 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIM: Spuriousness Mitigation with Minimal Human Annotations
Paper and Code

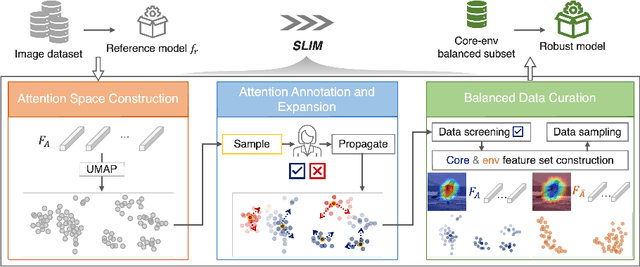
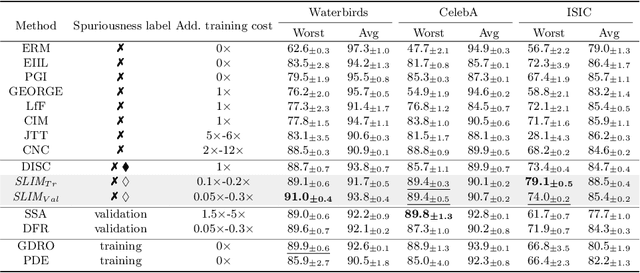

Recent studies highlight that deep learning models often learn spurious features mistakenly linked to labels, compromising their reliability in real-world scenarios where such correlations do not hold. Despite the increasing research effort, existing solutions often face two main challenges: they either demand substantial annotations of spurious attributes, or they yield less competitive outcomes with expensive training when additional annotations are absent. In this paper, we introduce SLIM, a cost-effective and performance-targeted approach to reducing spurious correlations in deep learning. Our method leverages a human-in-the-loop protocol featuring a novel attention labeling mechanism with a constructed attention representation space. SLIM significantly reduces the need for exhaustive additional labeling, requiring human input for fewer than 3% of instances. By prioritizing data quality over complicated training strategies, SLIM curates a smaller yet more feature-balanced data subset, fostering the development of spuriousness-robust models. Experimental validations across key benchmarks demonstrate that SLIM competes with or exceeds the performance of leading methods while significantly reducing costs. The SLIM framework thus presents a promising path for developing reliable models more efficiently. Our code is available in https://github.com/xiweix/SLIM.git/.