 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation
Jun 07, 2024

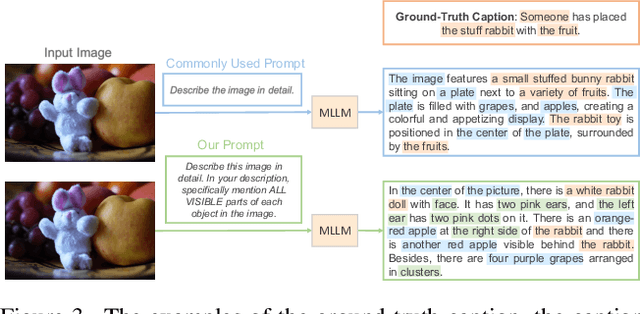
The open-vocabulary image segmentation task involves partitioning images into semantically meaningful segments and classifying them with flexible text-defined categories. The recent vision-based foundation models such as the Segment Anything Model (SAM) have shown superior performance in generating class-agnostic image segments. The main challenge in open-vocabulary image segmentation now lies in accurately classifying these segments into text-defined categories. In this paper, we introduce the Universal Segment Embedding (USE) framework to address this challenge. This framework is comprised of two key components: 1) a data pipeline designed to efficiently curate a large amount of segment-text pairs at various granularities, and 2) a universal segment embedding model that enables precise segment classification into a vast range of text-defined categories. The USE model can not only help open-vocabulary image segmentation but also facilitate other downstream tasks (e.g., querying and ranking). Through comprehensive experimental studies on semantic segmentation and part segmentation benchmarks, we demonstrate that the USE framework outperforms state-of-the-art open-vocabulary segmentation methods.
Dual Embedding Expansion for Vehicle Re-identification
Apr 18, 2020
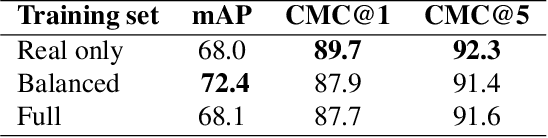
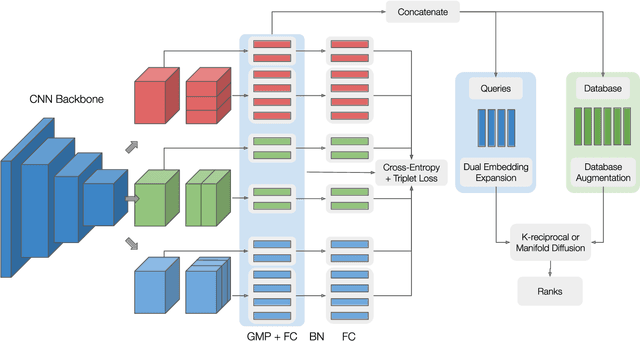
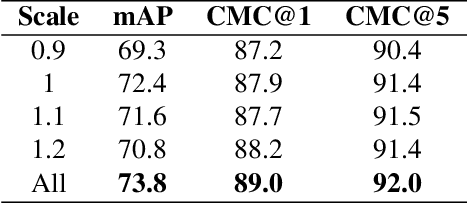
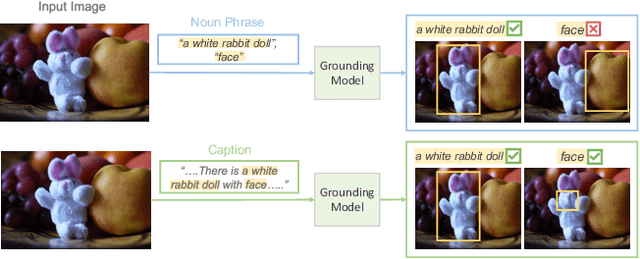
Vehicle re-identification plays a crucial role in the management of transportation infrastructure and traffic flow. However, this is a challenging task due to the large view-point variations in appearance, environmental and instance-related factors. Modern systems deploy CNNs to produce unique representations from the images of each vehicle instance. Most work focuses on leveraging new losses and network architectures to improve the descriptiveness of these representations. In contrast, our work concentrates on re-ranking and embedding expansion techniques. We propose an efficient approach for combining the outputs of multiple models at various scales while exploiting tracklet and neighbor information, called dual embedding expansion (DEx). Additionally, a comparative study of several common image retrieval techniques is presented in the context of vehicle re-ID. Our system yields competitive performance in the 2020 NVIDIA AI City Challenge with promising results. We demonstrate that DEx when combined with other re-ranking techniques, can produce an even larger gain without any additional attribute labels or manual supervision.
Contextual Pyramid Attention Network for Building Segmentation in Aerial Imagery
Apr 15, 2020
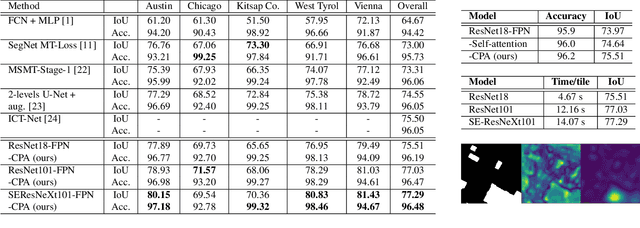
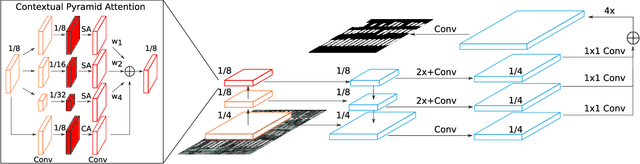
Building extraction from aerial images has several applications in problems such as urban planning, change detection, and disaster management. With the increasing availability of data, Convolutional Neural Networks (CNNs) for semantic segmentation of remote sensing imagery has improved significantly in recent years. However, convolutions operate in local neighborhoods and fail to capture non-local features that are essential in semantic understanding of aerial images. In this work, we propose to improve building segmentation of different sizes by capturing long-range dependencies using contextual pyramid attention (CPA). The pathways process the input at multiple scales efficiently and combine them in a weighted manner, similar to an ensemble model. The proposed method obtains state-of-the-art performance on the Inria Aerial Image Labelling Dataset with minimal computation costs. Our method improves 1.8 points over current state-of-the-art methods and 12.6 points higher than existing baselines on the Intersection over Union (IoU) metric without any post-processing. Code and models will be made publicly available.
Adversarial Loss for Semantic Segmentation of Aerial Imagery
Jan 18, 2020


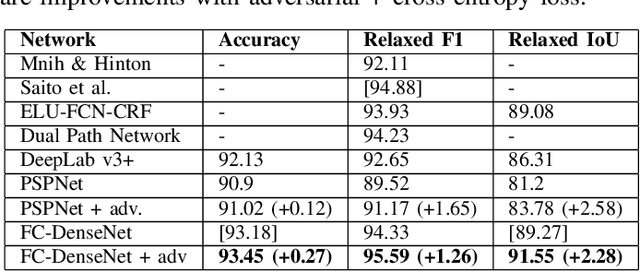
Automatic building extraction from aerial imagery has several applications in urban planning, disaster management, and change detection. In recent years, several works have adopted deep convolutional neural networks (CNNs) for building extraction, since they produce rich features that are invariant against lighting conditions, shadows, etc. Although several advances have been made, building extraction from aerial imagery still presents multiple challenges. Most of the deep learning segmentation methods optimize the per-pixel loss with respect to the ground truth without knowledge of the context. This often leads to imperfect outputs that may lead to missing or unrefined regions. In this work, we propose a novel loss function combining both adversarial and cross-entropy losses that learn to understand both local and global contexts for semantic segmentation. The newly proposed loss function deployed on the DeepLab v3+ network obtains state-of-the-art results on the Massachusetts buildings dataset. The loss function improves the structure and refines the edges of buildings without requiring any of the commonly used post-processing methods, such as Conditional Random Fields. We also perform ablation studies to understand the impact of the adversarial loss. Finally, the proposed method achieves a relaxed F1 score of 95.59% on the Massachusetts buildings dataset compared to the previous best F1 of 94.88%.
Privacy Protection in Street-View Panoramas using Depth and Multi-View Imagery
Mar 27, 2019
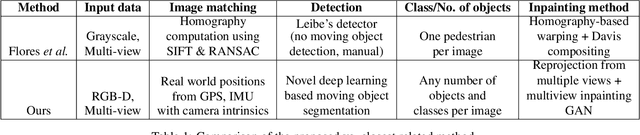
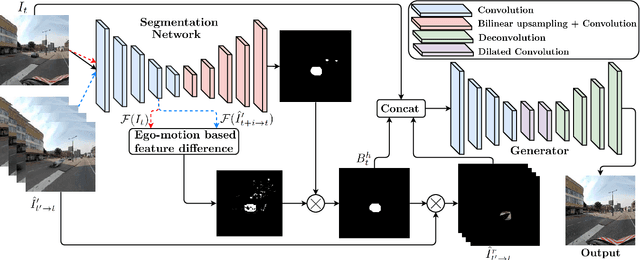

The current paradigm in privacy protection in street-view images is to detect and blur sensitive information. In this paper, we propose a framework that is an alternative to blurring, which automatically removes and inpaints moving objects (e.g. pedestrians, vehicles) in street-view imagery. We propose a novel moving object segmentation algorithm exploiting consistencies in depth across multiple street-view images that are later combined with the results of a segmentation network. The detected moving objects are removed and inpainted with information from other views, to obtain a realistic output image such that the moving object is not visible anymore. We evaluate our results on a dataset of 1000 images to obtain a peak noise-to-signal ratio (PSNR) and L1 loss of 27.2 dB and 2.5%, respectively. To ensure the subjective quality, To assess overall quality, we also report the results of a survey conducted on 35 professionals, asked to visually inspect the images whether object removal and inpainting had taken place. The inpainting dataset will be made publicly available for scientific benchmarking purposes at https://research.cyclomedia.com
Aggregated Deep Local Features for Remote Sensing Image Retrieval
Mar 22, 2019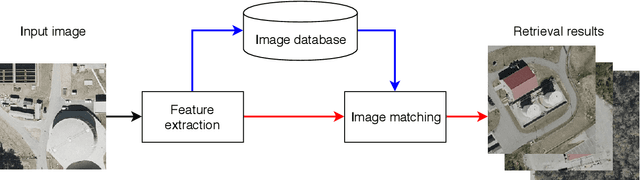


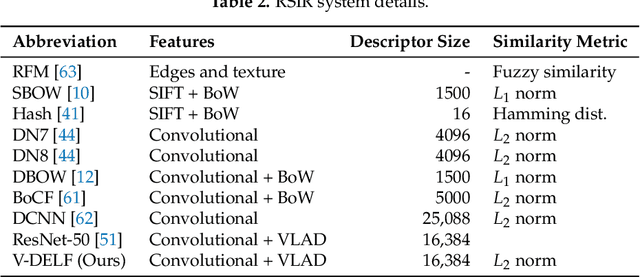
Remote Sensing Image Retrieval remains a challenging topic due to the special nature of Remote Sensing Imagery. Such images contain various different semantic objects, which clearly complicates the retrieval task. In this paper, we present an image retrieval pipeline that uses attentive, local convolutional features and aggregates them using the Vector of Locally Aggregated Descriptors (VLAD) to produce a global descriptor. We study various system parameters such as the multiplicative and additive attention mechanisms and descriptor dimensionality. We propose a query expansion method that requires no external inputs. Experiments demonstrate that even without training, the local convolutional features and global representation outperform other systems. After system tuning, we can achieve state-of-the-art or competitive results. Furthermore, we observe that our query expansion method increases overall system performance by about 3%, using only the top-three retrieved images. Finally, we show how dimensionality reduction produces compact descriptors with increased retrieval performance and fast retrieval computation times, e.g. 50% faster than the current systems.
* Published in Remote Sensing. The first two authors have equal contribution
LiDAR-assisted Large-scale Privacy Protection in Street-view Cycloramas
Mar 13, 2019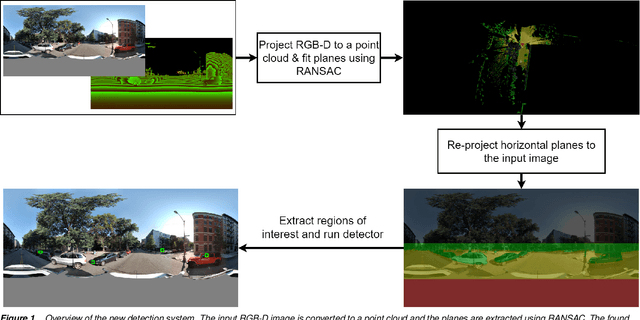
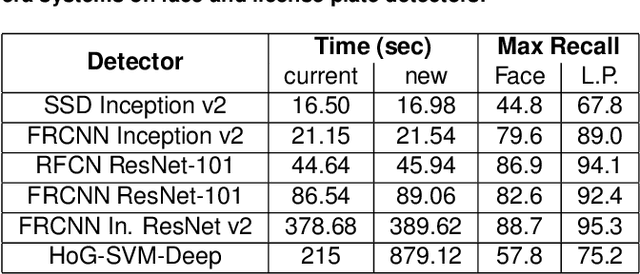
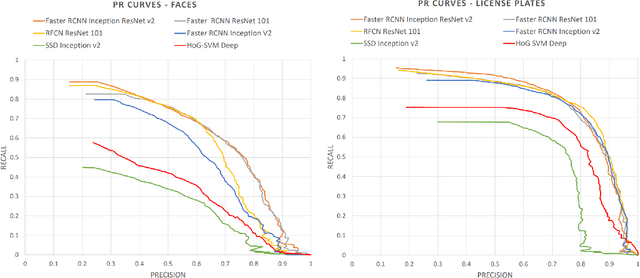

Recently, privacy has a growing importance in several domains, especially in street-view images. The conventional way to achieve this is to automatically detect and blur sensitive information from these images. However, the processing cost of blurring increases with the ever-growing resolution of images. We propose a system that is cost-effective even after increasing the resolution by a factor of 2.5. The new system utilizes depth data obtained from LiDAR to significantly reduce the search space for detection, thereby reducing the processing cost. Besides this, we test several detectors after reducing the detection space and provide an alternative solution based on state-of-the-art deep learning detectors to the existing HoG-SVM-Deep system that is faster and has a higher performance.
Towards Accurate Camera Geopositioning by Image Matching
Mar 13, 2019In this work, we present a camera geopositioning system based on matching a query image against a database with panoramic images. For matching, our system uses memory vectors aggregated from global image descriptors based on convolutional features to facilitate fast searching in the database. To speed up searching, a clustering algorithm is used to balance geographical positioning and computation time. We refine the obtained position from the query image using a new outlier removal algorithm. The matching of the query image is obtained with a recall@5 larger than 90% for panorama-to-panorama matching. We cluster available panoramas from geographically adjacent locations into a single compact representation and observe computational gains of approximately 50% at the cost of only a small (approximately 3%) recall loss. Finally, we present a coordinate estimation algorithm that reduces the median geopositioning error by up to 20%.
Bootstrapped CNNs for Building Segmentation on RGB-D Aerial Imagery
Oct 08, 2018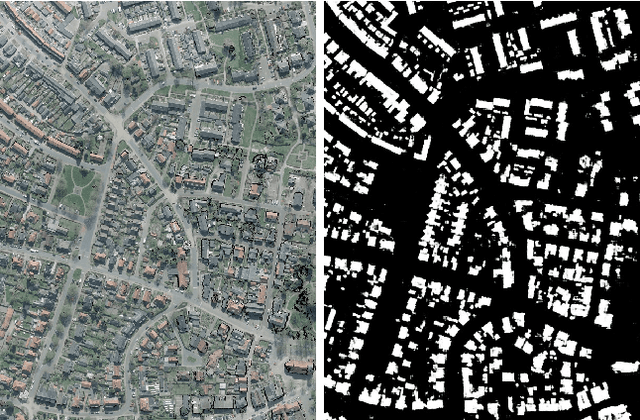


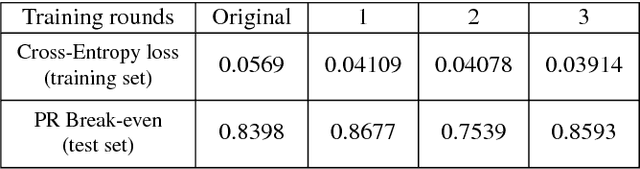
Detection of buildings and other objects from aerial images has various applications in urban planning and map making. Automated building detection from aerial imagery is a challenging task, as it is prone to varying lighting conditions, shadows and occlusions. Convolutional Neural Networks (CNNs) are robust against some of these variations, although they fail to distinguish easy and difficult examples. We train a detection algorithm from RGB-D images to obtain a segmented mask by using the CNN architecture DenseNet.First, we improve the performance of the model by applying a statistical re-sampling technique called Bootstrapping and demonstrate that more informative examples are retained. Second, the proposed method outperforms the non-bootstrapped version by utilizing only one-sixth of the original training data and it obtains a precision-recall break-even of 95.10% on our aerial imagery dataset.
Conditional Transfer with Dense Residual Attention: Synthesizing traffic signs from street-view imagery
Sep 05, 2018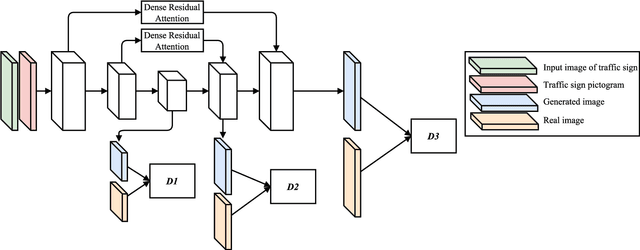
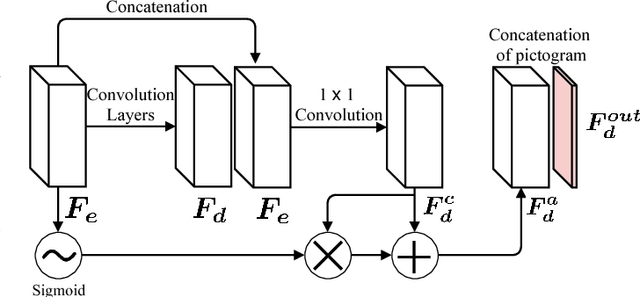
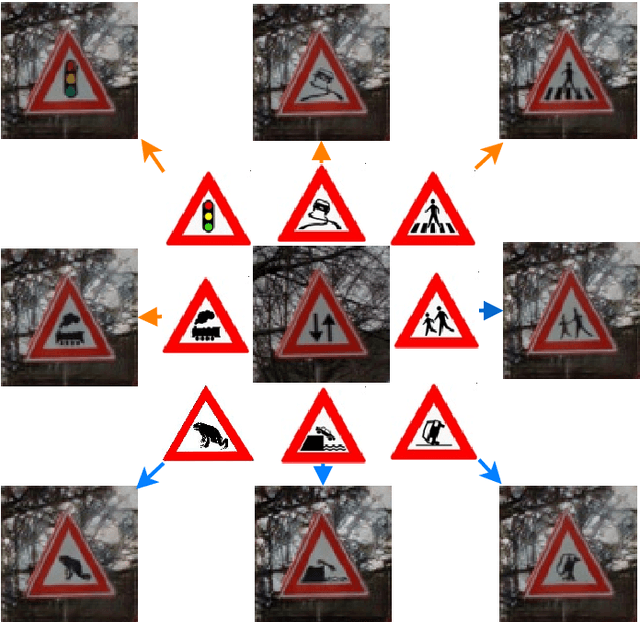

Object detection and classification of traffic signs in street-view imagery is an essential element for asset management, map making and autonomous driving. However, some traffic signs occur rarely and consequently, they are difficult to recognize automatically. To improve the detection and classification rates, we propose to generate images of traffic signs, which are then used to train a detector/classifier. In this research, we present an end-to-end framework that generates a realistic image of a traffic sign from a given image of a traffic sign and a pictogram of the target class. We propose a residual attention mechanism with dense concatenation called Dense Residual Attention, that preserves the background information while transferring the object information. We also propose to utilize multi-scale discriminators, so that the smaller scales of the output guide the higher resolution output. We have performed detection and classification tests across a large number of traffic sign classes, by training the detector using the combination of real and generated data. The newly trained model reduces the number of false positives by 1.2 - 1.5% at 99% recall in the detection tests and an absolute improvement of 4.65% (top-1 accuracy) in the classification tests.