on large amounts of labeled data, which is expensive to obtain. Recently, Auto-Encoding Transformation (AET) and MixMatch have been proposed and achieved state-of-the-art results for unsupervised and semi-supervised learning, respectively. In this study, we train an Ensemble of Auto-Encoding Transformations (EnAET) to learn from both labeled and unlabeled data based on the embedded representations by decoding both spatial and non-spatial transformations. This distinguishes EnAET from conventional semi-supervised methods that focus on improving prediction consistency and confidence by different models on both unlabeled and labeled examples. In contrast, we propose to explore the role of self-supervised representations in semi-supervised learning under a rich family of transformations. Experiment results on CIFAR-10, CIFAR-100, SVHN and STL10 demonstrate that the proposed EnAET outperforms the state-of-the-art semi-supervised methods by significant margins. In particular, we apply the proposed method to extremely challenging scenarios with only 10 images per class, and show that EnAET can achieve an error rate of 9.35% on CIFAR-10 and 16.92% on SVHN. In addition, EnAET achieves the best result when compared with fully supervised learning using all labeled data with the same network architecture. The performance on CIFAR-10, CIFAR-100 and SVHN with a smaller network is even more competitive than the state-of-the-art of supervised learning methods based on a larger network. We also set a new performance record with an error rate of 1.99% on CIFAR-10 and 4.52% on STL10. The code and experiment records are released at https://github.com/maple-research-lab/EnAET.
A Simple but Effective BERT Model for Dialog State Tracking on Resource-Limited Systems
Oct 28, 2019

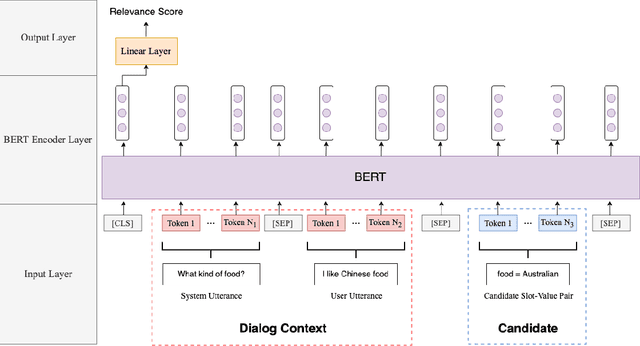
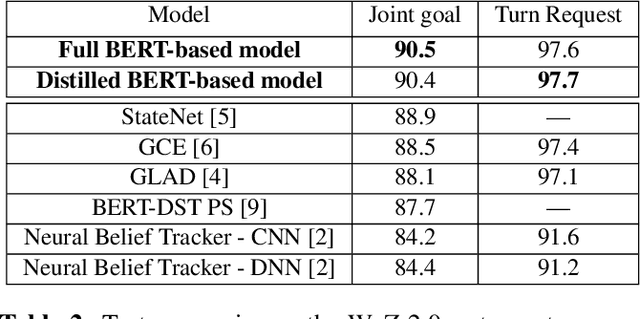
In a task-oriented dialog system, the goal of dialog state tracking (DST) is to monitor the state of the conversation from the dialog history. Recently, many deep learning based methods have been proposed for the task. Despite their impressive performance, current neural architectures for DST are typically heavily-engineered and conceptually complex, making it difficult to implement, debug, and maintain them in a production setting. In this work, we propose a simple but effective DST model based on BERT. In addition to its simplicity, our approach also has a number of other advantages: (a) the number of parameters does not grow with the ontology size (b) the model can operate in situations where the domain ontology may change dynamically. Experimental results demonstrate that our BERT-based model outperforms previous methods by a large margin, achieving new state-of-the-art results on the standard WoZ 2.0 dataset. Finally, to make the model small and fast enough for resource-restricted systems, we apply the knowledge distillation method to compress our model. The final compressed model achieves comparable results with the original model while being 8x smaller and 7x faster.