 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISLIX: An XAI Framework for Validating Vision Models with Slice Discovery and Analysis
May 06, 2025Real-world machine learning models require rigorous evaluation before deployment, especially in safety-critical domains like autonomous driving and surveillance. The evaluation of machine learning models often focuses on data slices, which are subsets of the data that share a set of characteristics. Data slice finding automatically identifies conditions or data subgroups where models underperform, aiding developers in mitigating performance issues. Despite its popularity and effectiveness, data slicing for vision model validation faces several challenges. First, data slicing often needs additional image metadata or visual concepts, and falls short in certain computer vision tasks, such as object detection. Second, understanding data slices is a labor-intensive and mentally demanding process that heavily relies on the expert's domain knowledge. Third, data slicing lacks a human-in-the-loop solution that allows experts to form hypothesis and test them interactively. To overcome these limitations and better support the machine learning operations lifecycle, we introduce VISLIX, a novel visual analytics framework that employs state-of-the-art foundation models to help domain experts analyze slices in computer vision models. Our approach does not require image metadata or visual concepts, automatically generates natural language insights, and allows users to test data slice hypothesis interactively. We evaluate VISLIX with an expert study and three use cases, that demonstrate the effectiveness of our tool in providing comprehensive insights for validating object detection models.
SLIM: Spuriousness Mitigation with Minimal Human Annotations
Jul 08, 2024
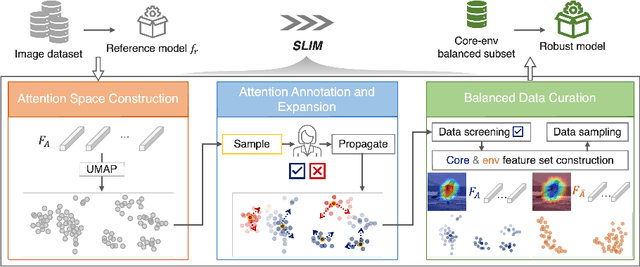
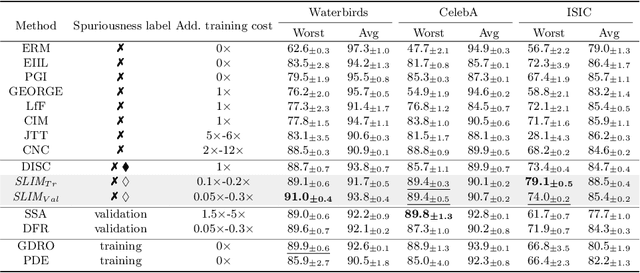

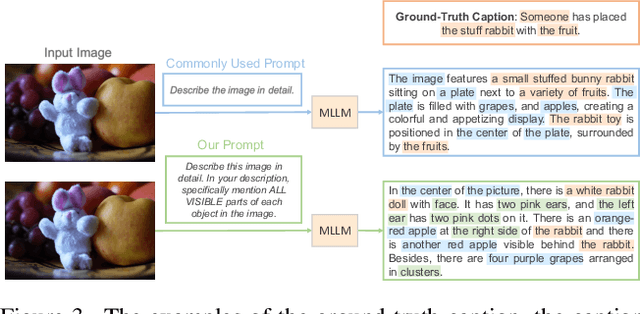
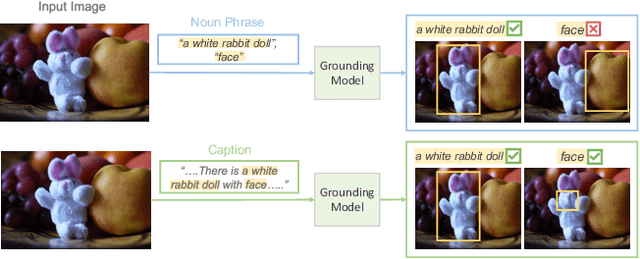
Recent studies highlight that deep learning models often learn spurious features mistakenly linked to labels, compromising their reliability in real-world scenarios where such correlations do not hold. Despite the increasing research effort, existing solutions often face two main challenges: they either demand substantial annotations of spurious attributes, or they yield less competitive outcomes with expensive training when additional annotations are absent. In this paper, we introduce SLIM, a cost-effective and performance-targeted approach to reducing spurious correlations in deep learning. Our method leverages a human-in-the-loop protocol featuring a novel attention labeling mechanism with a constructed attention representation space. SLIM significantly reduces the need for exhaustive additional labeling, requiring human input for fewer than 3% of instances. By prioritizing data quality over complicated training strategies, SLIM curates a smaller yet more feature-balanced data subset, fostering the development of spuriousness-robust models. Experimental validations across key benchmarks demonstrate that SLIM competes with or exceeds the performance of leading methods while significantly reducing costs. The SLIM framework thus presents a promising path for developing reliable models more efficiently. Our code is available in https://github.com/xiweix/SLIM.git/.
USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation
Jun 07, 2024

The open-vocabulary image segmentation task involves partitioning images into semantically meaningful segments and classifying them with flexible text-defined categories. The recent vision-based foundation models such as the Segment Anything Model (SAM) have shown superior performance in generating class-agnostic image segments. The main challenge in open-vocabulary image segmentation now lies in accurately classifying these segments into text-defined categories. In this paper, we introduce the Universal Segment Embedding (USE) framework to address this challenge. This framework is comprised of two key components: 1) a data pipeline designed to efficiently curate a large amount of segment-text pairs at various granularities, and 2) a universal segment embedding model that enables precise segment classification into a vast range of text-defined categories. The USE model can not only help open-vocabulary image segmentation but also facilitate other downstream tasks (e.g., querying and ranking). Through comprehensive experimental studies on semantic segmentation and part segmentation benchmarks, we demonstrate that the USE framework outperforms state-of-the-art open-vocabulary segmentation methods.
A Reliable Framework for Human-in-the-Loop Anomaly Detection in Time Series
May 07, 2024



Time series anomaly detection is a critical machine learning task for numerous applications, such as finance, healthcare, and industrial systems. However, even high-performed models may exhibit potential issues such as biases, leading to unreliable outcomes and misplaced confidence. While model explanation techniques, particularly visual explanations, offer valuable insights to detect such issues by elucidating model attributions of their decision, many limitations still exist -- They are primarily instance-based and not scalable across dataset, and they provide one-directional information from the model to the human side, lacking a mechanism for users to address detected issues. To fulfill these gaps, we introduce HILAD, a novel framework designed to foster a dynamic and bidirectional collaboration between humans and AI for enhancing anomaly detection models in time series. Through our visual interface, HILAD empowers domain experts to detect, interpret, and correct unexpected model behaviors at scale. Our evaluation with two time series datasets and user studies demonstrates the effectiveness of HILAD in fostering a deeper human understanding, immediate corrective actions, and the reliability enhancement of models.
AttributionScanner: A Visual Analytics System for Metadata-Free Data-Slicing Based Model Validation
Jan 12, 2024Data slice-finding is an emerging technique for evaluating machine learning models. It works by identifying subgroups within a specified dataset that exhibit poor performance, often defined by distinct feature sets or meta-information. However, in the context of unstructured image data, data slice-finding poses two notable challenges: it requires additional metadata -- a laborious and costly requirement, and also demands non-trivial efforts for interpreting the root causes of the underperformance within data slices. To address these challenges, we introduce AttributionScanner, an innovative human-in-the-loop Visual Analytics (VA) system, designed for data-slicing-based machine learning (ML) model validation. Our approach excels in identifying interpretable data slices, employing explainable features extracted through the lens of Explainable AI (XAI) techniques, and removing the necessity for additional metadata of textual annotations or cross-model embeddings. AttributionScanner demonstrates proficiency in pinpointing critical model issues, including spurious correlations and mislabeled data. Our novel VA interface visually summarizes data slices, enabling users to gather insights into model behavior patterns effortlessly. Furthermore, our framework closes the ML Development Cycle by empowering domain experts to address model issues by using a cutting-edge neural network regularization technique. The efficacy of AttributionScanner is underscored through two prototype use cases, elucidating its substantial effectiveness in model validation for vision-centric tasks. Our approach paves the way for ML researchers and practitioners to drive interpretable model validation in a data-efficient way, ultimately leading to more reliable and accurate models.
SUNY: A Visual Interpretation Framework for Convolutional Neural Networks from a Necessary and Sufficient Perspective
Mar 01, 2023



Researchers have proposed various methods for visually interpreting the Convolutional Neural Network (CNN) via saliency maps, which include Class-Activation-Map (CAM) based approaches as a leading family. However, in terms of the internal design logic, existing CAM-based approaches often overlook the causal perspective that answers the core "why" question to help humans understand the explanation. Additionally, current CNN explanations lack the consideration of both necessity and sufficiency, two complementary sides of a desirable explanation. This paper presents a causality-driven framework, SUNY, designed to rationalize the explanations toward better human understanding. Using the CNN model's input features or internal filters as hypothetical causes, SUNY generates explanations by bi-directional quantifications on both the necessary and sufficient perspectives. Extensive evaluations justify that SUNY not only produces more informative and convincing explanations from the angles of necessity and sufficiency, but also achieves performances competitive to other approaches across different CNN architectures over large-scale datasets, including ILSVRC2012 and CUB-200-2011.
CNNC: A Visual Analytics System for Comparative Studies of Deep Convolutional Neural Networks
Oct 25, 2021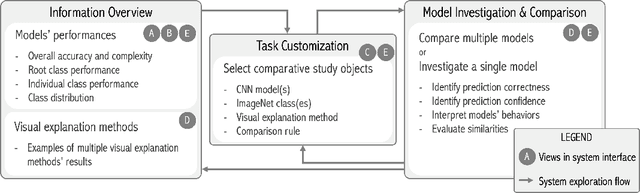
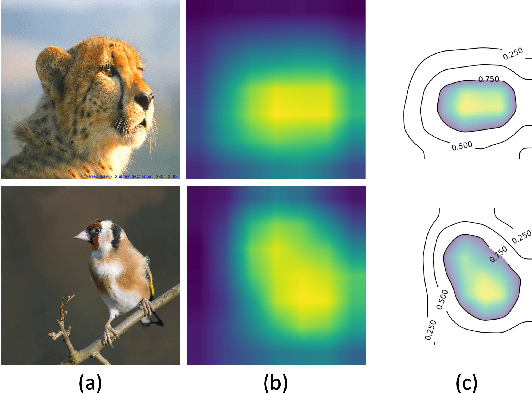

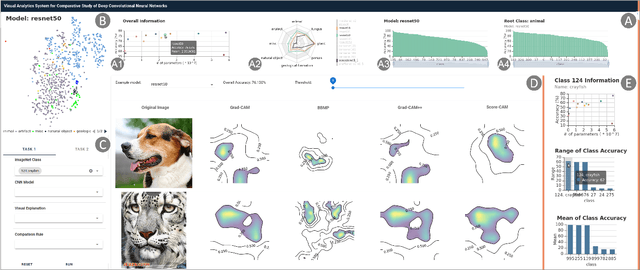
The rapid development of Convolutional Neural Networks (CNNs) in recent years has triggered significant breakthroughs in many machine learning (ML) applications. The ability to understand and compare various CNN models available is thus essential. The conventional approach with visualizing each model's quantitative features, such as classification accuracy and computational complexity, is not sufficient for a deeper understanding and comparison of the behaviors of different models. Moreover, most of the existing tools for assessing CNN behaviors only support comparison between two models and lack the flexibility of customizing the analysis tasks according to user needs. This paper presents a visual analytics system, CNN Comparator (CNNC), that supports the in-depth inspection of a single CNN model as well as comparative studies of two or more models. The ability to compare a larger number of (e.g., tens of) models especially distinguishes our system from previous ones. With a carefully designed model visualization and explaining support, CNNC facilitates a highly interactive workflow that promptly presents both quantitative and qualitative information at each analysis stage. We demonstrate CNNC's effectiveness for assisting ML practitioners in evaluating and comparing multiple CNN models through two use cases and one preliminary evaluation study using the image classification tasks on the ImageNet dataset.