 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHREC 2021: Classification in cryo-electron tomograms
Mar 18, 2022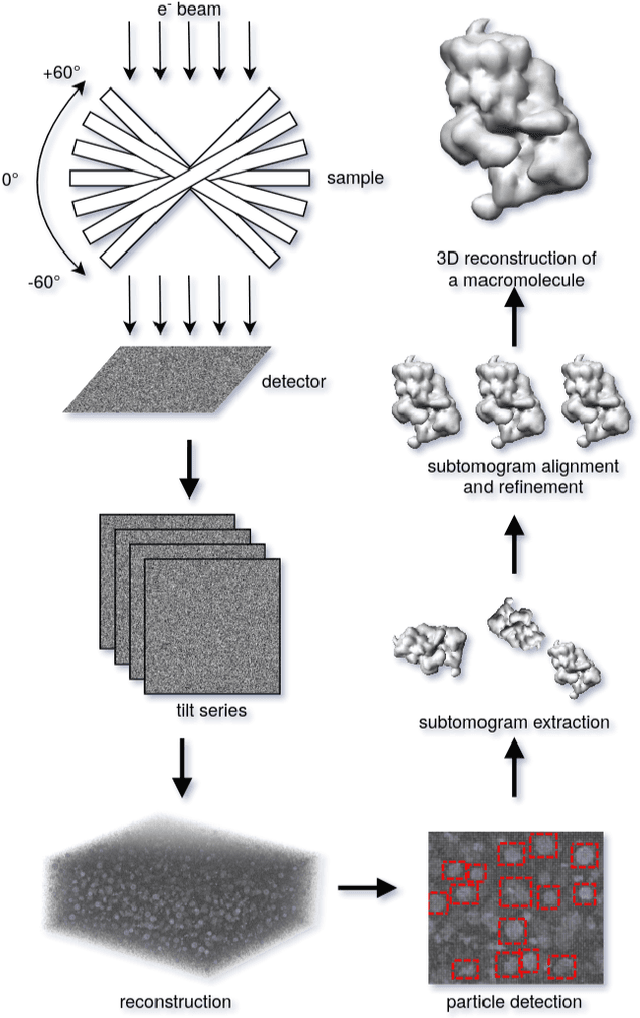
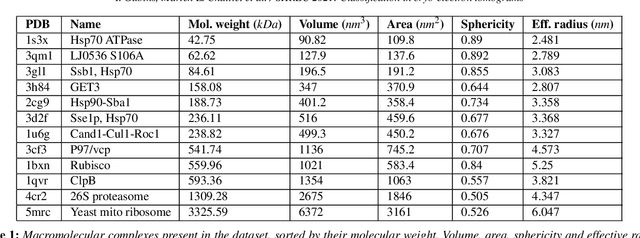
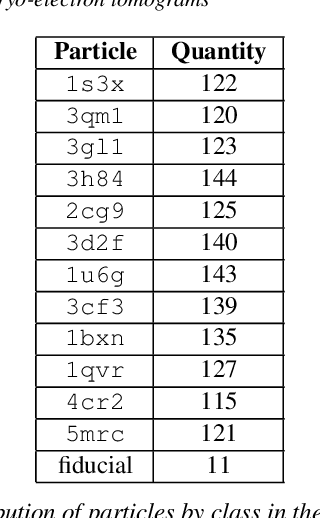
Cryo-electron tomography (cryo-ET) is an imaging technique that allows three-dimensional visualization of macro-molecular assemblies under near-native conditions. Cryo-ET comes with a number of challenges, mainly low signal-to-noise and inability to obtain images from all angles. Computational methods are key to analyze cryo-electron tomograms. To promote innovation in computational methods, we generate a novel simulated dataset to benchmark different methods of localization and classification of biological macromolecules in tomograms. Our publicly available dataset contains ten tomographic reconstructions of simulated cell-like volumes. Each volume contains twelve different types of complexes, varying in size, function and structure. In this paper, we have evaluated seven different methods of finding and classifying proteins. Seven research groups present results obtained with learning-based methods and trained on the simulated dataset, as well as a baseline template matching (TM), a traditional method widely used in cryo-ET research. We show that learning-based approaches can achieve notably better localization and classification performance than TM. We also experimentally confirm that there is a negative relationship between particle size and performance for all methods.
SHREC 2020 track: 6D Object Pose Estimation
Oct 19, 2020
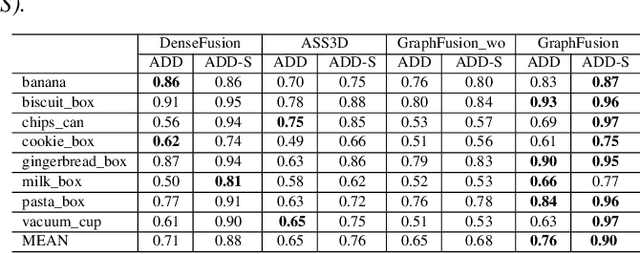
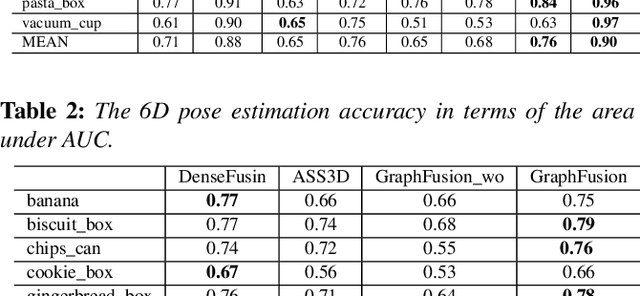
6D pose estimation is crucial for augmented reality, virtual reality, robotic manipulation and visual navigation. However, the problem is challenging due to the variety of objects in the real world. They have varying 3D shape and their appearances in captured images are affected by sensor noise, changing lighting conditions and occlusions between objects. Different pose estimation methods have different strengths and weaknesses, depending on feature representations and scene contents. At the same time, existing 3D datasets that are used for data-driven methods to estimate 6D poses have limited view angles and low resolution. To address these issues, we organize the Shape Retrieval Challenge benchmark on 6D pose estimation and create a physically accurate simulator that is able to generate photo-realistic color-and-depth image pairs with corresponding ground truth 6D poses. From captured color and depth images, we use this simulator to generate a 3D dataset which has 400 photo-realistic synthesized color-and-depth image pairs with various view angles for training, and another 100 captured and synthetic images for testing. Five research groups register in this track and two of them submitted their results. Data-driven methods are the current trend in 6D object pose estimation and our evaluation results show that approaches which fully exploit the color and geometric features are more robust for 6D pose estimation of reflective and texture-less objects and occlusion. This benchmark and comparative evaluation results have the potential to further enrich and boost the research of 6D object pose estimation and its applications.
Deeply Cascaded U-Net for Multi-Task Image Processing
May 01, 2020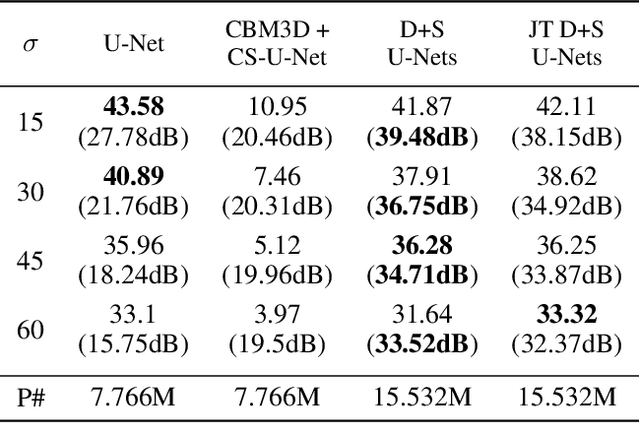
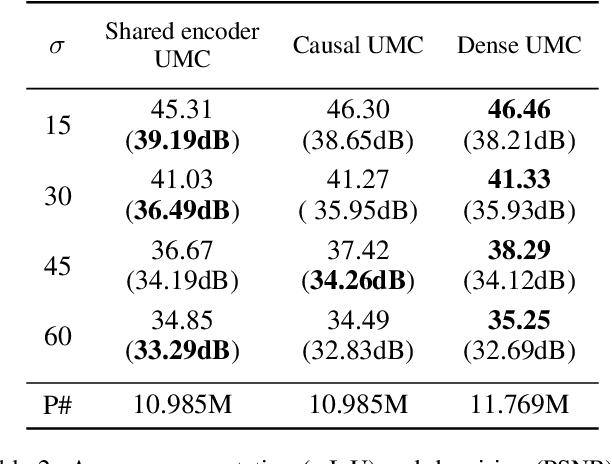
In current practice, many image processing tasks are done sequentially (e.g. denoising, dehazing, followed by semantic segmentation). In this paper, we propose a novel multi-task neural network architecture designed for combining sequential image processing tasks. We extend U-Net by additional decoding pathways for each individual task, and explore deep cascading of outputs and connectivity from one pathway to another. We demonstrate effectiveness of the proposed approach on denoising and semantic segmentation, as well as on progressive coarse-to-fine semantic segmentation, and achieve better performance than multiple individual or jointly-trained networks, with lower number of trainable parameters.
Learning Class Regularized Features for Action Recognition
Feb 07, 2020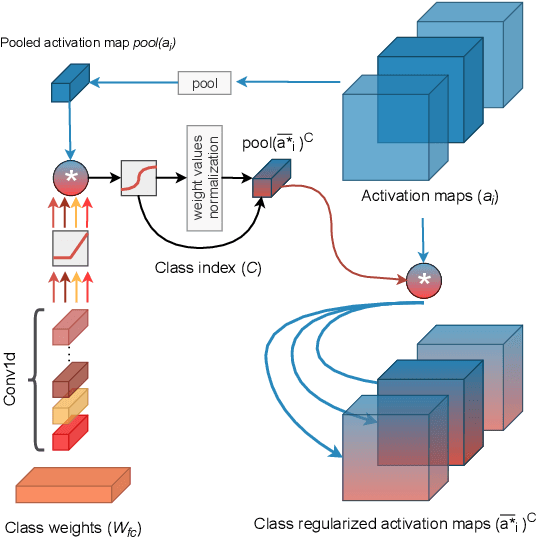
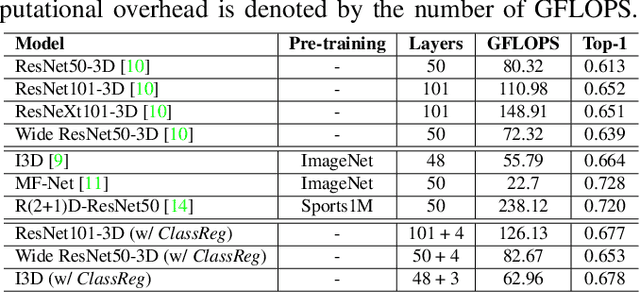
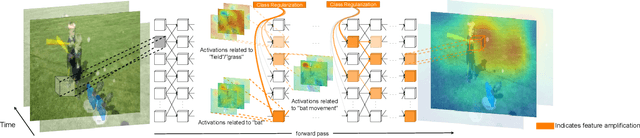
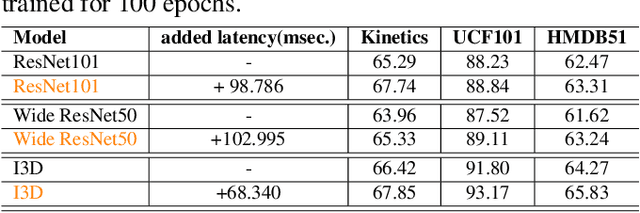
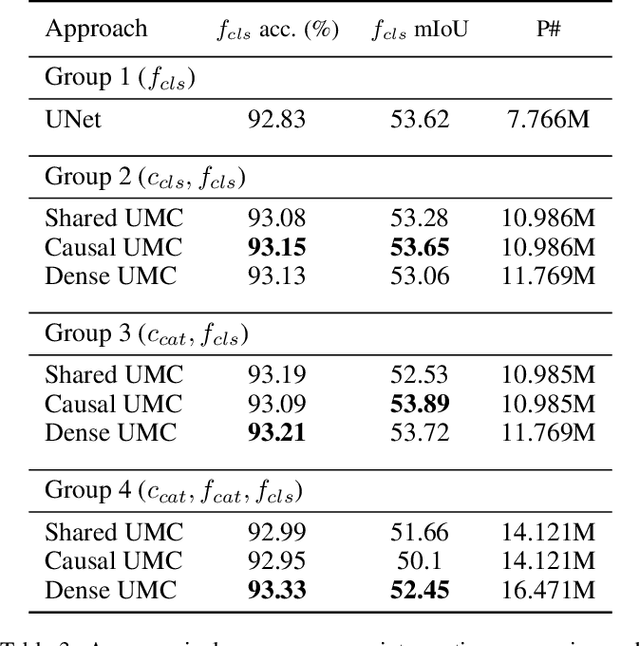
Training Deep Convolutional Neural Networks (CNNs) is based on the notion of using multiple kernels and non-linearities in their subsequent activations to extract useful features. The kernels are used as general feature extractors without specific correspondence to the target class. As a result, the extracted features do not correspond to specific classes. Subtle differences between similar classes are modeled in the same way as large differences between dissimilar classes. To overcome the class-agnostic use of kernels in CNNs, we introduce a novel method named Class Regularization that performs class-based regularization of layer activations. We demonstrate that this not only improves feature search during training, but also allows an explicit assignment of features per class during each stage of the feature extraction process. We show that using Class Regularization blocks in state-of-the-art CNN architectures for action recognition leads to systematic improvement gains of 1.8%, 1.2% and 1.4% on the Kinetics, UCF-101 and HMDB-51 datasets, respectively.
Egocentric Hand Track and Object-based Human Action Recognition
May 02, 2019
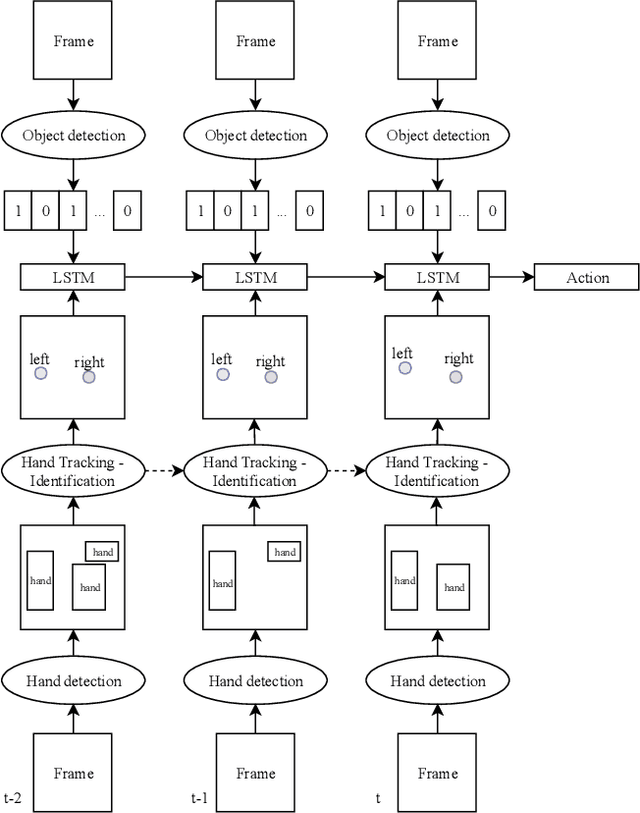


Egocentric vision is an emerging field of computer vision that is characterized by the acquisition of images and video from the first person perspective. In this paper we address the challenge of egocentric human action recognition by utilizing the presence and position of detected regions of interest in the scene explicitly, without further use of visual features. Initially, we recognize that human hands are essential in the execution of actions and focus on obtaining their movements as the principal cues that define actions. We employ object detection and region tracking techniques to locate hands and capture their movements. Prior knowledge about egocentric views facilitates hand identification between left and right. With regard to detection and tracking, we contribute a pipeline that successfully operates on unseen egocentric videos to find the camera wearer's hands and associate them through time. Moreover, we emphasize on the value of scene information for action recognition. We acknowledge that the presence of objects is significant for the execution of actions by humans and in general for the description of a scene. To acquire this information, we utilize object detection for specific classes that are relevant to the actions we want to recognize. Our experiments are targeted on videos of kitchen activities from the Epic-Kitchens dataset. We model action recognition as a sequence learning problem of the detected spatial positions in the frames. Our results show that explicit hand and object detections with no other visual information can be relied upon to classify hand-related human actions. Testing against methods fully dependent on visual features, signals that for actions where hand motions are conceptually important, a region-of-interest-based description of a video contains equally expressive information with comparable classification performance.
Water Detection through Spatio-Temporal Invariant Descriptors
Nov 03, 2015
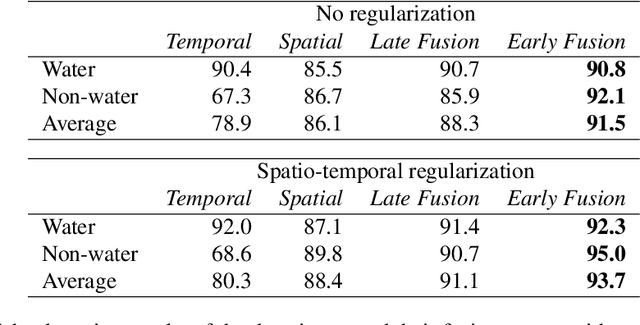


In this work, we aim to segment and detect water in videos. Water detection is beneficial for appllications such as video search, outdoor surveillance, and systems such as unmanned ground vehicles and unmanned aerial vehicles. The specific problem, however, is less discussed compared to general texture recognition. Here, we analyze several motion properties of water. First, we describe a video pre-processing step, to increase invariance against water reflections and water colours. Second, we investigate the temporal and spatial properties of water and derive corresponding local descriptors. The descriptors are used to locally classify the presence of water and a binary water detection mask is generated through spatio-temporal Markov Random Field regularization of the local classifications. Third, we introduce the Video Water Database, containing several hours of water and non-water videos, to validate our algorithm. Experimental evaluation on the Video Water Database and the DynTex database indicates the effectiveness of the proposed algorithm, outperforming multiple algorithms for dynamic texture recognition and material recognition by ca. 5% and 15% respectively.