 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Partial Cycle-Consistency for Multi-View Matching
Jan 10, 2025



Matching objects across partially overlapping camera views is crucial in multi-camera systems and requires a view-invariant feature extraction network. Training such a network with cycle-consistency circumvents the need for labor-intensive labeling. In this paper, we extend the mathematical formulation of cycle-consistency to handle partial overlap. We then introduce a pseudo-mask which directs the training loss to take partial overlap into account. We additionally present several new cycle variants that complement each other and present a time-divergent scene sampling scheme that improves the data input for this self-supervised setting. Cross-camera matching experiments on the challenging DIVOTrack dataset show the merits of our approach. Compared to the self-supervised state-of-the-art, we achieve a 4.3 percentage point higher F1 score with our combined contributions. Our improvements are robust to reduced overlap in the training data, with substantial improvements in challenging scenes that need to make few matches between many people. Self-supervised feature networks trained with our method are effective at matching objects in a range of multi-camera settings, providing opportunities for complex tasks like large-scale multi-camera scene understanding.
About Time: Advances, Challenges, and Outlooks of Action Understanding
Nov 22, 2024



We have witnessed impressive advances in video action understanding. Increased dataset sizes, variability, and computation availability have enabled leaps in performance and task diversification. Current systems can provide coarse- and fine-grained descriptions of video scenes, extract segments corresponding to queries, synthesize unobserved parts of videos, and predict context. This survey comprehensively reviews advances in uni- and multi-modal action understanding across a range of tasks. We focus on prevalent challenges, overview widely adopted datasets, and survey seminal works with an emphasis on recent advances. We broadly distinguish between three temporal scopes: (1) recognition tasks of actions observed in full, (2) prediction tasks for ongoing partially observed actions, and (3) forecasting tasks for subsequent unobserved action. This division allows us to identify specific action modeling and video representation challenges. Finally, we outline future directions to address current shortcomings.
VideoMambaPro: A Leap Forward for Mamba in Video Understanding
Jun 27, 2024Video understanding requires the extraction of rich spatio-temporal representations, which transformer models achieve through self-attention. Unfortunately, self-attention poses a computational burden. In NLP, Mamba has surfaced as an efficient alternative for transformers. However, Mamba's successes do not trivially extend to computer vision tasks, including those in video analysis. In this paper, we theoretically analyze the differences between self-attention and Mamba. We identify two limitations in Mamba's token processing: historical decay and element contradiction. We propose VideoMambaPro (VMP) that solves the identified limitations by adding masked backward computation and elemental residual connections to a VideoMamba backbone. VideoMambaPro shows state-of-the-art video action recognition performance compared to transformer models, and surpasses VideoMamba by clear margins: 7.9% and 8.1% top-1 on Kinetics-400 and Something-Something V2, respectively. Our VideoMambaPro-M model achieves 91.9% top-1 on Kinetics-400, only 0.2% below InternVideo2-6B but with only 1.2% of its parameters. The combination of high performance and efficiency makes VideoMambaPro an interesting alternative for transformer models.
Enhancing Video Transformers for Action Understanding with VLM-aided Training
Mar 24, 2024
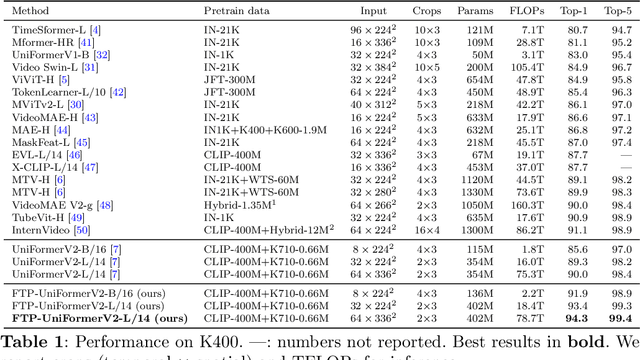

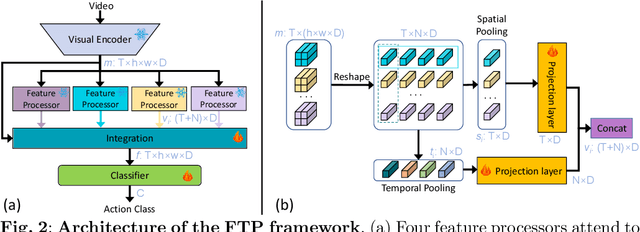
Owing to their ability to extract relevant spatio-temporal video embeddings, Vision Transformers (ViTs) are currently the best performing models in video action understanding. However, their generalization over domains or datasets is somewhat limited. In contrast, Visual Language Models (VLMs) have demonstrated exceptional generalization performance, but are currently unable to process videos. Consequently, they cannot extract spatio-temporal patterns that are crucial for action understanding. In this paper, we propose the Four-tiered Prompts (FTP) framework that takes advantage of the complementary strengths of ViTs and VLMs. We retain ViTs' strong spatio-temporal representation ability but improve the visual encodings to be more comprehensive and general by aligning them with VLM outputs. The FTP framework adds four feature processors that focus on specific aspects of human action in videos: action category, action components, action description, and context information. The VLMs are only employed during training, and inference incurs a minimal computation cost. Our approach consistently yields state-of-the-art performance. For instance, we achieve remarkable top-1 accuracy of 93.8% on Kinetics-400 and 83.4% on Something-Something V2, surpassing VideoMAEv2 by 2.8% and 2.6%, respectively.
TCNet: Continuous Sign Language Recognition from Trajectories and Correlated Regions
Mar 18, 2024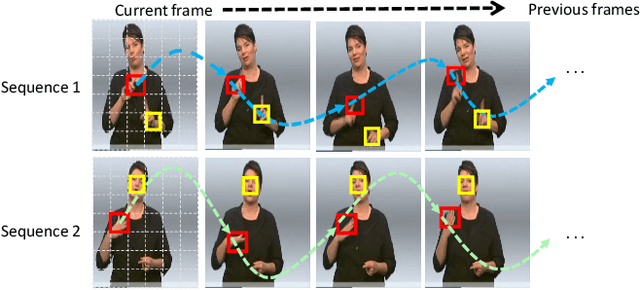
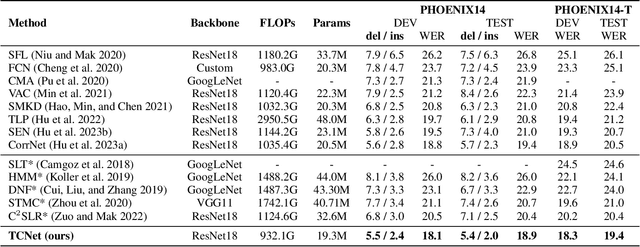
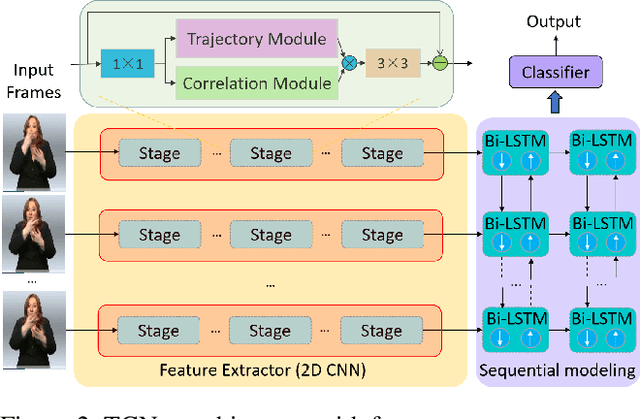
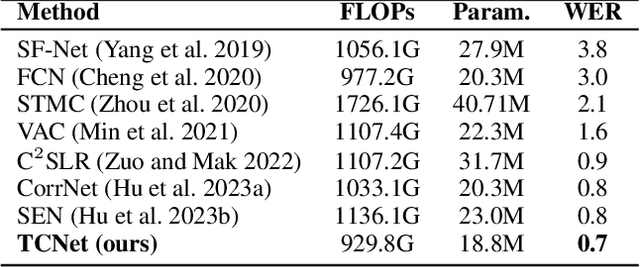
A key challenge in continuous sign language recognition (CSLR) is to efficiently capture long-range spatial interactions over time from the video input. To address this challenge, we propose TCNet, a hybrid network that effectively models spatio-temporal information from Trajectories and Correlated regions. TCNet's trajectory module transforms frames into aligned trajectories composed of continuous visual tokens. In addition, for a query token, self-attention is learned along the trajectory. As such, our network can also focus on fine-grained spatio-temporal patterns, such as finger movements, of a specific region in motion. TCNet's correlation module uses a novel dynamic attention mechanism that filters out irrelevant frame regions. Additionally, it assigns dynamic key-value tokens from correlated regions to each query. Both innovations significantly reduce the computation cost and memory. We perform experiments on four large-scale datasets: PHOENIX14, PHOENIX14-T, CSL, and CSL-Daily, respectively. Our results demonstrate that TCNet consistently achieves state-of-the-art performance. For example, we improve over the previous state-of-the-art by 1.5% and 1.0% word error rate on PHOENIX14 and PHOENIX14-T, respectively.
Compensation Sampling for Improved Convergence in Diffusion Models
Dec 11, 2023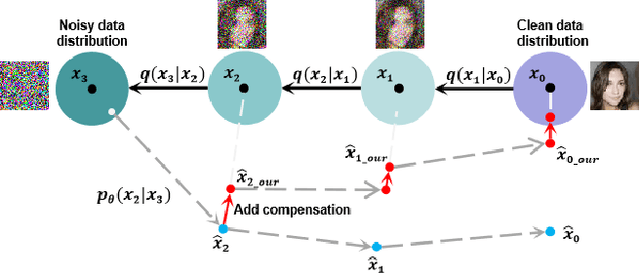
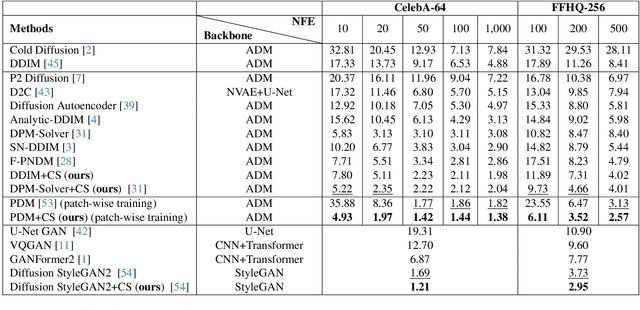

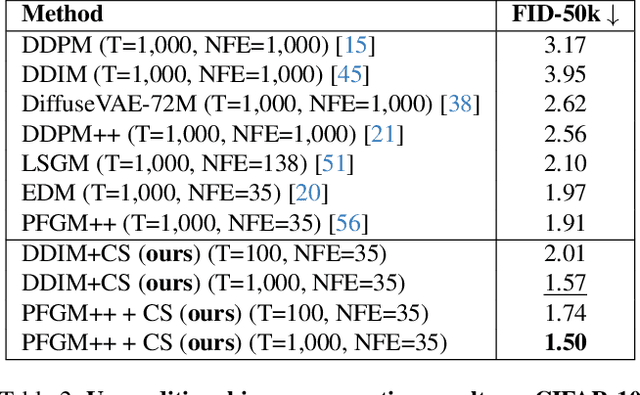
Diffusion models achieve remarkable quality in image generation, but at a cost. Iterative denoising requires many time steps to produce high fidelity images. We argue that the denoising process is crucially limited by an accumulation of the reconstruction error due to an initial inaccurate reconstruction of the target data. This leads to lower quality outputs, and slower convergence. To address this issue, we propose compensation sampling to guide the generation towards the target domain. We introduce a compensation term, implemented as a U-Net, which adds negligible computation overhead during training and, optionally, inference. Our approach is flexible and we demonstrate its application in unconditional generation, face inpainting, and face de-occlusion using benchmark datasets CIFAR-10, CelebA, CelebA-HQ, FFHQ-256, and FSG. Our approach consistently yields state-of-the-art results in terms of image quality, while accelerating the denoising process to converge during training by up to an order of magnitude.
AdaPool: Exponential Adaptive Pooling for Information-Retaining Downsampling
Nov 02, 2021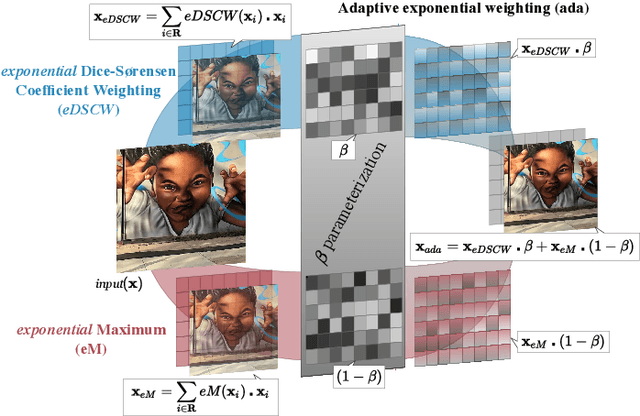
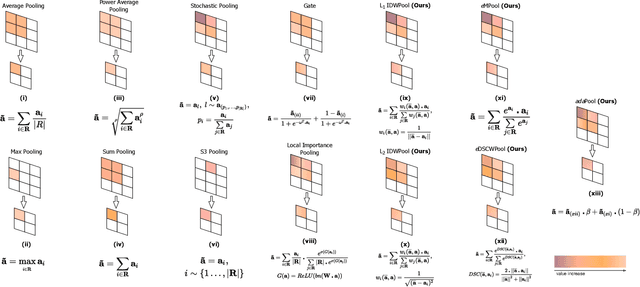


Pooling layers are essential building blocks of Convolutional Neural Networks (CNNs) that reduce computational overhead and increase the receptive fields of proceeding convolutional operations. They aim to produce downsampled volumes that closely resemble the input volume while, ideally, also being computationally and memory efficient. It is a challenge to meet both requirements jointly. To this end, we propose an adaptive and exponentially weighted pooling method named adaPool. Our proposed method uses a parameterized fusion of two sets of pooling kernels that are based on the exponent of the Dice-Sorensen coefficient and the exponential maximum, respectively. A key property of adaPool is its bidirectional nature. In contrast to common pooling methods, weights can be used to upsample a downsampled activation map. We term this method adaUnPool. We demonstrate how adaPool improves the preservation of detail through a range of tasks including image and video classification and object detection. We then evaluate adaUnPool on image and video frame super-resolution and frame interpolation tasks. For benchmarking, we introduce Inter4K, a novel high-quality, high frame-rate video dataset. Our combined experiments demonstrate that adaPool systematically achieves better results across tasks and backbone architectures, while introducing a minor additional computational and memory overhead.
Incremental Few-Shot Instance Segmentation
May 11, 2021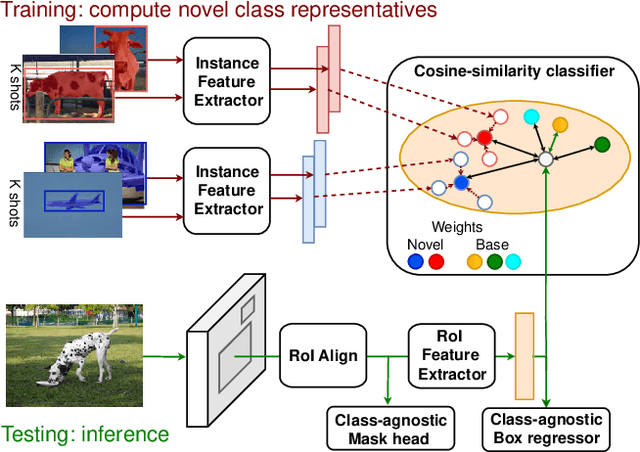
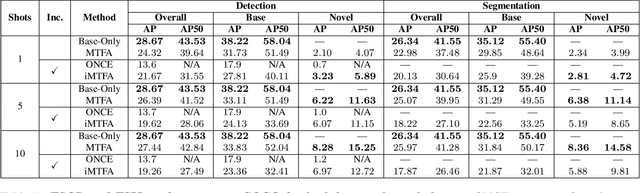
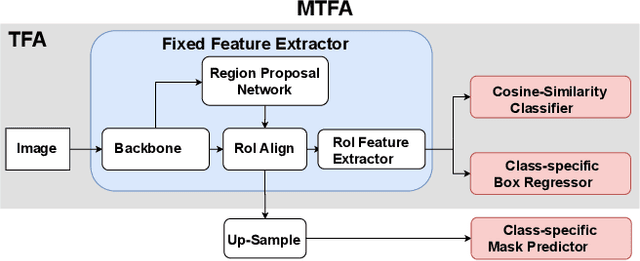
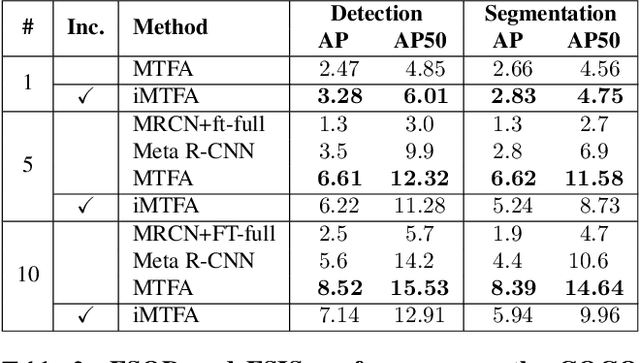
Few-shot instance segmentation methods are promising when labeled training data for novel classes is scarce. However, current approaches do not facilitate flexible addition of novel classes. They also require that examples of each class are provided at train and test time, which is memory intensive. In this paper, we address these limitations by presenting the first incremental approach to few-shot instance segmentation: iMTFA. We learn discriminative embeddings for object instances that are merged into class representatives. Storing embedding vectors rather than images effectively solves the memory overhead problem. We match these class embeddings at the RoI-level using cosine similarity. This allows us to add new classes without the need for further training or access to previous training data. In a series of experiments, we consistently outperform the current state-of-the-art. Moreover, the reduced memory requirements allow us to evaluate, for the first time, few-shot instance segmentation performance on all classes in COCO jointly.
Refining activation downsampling with SoftPool
Jan 05, 2021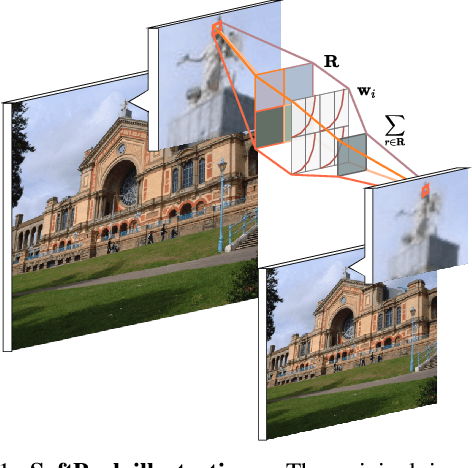
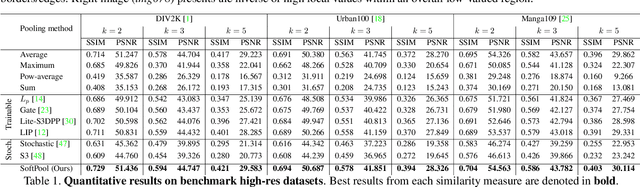
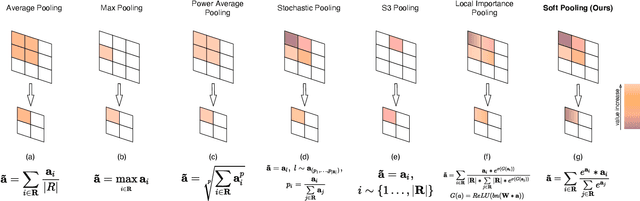
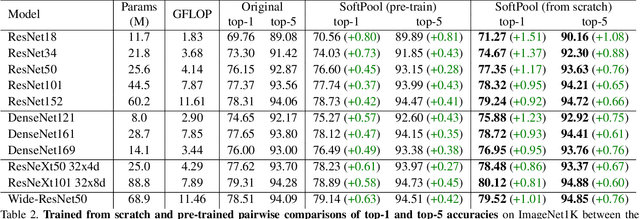
Convolutional Neural Networks (CNNs) use pooling to decrease the size of activation maps. This process is crucial to locally achieve spatial invariance and to increase the receptive field of subsequent convolutions. Pooling operations should minimize the loss of information in the activation maps. At the same time, the computation and memory overhead should be limited. To meet these requirements, we propose SoftPool: a fast and efficient method that sums exponentially weighted activations. Compared to a range of other pooling methods, SoftPool retains more information in the downsampled activation maps. More refined downsampling leads to better classification accuracy. On ImageNet1K, for a range of popular CNN architectures, replacing the original pooling operations with SoftPool leads to consistent accuracy improvements in the order of 1-2%. We also test SoftPool on video datasets for action recognition. Again, replacing only the pooling layers consistently increases accuracy while computational load and memory remain limited. These favorable properties make SoftPool an excellent replacement for current pooling operations, including max-pool and average-pool
Right on Time: Multi-Temporal Convolutions for Human Action Recognition in Videos
Nov 08, 2020The variations in the temporal performance of human actions observed in videos present challenges for their extraction using fixed-sized convolution kernels in CNNs. We present an approach that is more flexible in terms of processing the input at multiple timescales. We introduce Multi-Temporal networks that model spatio-temporal patterns of different temporal durations at each layer. To this end, they employ novel 3D convolution (MTConv) blocks that consist of a short stream for local space-time features and a long stream for features spanning across longer times. By aligning features of each stream with respect to the global motion patterns using recurrent cells, we can discover temporally coherent spatio-temporal features with varying durations. We further introduce sub-streams within each of the block pathways to reduce the computation requirements. The proposed MTNet architectures outperform state-of-the-art 3D-CNNs on five action recognition benchmark datasets. Notably, we achieve at 87.22% top-1 accuracy on HACS, and 58.39% top-1 at Kinectics-700. We further demonstrate the favorable computational requirements. Using sub-streams, we can further achieve a drastic reduction in parameters (~60%) and GLOPs (~74%). Experiments using transfer learning finally verify the generalization capabilities of the multi-temporal features