 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCNet: Continuous Sign Language Recognition from Trajectories and Correlated Regions
Paper and Code
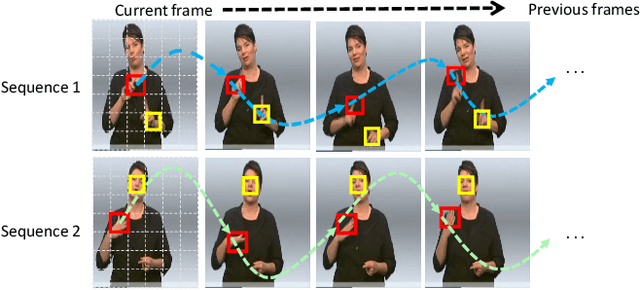
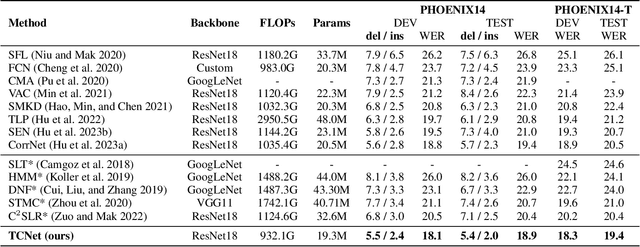
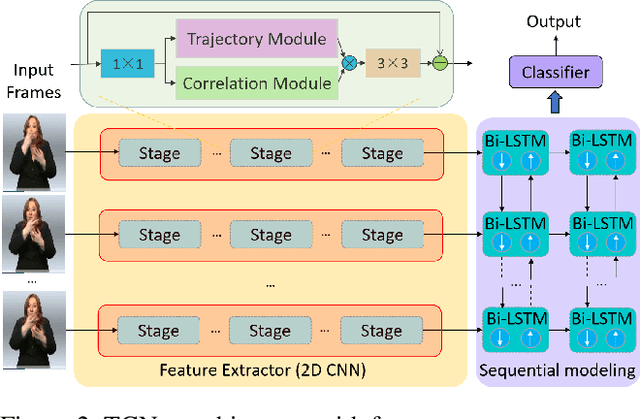
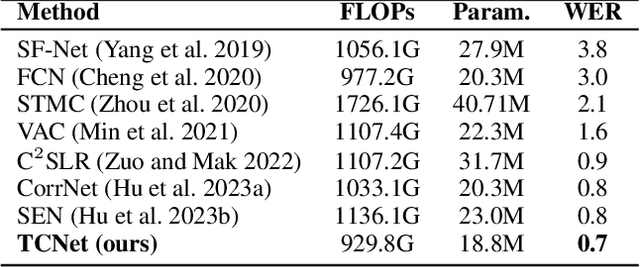
A key challenge in continuous sign language recognition (CSLR) is to efficiently capture long-range spatial interactions over time from the video input. To address this challenge, we propose TCNet, a hybrid network that effectively models spatio-temporal information from Trajectories and Correlated regions. TCNet's trajectory module transforms frames into aligned trajectories composed of continuous visual tokens. In addition, for a query token, self-attention is learned along the trajectory. As such, our network can also focus on fine-grained spatio-temporal patterns, such as finger movements, of a specific region in motion. TCNet's correlation module uses a novel dynamic attention mechanism that filters out irrelevant frame regions. Additionally, it assigns dynamic key-value tokens from correlated regions to each query. Both innovations significantly reduce the computation cost and memory. We perform experiments on four large-scale datasets: PHOENIX14, PHOENIX14-T, CSL, and CSL-Daily, respectively. Our results demonstrate that TCNet consistently achieves state-of-the-art performance. For example, we improve over the previous state-of-the-art by 1.5% and 1.0% word error rate on PHOENIX14 and PHOENIX14-T, respectively.