 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Ad-hoc Categorization with Contextualized Feature Learning
Dec 18, 2025Adaptive categorization of visual scenes is essential for AI agents to handle changing tasks. Unlike fixed common categories for plants or animals, ad-hoc categories are created dynamically to serve specific goals. We study open ad-hoc categorization: Given a few labeled exemplars and abundant unlabeled data, the goal is to discover the underlying context and to expand ad-hoc categories through semantic extension and visual clustering around it. Building on the insight that ad-hoc and common categories rely on similar perceptual mechanisms, we propose OAK, a simple model that introduces a small set of learnable context tokens at the input of a frozen CLIP and optimizes with both CLIP's image-text alignment objective and GCD's visual clustering objective. On Stanford and Clevr-4 datasets, OAK achieves state-of-the-art in accuracy and concept discovery across multiple categorizations, including 87.4% novel accuracy on Stanford Mood, surpassing CLIP and GCD by over 50%. Moreover, OAK produces interpretable saliency maps, focusing on hands for Action, faces for Mood, and backgrounds for Location, promoting transparency and trust while enabling adaptive and generalizable categorization.
* 26 pages, 17 figures
USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation
Jun 07, 2024

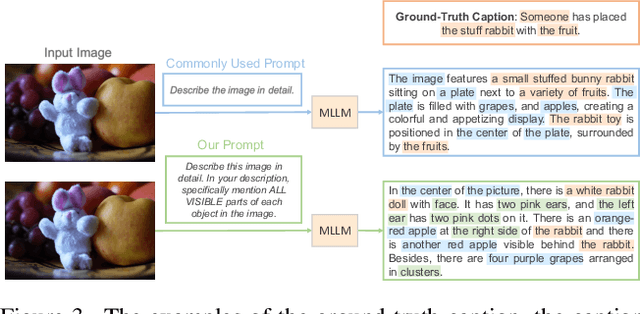
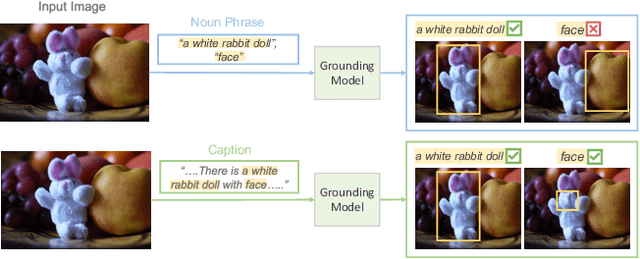
The open-vocabulary image segmentation task involves partitioning images into semantically meaningful segments and classifying them with flexible text-defined categories. The recent vision-based foundation models such as the Segment Anything Model (SAM) have shown superior performance in generating class-agnostic image segments. The main challenge in open-vocabulary image segmentation now lies in accurately classifying these segments into text-defined categories. In this paper, we introduce the Universal Segment Embedding (USE) framework to address this challenge. This framework is comprised of two key components: 1) a data pipeline designed to efficiently curate a large amount of segment-text pairs at various granularities, and 2) a universal segment embedding model that enables precise segment classification into a vast range of text-defined categories. The USE model can not only help open-vocabulary image segmentation but also facilitate other downstream tasks (e.g., querying and ranking). Through comprehensive experimental studies on semantic segmentation and part segmentation benchmarks, we demonstrate that the USE framework outperforms state-of-the-art open-vocabulary segmentation methods.
A streamlined Approach to Multimodal Few-Shot Class Incremental Learning for Fine-Grained Datasets
Mar 10, 2024



Few-shot Class-Incremental Learning (FSCIL) poses the challenge of retaining prior knowledge while learning from limited new data streams, all without overfitting. The rise of Vision-Language models (VLMs) has unlocked numerous applications, leveraging their existing knowledge to fine-tune on custom data. However, training the whole model is computationally prohibitive, and VLMs while being versatile in general domains still struggle with fine-grained datasets crucial for many applications. We tackle these challenges with two proposed simple modules. The first, Session-Specific Prompts (SSP), enhances the separability of image-text embeddings across sessions. The second, Hyperbolic distance, compresses representations of image-text pairs within the same class while expanding those from different classes, leading to better representations. Experimental results demonstrate an average 10-point increase compared to baselines while requiring at least 8 times fewer trainable parameters. This improvement is further underscored on our three newly introduced fine-grained datasets.
GradOrth: A Simple yet Efficient Out-of-Distribution Detection with Orthogonal Projection of Gradients
Aug 01, 2023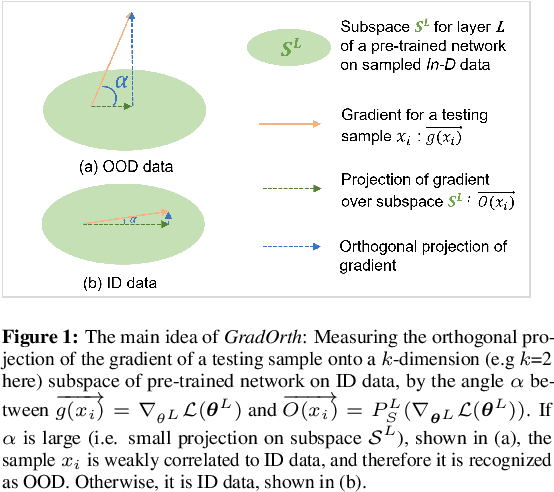
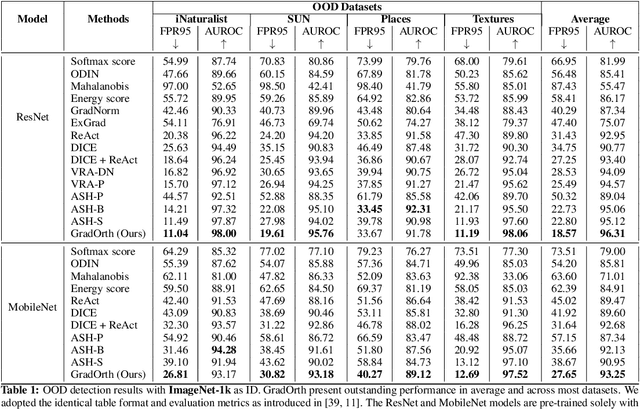
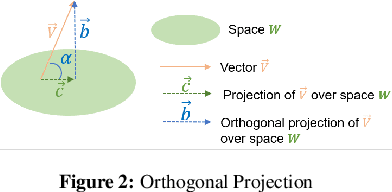

Detecting out-of-distribution (OOD) data is crucial for ensuring the safe deployment of machine learning models in real-world applications. However, existing OOD detection approaches primarily rely on the feature maps or the full gradient space information to derive OOD scores neglecting the role of most important parameters of the pre-trained network over in-distribution (ID) data. In this study, we propose a novel approach called GradOrth to facilitate OOD detection based on one intriguing observation that the important features to identify OOD data lie in the lower-rank subspace of in-distribution (ID) data. In particular, we identify OOD data by computing the norm of gradient projection on the subspaces considered important for the in-distribution data. A large orthogonal projection value (i.e. a small projection value) indicates the sample as OOD as it captures a weak correlation of the ID data. This simple yet effective method exhibits outstanding performance, showcasing a notable reduction in the average false positive rate at a 95% true positive rate (FPR95) of up to 8% when compared to the current state-of-the-art methods.
UP-DP: Unsupervised Prompt Learning for Data Pre-Selection with Vision-Language Models
Jul 20, 2023In this study, we investigate the task of data pre-selection, which aims to select instances for labeling from an unlabeled dataset through a single pass, thereby optimizing performance for undefined downstream tasks with a limited annotation budget. Previous approaches to data pre-selection relied solely on visual features extracted from foundation models, such as CLIP and BLIP-2, but largely ignored the powerfulness of text features. In this work, we argue that, with proper design, the joint feature space of both vision and text can yield a better representation for data pre-selection. To this end, we introduce UP-DP, a simple yet effective unsupervised prompt learning approach that adapts vision-language models, like BLIP-2, for data pre-selection. Specifically, with the BLIP-2 parameters frozen, we train text prompts to extract the joint features with improved representation, ensuring a diverse cluster structure that covers the entire dataset. We extensively compare our method with the state-of-the-art using seven benchmark datasets in different settings, achieving up to a performance gain of 20%. Interestingly, the prompts learned from one dataset demonstrate significant generalizability and can be applied directly to enhance the feature extraction of BLIP-2 from other datasets. To the best of our knowledge, UP-DP is the first work to incorporate unsupervised prompt learning in a vision-language model for data pre-selection.
Hyp-OW: Exploiting Hierarchical Structure Learning with Hyperbolic Distance Enhances Open World Object Detection
Jun 25, 2023Open World Object Detection (OWOD) is a challenging and realistic task that extends beyond the scope of standard Object Detection task. It involves detecting both known and unknown objects while integrating learned knowledge for future tasks. However, the level of 'unknownness' varies significantly depending on the context. For example, a tree is typically considered part of the background in a self-driving scene, but it may be significant in a household context. We argue that this external or contextual information should already be embedded within the known classes. In other words, there should be a semantic or latent structure relationship between the known and unknown items to be discovered. Motivated by this observation, we propose Hyp-OW, a method that learns and models hierarchical representation of known items through a SuperClass Regularizer. Leveraging this learned representation allows us to effectively detect unknown objects using a Similarity Distance-based Relabeling module. Extensive experiments on benchmark datasets demonstrate the effectiveness of Hyp-OW achieving improvement in both known and unknown detection (up to 6 points). These findings are particularly pronounced in our newly designed benchmark, where a strong hierarchical structure exists between known and unknown objects.
Cryo-shift: Reducing domain shift in cryo-electron subtomograms with unsupervised domain adaptation and randomization
Nov 17, 2021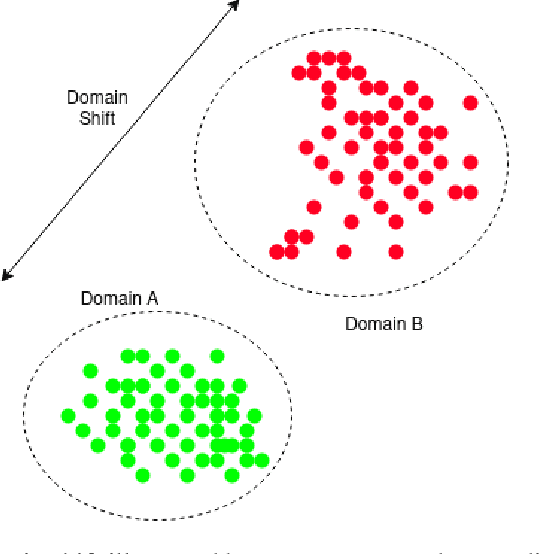

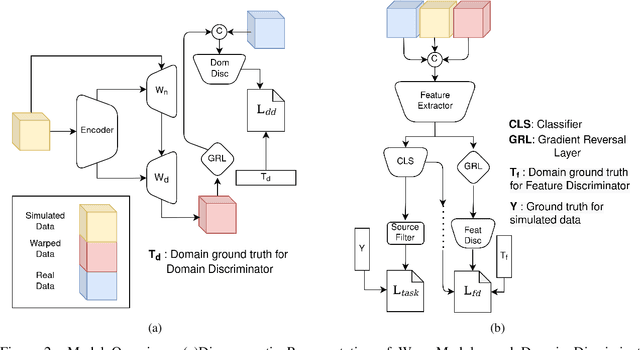

Cryo-Electron Tomography (cryo-ET) is a 3D imaging technology that enables the visualization of subcellular structures in situ at near-atomic resolution. Cellular cryo-ET images help in resolving the structures of macromolecules and determining their spatial relationship in a single cell, which has broad significance in cell and structural biology. Subtomogram classification and recognition constitute a primary step in the systematic recovery of these macromolecular structures. Supervised deep learning methods have been proven to be highly accurate and efficient for subtomogram classification, but suffer from limited applicability due to scarcity of annotated data. While generating simulated data for training supervised models is a potential solution, a sizeable difference in the image intensity distribution in generated data as compared to real experimental data will cause the trained models to perform poorly in predicting classes on real subtomograms. In this work, we present Cryo-Shift, a fully unsupervised domain adaptation and randomization framework for deep learning-based cross-domain subtomogram classification. We use unsupervised multi-adversarial domain adaption to reduce the domain shift between features of simulated and experimental data. We develop a network-driven domain randomization procedure with `warp' modules to alter the simulated data and help the classifier generalize better on experimental data. We do not use any labeled experimental data to train our model, whereas some of the existing alternative approaches require labeled experimental samples for cross-domain classification. Nevertheless, Cryo-Shift outperforms the existing alternative approaches in cross-domain subtomogram classification in extensive evaluation studies demonstrated herein using both simulated and experimental data.
* 14 pages
Active Learning in Video Tracking
Jan 06, 2020
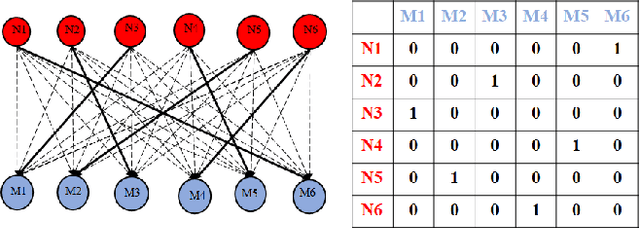
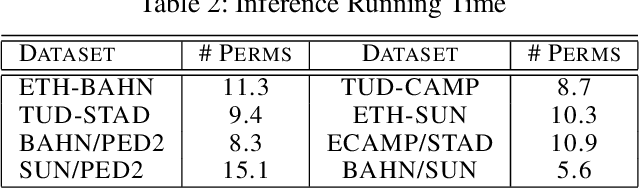
Active learning methods, like uncertainty sampling, combined with probabilistic prediction techniques have achieved success in various problems like image classification and text classification. For more complex multivariate prediction tasks, the relationships between labels play an important role in designing structured classifiers with better performance. However, computational time complexity limits prevalent probabilistic methods from effectively supporting active learning. Specifically, while non-probabilistic methods based on structured support vector machines can be tractably applied to predicting bipartite matchings, conditional random fields are intractable for these structures. We propose an adversarial approach for active learning with structured prediction domains that is tractable for matching. We evaluate this approach algorithmically in an important structured prediction problems: object tracking in videos. We demonstrate better accuracy and computational efficiency for our proposed method.
Consistent Robust Adversarial Prediction for General Multiclass Classification
Dec 18, 2018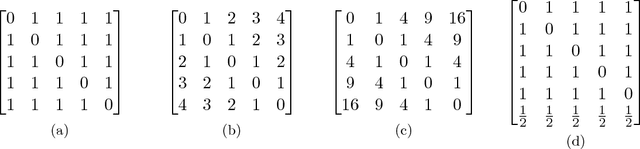
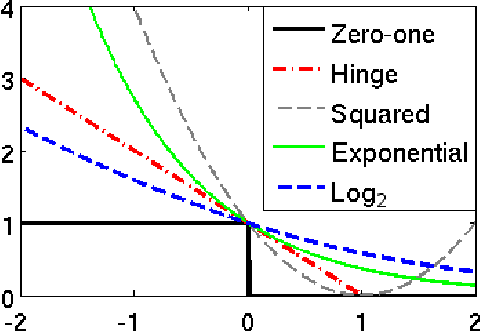
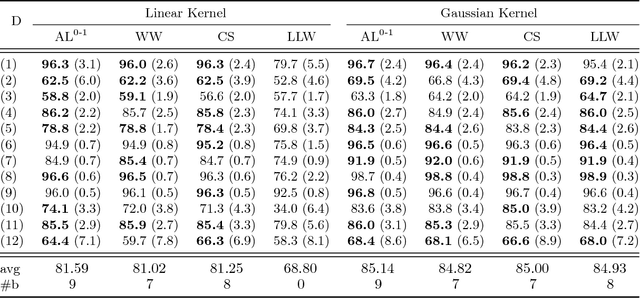
We propose a robust adversarial prediction framework for general multiclass classification. Our method seeks predictive distributions that robustly optimize non-convex and non-continuous multiclass loss metrics against the worst-case conditional label distributions (the adversarial distributions) that (approximately) match the statistics of the training data. Although the optimized loss metrics are non-convex and non-continuous, the dual formulation of the framework is a convex optimization problem that can be recast as a risk minimization model with a prescribed convex surrogate loss we call the adversarial surrogate loss. We show that the adversarial surrogate losses fill an existing gap in surrogate loss construction for general multiclass classification problems, by simultaneously aligning better with the original multiclass loss, guaranteeing Fisher consistency, enabling a way to incorporate rich feature spaces via the kernel trick, and providing competitive performance in practice.
ADA: A Game-Theoretic Perspective on Data Augmentation for Object Detection
Dec 12, 2017
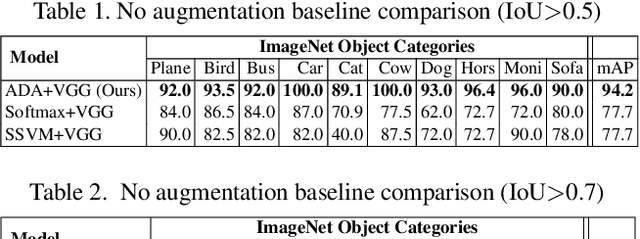

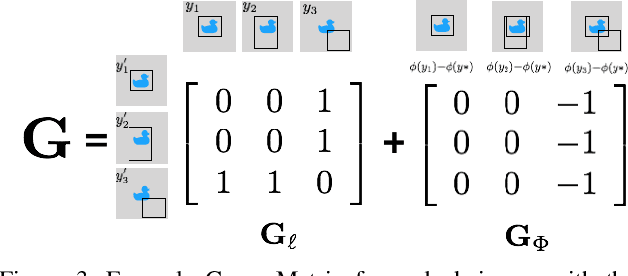
The use of random perturbations of ground truth data, such as random translation or scaling of bounding boxes, is a common heuristic used for data augmentation that has been shown to prevent overfitting and improve generalization. Since the design of data augmentation is largely guided by reported best practices, it is difficult to understand if those design choices are optimal. To provide a more principled perspective, we develop a game-theoretic interpretation of data augmentation in the context of object detection. We aim to find an optimal adversarial perturbations of the ground truth data (i.e., the worst case perturbations) that forces the object bounding box predictor to learn from the hardest distribution of perturbed examples for better test-time performance. We establish that the game theoretic solution, the Nash equilibrium, provides both an optimal predictor and optimal data augmentation distribution. We show that our adversarial method of training a predictor can significantly improve test time performance for the task of object detection. On the ImageNet object detection task, our adversarial approach improves performance by over 16\% compared to the best performing data augmentation method