 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIM: Spuriousness Mitigation with Minimal Human Annotations
Jul 08, 2024
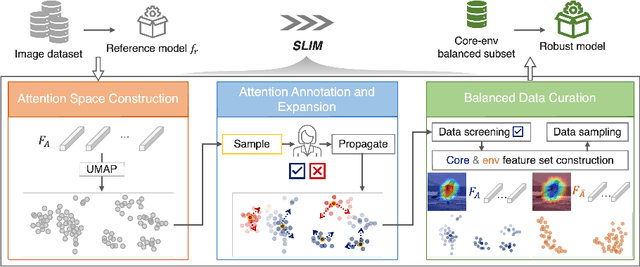
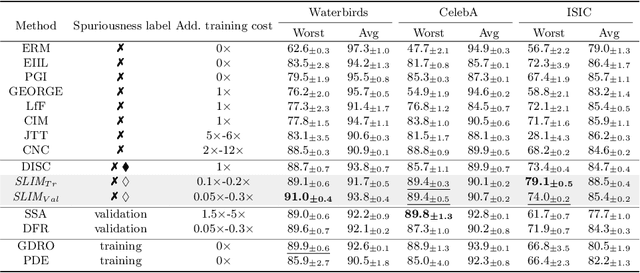

Recent studies highlight that deep learning models often learn spurious features mistakenly linked to labels, compromising their reliability in real-world scenarios where such correlations do not hold. Despite the increasing research effort, existing solutions often face two main challenges: they either demand substantial annotations of spurious attributes, or they yield less competitive outcomes with expensive training when additional annotations are absent. In this paper, we introduce SLIM, a cost-effective and performance-targeted approach to reducing spurious correlations in deep learning. Our method leverages a human-in-the-loop protocol featuring a novel attention labeling mechanism with a constructed attention representation space. SLIM significantly reduces the need for exhaustive additional labeling, requiring human input for fewer than 3% of instances. By prioritizing data quality over complicated training strategies, SLIM curates a smaller yet more feature-balanced data subset, fostering the development of spuriousness-robust models. Experimental validations across key benchmarks demonstrate that SLIM competes with or exceeds the performance of leading methods while significantly reducing costs. The SLIM framework thus presents a promising path for developing reliable models more efficiently. Our code is available in https://github.com/xiweix/SLIM.git/.
A Reliable Framework for Human-in-the-Loop Anomaly Detection in Time Series
May 07, 2024



Time series anomaly detection is a critical machine learning task for numerous applications, such as finance, healthcare, and industrial systems. However, even high-performed models may exhibit potential issues such as biases, leading to unreliable outcomes and misplaced confidence. While model explanation techniques, particularly visual explanations, offer valuable insights to detect such issues by elucidating model attributions of their decision, many limitations still exist -- They are primarily instance-based and not scalable across dataset, and they provide one-directional information from the model to the human side, lacking a mechanism for users to address detected issues. To fulfill these gaps, we introduce HILAD, a novel framework designed to foster a dynamic and bidirectional collaboration between humans and AI for enhancing anomaly detection models in time series. Through our visual interface, HILAD empowers domain experts to detect, interpret, and correct unexpected model behaviors at scale. Our evaluation with two time series datasets and user studies demonstrates the effectiveness of HILAD in fostering a deeper human understanding, immediate corrective actions, and the reliability enhancement of models.
SUNY: A Visual Interpretation Framework for Convolutional Neural Networks from a Necessary and Sufficient Perspective
Mar 01, 2023



Researchers have proposed various methods for visually interpreting the Convolutional Neural Network (CNN) via saliency maps, which include Class-Activation-Map (CAM) based approaches as a leading family. However, in terms of the internal design logic, existing CAM-based approaches often overlook the causal perspective that answers the core "why" question to help humans understand the explanation. Additionally, current CNN explanations lack the consideration of both necessity and sufficiency, two complementary sides of a desirable explanation. This paper presents a causality-driven framework, SUNY, designed to rationalize the explanations toward better human understanding. Using the CNN model's input features or internal filters as hypothetical causes, SUNY generates explanations by bi-directional quantifications on both the necessary and sufficient perspectives. Extensive evaluations justify that SUNY not only produces more informative and convincing explanations from the angles of necessity and sufficiency, but also achieves performances competitive to other approaches across different CNN architectures over large-scale datasets, including ILSVRC2012 and CUB-200-2011.