 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Behavior Planning for Fruit Tree Pruning via Redundant Robot Manipulators: Addressing the Behavior Planning Challenge
Oct 14, 2025Pruning is an essential agricultural practice for orchards. Proper pruning can promote healthier growth and optimize fruit production throughout the orchard's lifespan. Robot manipulators have been developed as an automated solution for this repetitive task, which typically requires seasonal labor with specialized skills. While previous research has primarily focused on the challenges of perception, the complexities of manipulation are often overlooked. These challenges involve planning and control in both joint and Cartesian spaces to guide the end-effector through intricate, obstructive branches. Our work addresses the behavior planning challenge for a robotic pruning system, which entails a multi-level planning problem in environments with complex collisions. In this paper, we formulate the planning problem for a high-dimensional robotic arm in a pruning scenario, investigate the system's intrinsic redundancies, and propose a comprehensive pruning workflow that integrates perception, modeling, and holistic planning. In our experiments, we demonstrate that more comprehensive planning methods can significantly enhance the performance of the robotic manipulator. Finally, we implement the proposed workflow on a real-world robot. As a result, this work complements previous efforts on robotic pruning and motivates future research and development in planning for pruning applications.
Evaluation of the potential of Near Infrared Hyperspectral Imaging for monitoring the invasive brown marmorated stink bug
Jan 19, 2023



The brown marmorated stink bug (BMSB), Halyomorpha halys, is an invasive insect pest of global importance that damages several crops, compromising agri-food production. Field monitoring procedures are fundamental to perform risk assessment operations, in order to promptly face crop infestations and avoid economical losses. To improve pest management, spectral cameras mounted on Unmanned Aerial Vehicles (UAVs) and other Internet of Things (IoT) devices, such as smart traps or unmanned ground vehicles, could be used as an innovative technology allowing fast, efficient and real-time monitoring of insect infestations. The present study consists in a preliminary evaluation at the laboratory level of Near Infrared Hyperspectral Imaging (NIR-HSI) as a possible technology to detect BMSB specimens on different vegetal backgrounds, overcoming the problem of BMSB mimicry. Hyperspectral images of BMSB were acquired in the 980-1660 nm range, considering different vegetal backgrounds selected to mimic a real field application scene. Classification models were obtained following two different chemometric approaches. The first approach was focused on modelling spectral information and selecting relevant spectral regions for discrimination by means of sparse-based variable selection coupled with Soft Partial Least Squares Discriminant Analysis (s-Soft PLS-DA) classification algorithm. The second approach was based on modelling spatial and spectral features contained in the hyperspectral images using Convolutional Neural Networks (CNN). Finally, to further improve BMSB detection ability, the two strategies were merged, considering only the spectral regions selected by s-Soft PLS-DA for CNN modelling.
* Accepted manuscript
PSSNet: Planarity-sensible Semantic Segmentation of Large-scale Urban Meshes
Feb 09, 2022

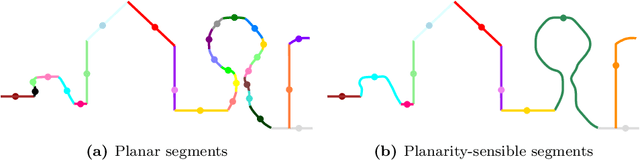
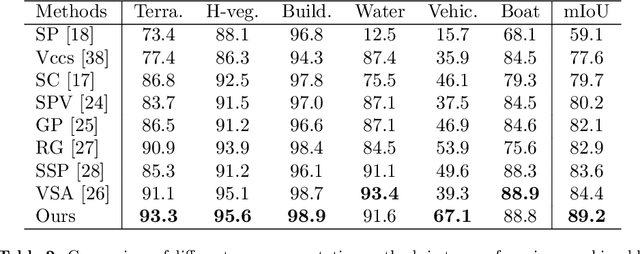
We introduce a novel deep learning-based framework to interpret 3D urban scenes represented as textured meshes. Based on the observation that object boundaries typically align with the boundaries of planar regions, our framework achieves semantic segmentation in two steps: planarity-sensible over-segmentation followed by semantic classification. The over-segmentation step generates an initial set of mesh segments that capture the planar and non-planar regions of urban scenes. In the subsequent classification step, we construct a graph that encodes geometric and photometric features of the segments in its nodes and multi-scale contextual features in its edges. The final semantic segmentation is obtained by classifying the segments using a graph convolutional network. Experiments and comparisons on a large semantic urban mesh benchmark demonstrate that our approach outperforms the state-of-the-art methods in terms of boundary quality and mean IoU (intersection over union). Besides, we also introduce several new metrics for evaluating mesh over-segmentation methods dedicated for semantic segmentation, and our proposed over-segmentation approach outperforms state-of-the-art methods on all metrics. Our source code will be released when the paper is accepted.
Incremental Few-Shot Instance Segmentation
May 11, 2021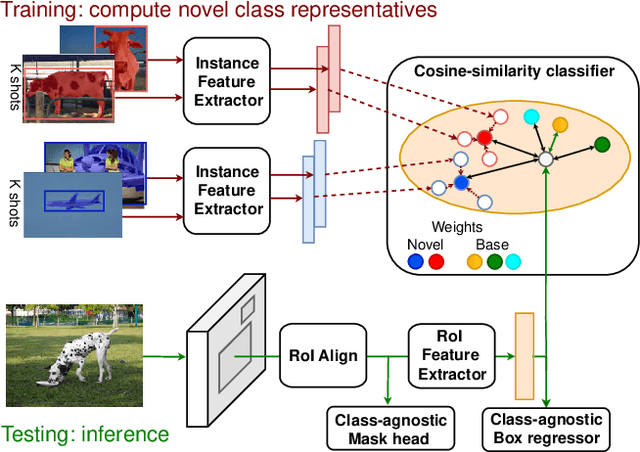
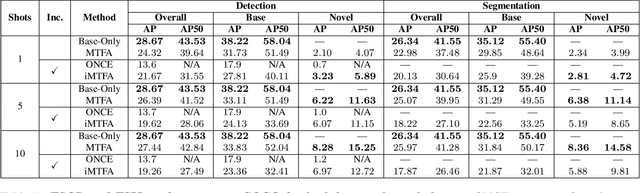
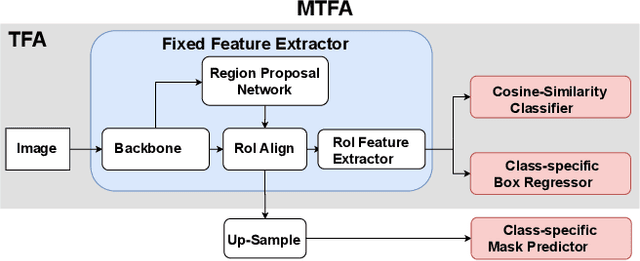
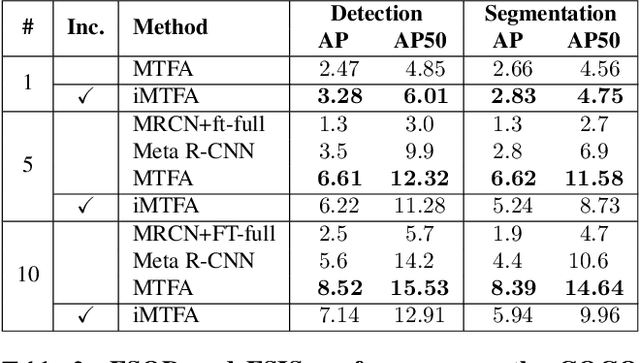
Few-shot instance segmentation methods are promising when labeled training data for novel classes is scarce. However, current approaches do not facilitate flexible addition of novel classes. They also require that examples of each class are provided at train and test time, which is memory intensive. In this paper, we address these limitations by presenting the first incremental approach to few-shot instance segmentation: iMTFA. We learn discriminative embeddings for object instances that are merged into class representatives. Storing embedding vectors rather than images effectively solves the memory overhead problem. We match these class embeddings at the RoI-level using cosine similarity. This allows us to add new classes without the need for further training or access to previous training data. In a series of experiments, we consistently outperform the current state-of-the-art. Moreover, the reduced memory requirements allow us to evaluate, for the first time, few-shot instance segmentation performance on all classes in COCO jointly.
SUM: A Benchmark Dataset of Semantic Urban Meshes
Feb 27, 2021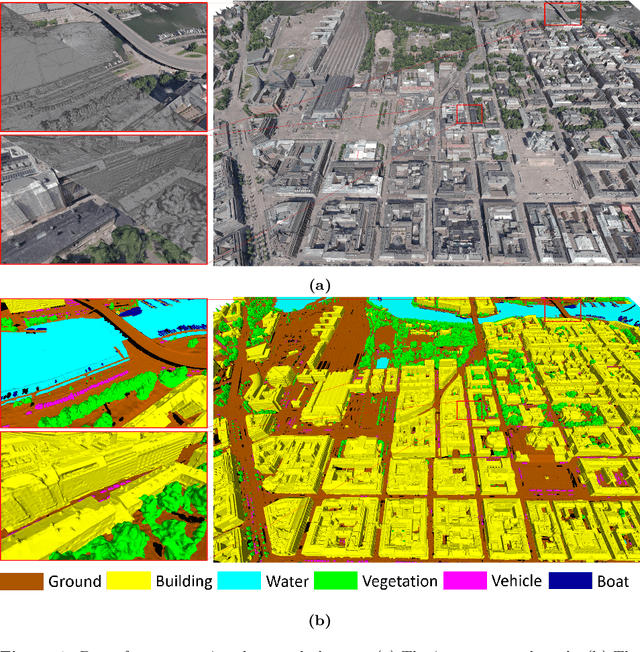
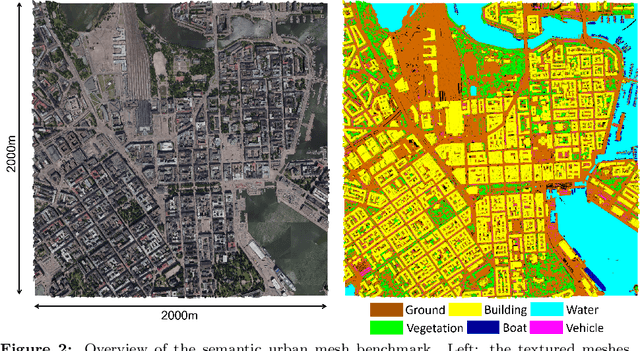
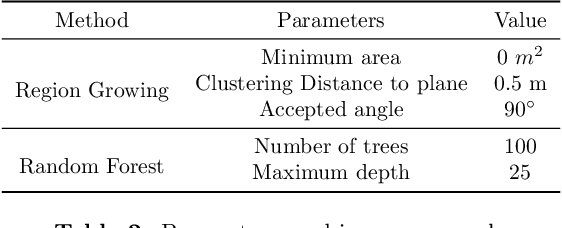
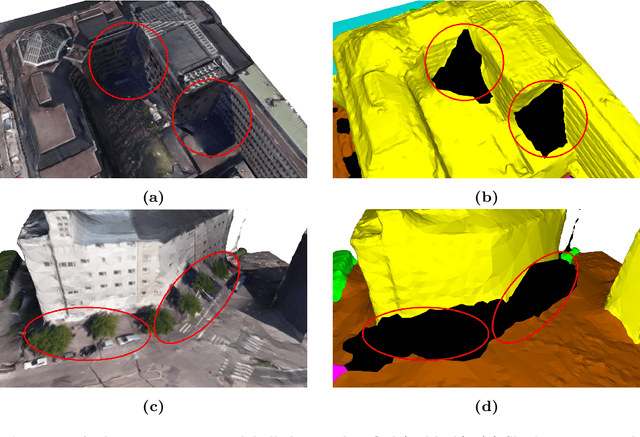
Recent developments in data acquisition technology allow us to collect 3D texture meshes quickly. Those can help us understand and analyse the urban environment, and as a consequence are useful for several applications like spatial analysis and urban planning. Semantic segmentation of texture meshes through deep learning methods can enhance this understanding, but it requires a lot of labelled data. This paper introduces a new benchmark dataset of semantic urban meshes, a novel semi-automatic annotation framework, and an open-source annotation tool for 3D meshes. In particular, our dataset covers about 4 km2 in Helsinki (Finland), with six classes, and we estimate that we save about 600 hours of labelling work using our annotation framework, which includes initial segmentation and interactive refinement. Furthermore, we compare the performance of several representative 3D semantic segmentation methods on our annotated dataset. The results show our initial segmentation outperforms other methods and achieves an overall accuracy of 93.0% and mIoU of 66.2% with less training time compared to other deep learning methods. We also evaluate the effect of the input training data, which shows that our method only requires about 7% (which covers about 0.23 km2) to approach robust and adequate results whereas KPConv needs at least 33% (which covers about 1.0 km2).
Privacy Protection in Street-View Panoramas using Depth and Multi-View Imagery
Mar 27, 2019
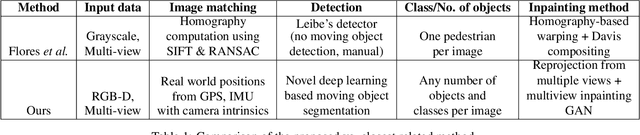
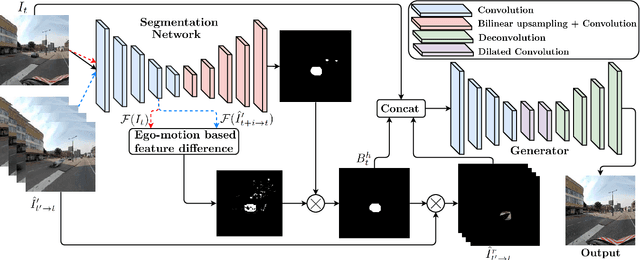

The current paradigm in privacy protection in street-view images is to detect and blur sensitive information. In this paper, we propose a framework that is an alternative to blurring, which automatically removes and inpaints moving objects (e.g. pedestrians, vehicles) in street-view imagery. We propose a novel moving object segmentation algorithm exploiting consistencies in depth across multiple street-view images that are later combined with the results of a segmentation network. The detected moving objects are removed and inpainted with information from other views, to obtain a realistic output image such that the moving object is not visible anymore. We evaluate our results on a dataset of 1000 images to obtain a peak noise-to-signal ratio (PSNR) and L1 loss of 27.2 dB and 2.5%, respectively. To ensure the subjective quality, To assess overall quality, we also report the results of a survey conducted on 35 professionals, asked to visually inspect the images whether object removal and inpainting had taken place. The inpainting dataset will be made publicly available for scientific benchmarking purposes at https://research.cyclomedia.com
LiDAR-assisted Large-scale Privacy Protection in Street-view Cycloramas
Mar 13, 2019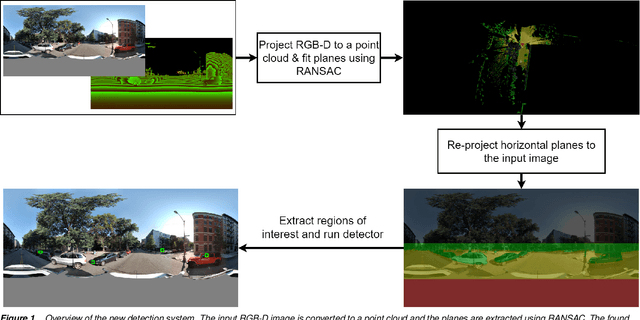
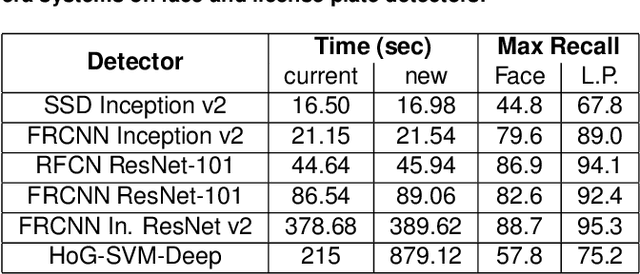
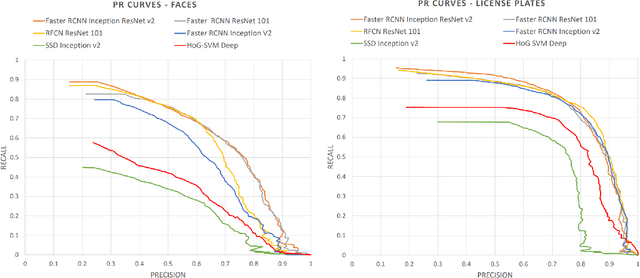

Recently, privacy has a growing importance in several domains, especially in street-view images. The conventional way to achieve this is to automatically detect and blur sensitive information from these images. However, the processing cost of blurring increases with the ever-growing resolution of images. We propose a system that is cost-effective even after increasing the resolution by a factor of 2.5. The new system utilizes depth data obtained from LiDAR to significantly reduce the search space for detection, thereby reducing the processing cost. Besides this, we test several detectors after reducing the detection space and provide an alternative solution based on state-of-the-art deep learning detectors to the existing HoG-SVM-Deep system that is faster and has a higher performance.
Bootstrapped CNNs for Building Segmentation on RGB-D Aerial Imagery
Oct 08, 2018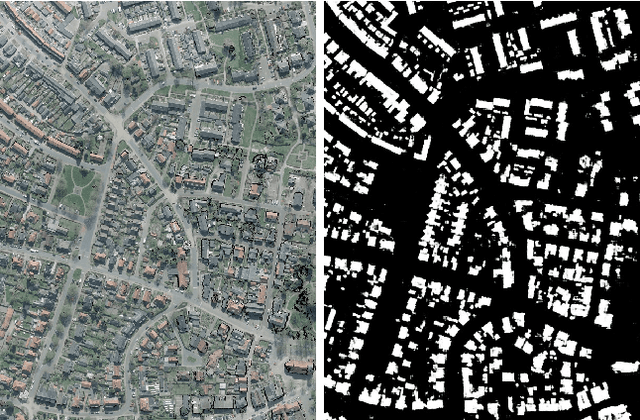


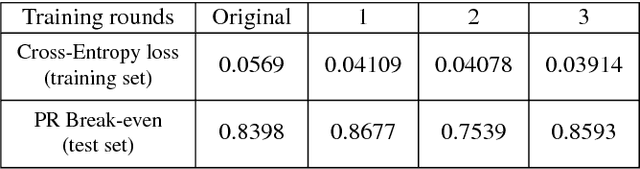
Detection of buildings and other objects from aerial images has various applications in urban planning and map making. Automated building detection from aerial imagery is a challenging task, as it is prone to varying lighting conditions, shadows and occlusions. Convolutional Neural Networks (CNNs) are robust against some of these variations, although they fail to distinguish easy and difficult examples. We train a detection algorithm from RGB-D images to obtain a segmented mask by using the CNN architecture DenseNet.First, we improve the performance of the model by applying a statistical re-sampling technique called Bootstrapping and demonstrate that more informative examples are retained. Second, the proposed method outperforms the non-bootstrapped version by utilizing only one-sixth of the original training data and it obtains a precision-recall break-even of 95.10% on our aerial imagery dataset.
Conditional Transfer with Dense Residual Attention: Synthesizing traffic signs from street-view imagery
Sep 05, 2018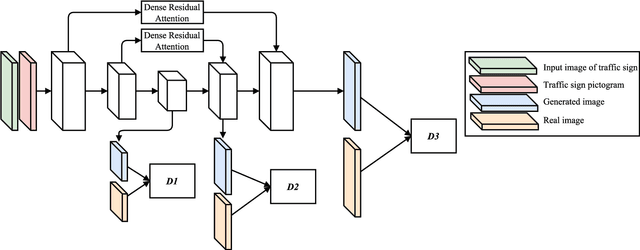
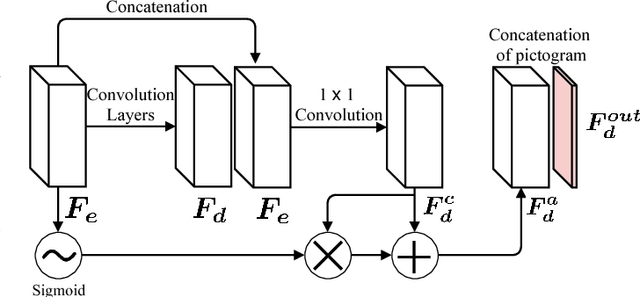
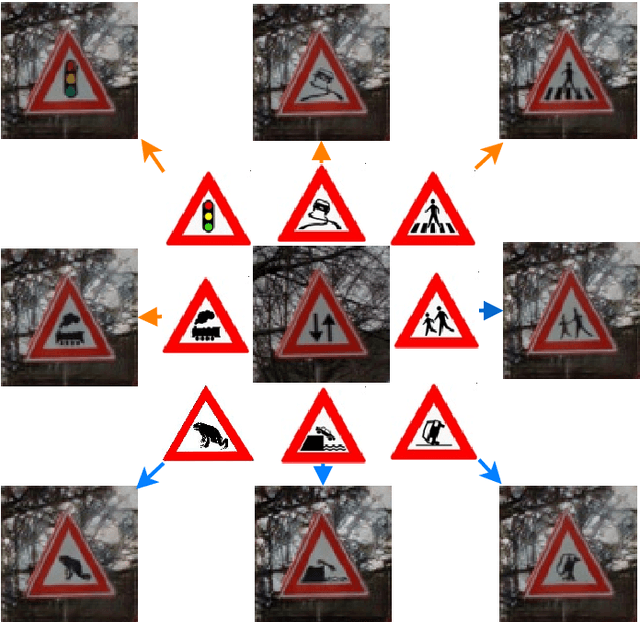

Object detection and classification of traffic signs in street-view imagery is an essential element for asset management, map making and autonomous driving. However, some traffic signs occur rarely and consequently, they are difficult to recognize automatically. To improve the detection and classification rates, we propose to generate images of traffic signs, which are then used to train a detector/classifier. In this research, we present an end-to-end framework that generates a realistic image of a traffic sign from a given image of a traffic sign and a pictogram of the target class. We propose a residual attention mechanism with dense concatenation called Dense Residual Attention, that preserves the background information while transferring the object information. We also propose to utilize multi-scale discriminators, so that the smaller scales of the output guide the higher resolution output. We have performed detection and classification tests across a large number of traffic sign classes, by training the detector using the combination of real and generated data. The newly trained model reduces the number of false positives by 1.2 - 1.5% at 99% recall in the detection tests and an absolute improvement of 4.65% (top-1 accuracy) in the classification tests.