 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Look Twice: Faster Video Transformers with Run-Length Tokenization
Nov 07, 2024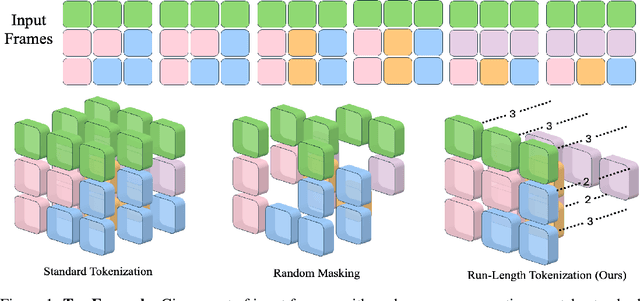
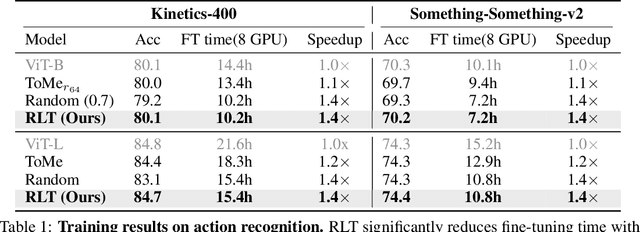
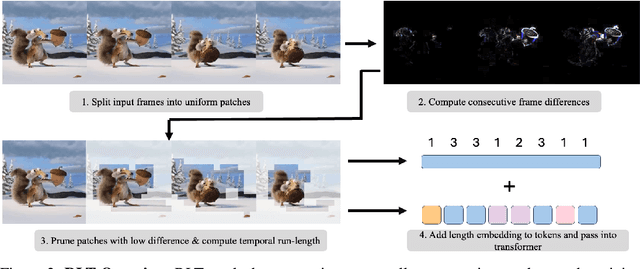
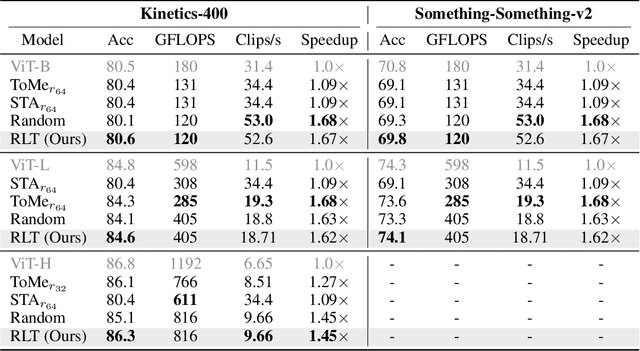
Transformers are slow to train on videos due to extremely large numbers of input tokens, even though many video tokens are repeated over time. Existing methods to remove such uninformative tokens either have significant overhead, negating any speedup, or require tuning for different datasets and examples. We present Run-Length Tokenization (RLT), a simple approach to speed up video transformers inspired by run-length encoding for data compression. RLT efficiently finds and removes runs of patches that are repeated over time prior to model inference, then replaces them with a single patch and a positional encoding to represent the resulting token's new length. Our method is content-aware, requiring no tuning for different datasets, and fast, incurring negligible overhead. RLT yields a large speedup in training, reducing the wall-clock time to fine-tune a video transformer by 30% while matching baseline model performance. RLT also works without any training, increasing model throughput by 35% with only 0.1% drop in accuracy. RLT speeds up training at 30 FPS by more than 100%, and on longer video datasets, can reduce the token count by up to 80%. Our project page is at https://rccchoudhury.github.io/projects/rlt/.
Zero-Shot Video Question Answering with Procedural Programs
Dec 01, 2023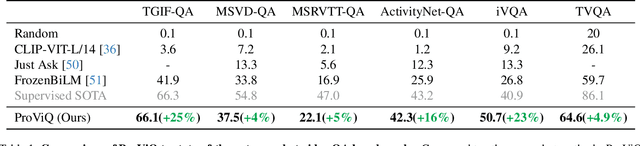
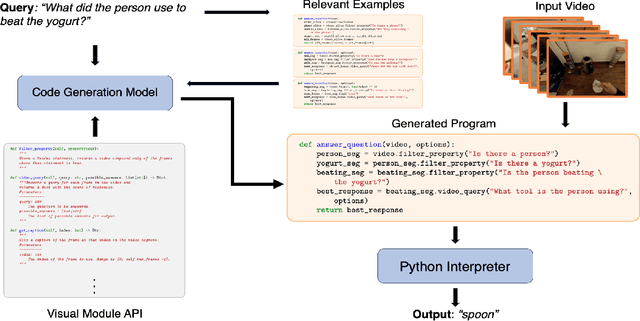
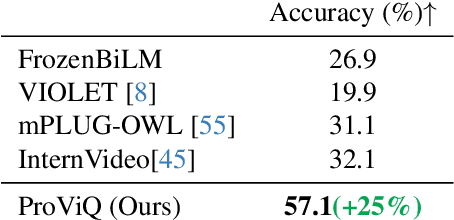
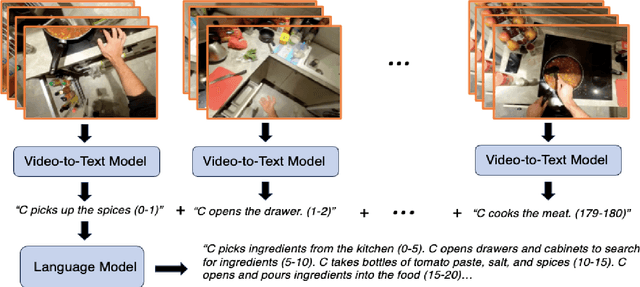
We propose to answer zero-shot questions about videos by generating short procedural programs that derive a final answer from solving a sequence of visual subtasks. We present Procedural Video Querying (ProViQ), which uses a large language model to generate such programs from an input question and an API of visual modules in the prompt, then executes them to obtain the output. Recent similar procedural approaches have proven successful for image question answering, but videos remain challenging: we provide ProViQ with modules intended for video understanding, allowing it to generalize to a wide variety of videos. This code generation framework additionally enables ProViQ to perform other video tasks in addition to question answering, such as multi-object tracking or basic video editing. ProViQ achieves state-of-the-art results on a diverse range of benchmarks, with improvements of up to 25% on short, long, open-ended, and multimodal video question-answering datasets. Our project page is at https://rccchoudhury.github.io/proviq2023.
Deformer: Dynamic Fusion Transformer for Robust Hand Pose Estimation
Mar 09, 2023
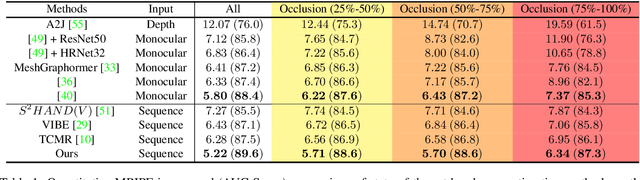
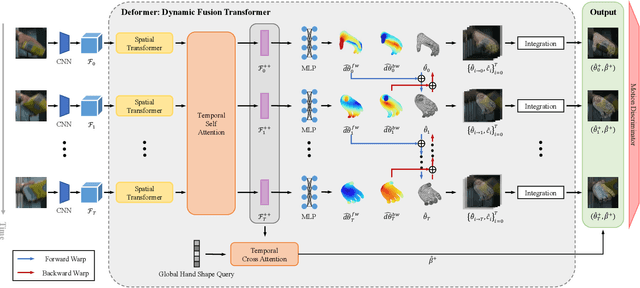

Accurately estimating 3D hand pose is crucial for understanding how humans interact with the world. Despite remarkable progress, existing methods often struggle to generate plausible hand poses when the hand is heavily occluded or blurred. In videos, the movements of the hand allow us to observe various parts of the hand that may be occluded or blurred in a single frame. To adaptively leverage the visual clue before and after the occlusion or blurring for robust hand pose estimation, we propose the Deformer: a framework that implicitly reasons about the relationship between hand parts within the same image (spatial dimension) and different timesteps (temporal dimension). We show that a naive application of the transformer self-attention mechanism is not sufficient because motion blur or occlusions in certain frames can lead to heavily distorted hand features and generate imprecise keys and queries. To address this challenge, we incorporate a Dynamic Fusion Module into Deformer, which predicts the deformation of the hand and warps the hand mesh predictions from nearby frames to explicitly support the current frame estimation. Furthermore, we have observed that errors are unevenly distributed across different hand parts, with vertices around fingertips having disproportionately higher errors than those around the palm. We mitigate this issue by introducing a new loss function called maxMSE that automatically adjusts the weight of every vertex to focus the model on critical hand parts. Extensive experiments show that our method significantly outperforms state-of-the-art methods by 10%, and is more robust to occlusions (over 14%).
HERD: Continuous Human-to-Robot Evolution for Learning from Human Demonstration
Dec 08, 2022The ability to learn from human demonstration endows robots with the ability to automate various tasks. However, directly learning from human demonstration is challenging since the structure of the human hand can be very different from the desired robot gripper. In this work, we show that manipulation skills can be transferred from a human to a robot through the use of micro-evolutionary reinforcement learning, where a five-finger human dexterous hand robot gradually evolves into a commercial robot, while repeated interacting in a physics simulator to continuously update the policy that is first learned from human demonstration. To deal with the high dimensions of robot parameters, we propose an algorithm for multi-dimensional evolution path searching that allows joint optimization of both the robot evolution path and the policy. Through experiments on human object manipulation datasets, we show that our framework can efficiently transfer the expert human agent policy trained from human demonstrations in diverse modalities to target commercial robots.
From Universal Humanoid Control to Automatic Physically Valid Character Creation
Jun 18, 2022

Automatically designing virtual humans and humanoids holds great potential in aiding the character creation process in games, movies, and robots. In some cases, a character creator may wish to design a humanoid body customized for certain motions such as karate kicks and parkour jumps. In this work, we propose a humanoid design framework to automatically generate physically valid humanoid bodies conditioned on sequence(s) of pre-specified human motions. First, we learn a generalized humanoid controller trained on a large-scale human motion dataset that features diverse human motion and body shapes. Second, we use a design-and-control framework to optimize a humanoid's physical attributes to find body designs that can better imitate the pre-specified human motion sequence(s). Leveraging the pre-trained humanoid controller and physics simulation as guidance, our method is able to discover new humanoid designs that are customized to perform pre-specified human motions.
Cost-Aware Evaluation and Model Scaling for LiDAR-Based 3D Object Detection
May 05, 2022

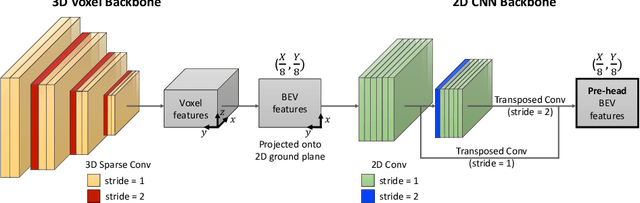
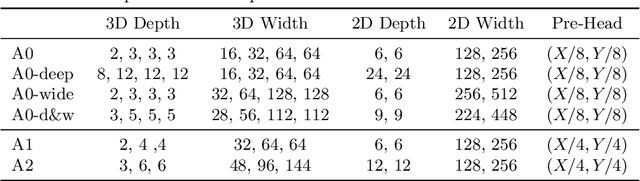
Considerable research efforts have been devoted to LiDAR-based 3D object detection and its empirical performance has been significantly improved. While the progress has been encouraging, we observe an overlooked issue: it is not yet common practice to compare different 3D detectors under the same cost, e.g., inference latency. This makes it difficult to quantify the true performance gain brought by recently proposed architecture designs. The goal of this work is to conduct a cost-aware evaluation of LiDAR-based 3D object detectors. Specifically, we focus on SECOND, a simple grid-based one-stage detector, and analyze its performance under different costs by scaling its original architecture. Then we compare the family of scaled SECOND with recent 3D detection methods, such as Voxel R-CNN and PV-RCNN++. The results are surprising. We find that, if allowed to use the same latency, SECOND can match the performance of PV-RCNN++, the current state-of-the-art method on the Waymo Open Dataset. Scaled SECOND also easily outperforms many recent 3D detection methods published during the past year. We recommend future research control the inference cost in their empirical comparison and include the family of scaled SECOND as a strong baseline when presenting novel 3D detection methods.
Domain Adaptive Hand Keypoint and Pixel Localization in the Wild
Mar 21, 2022
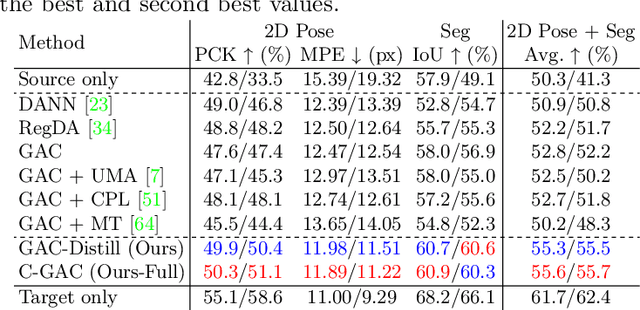
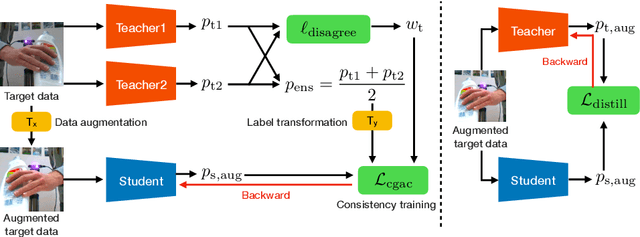
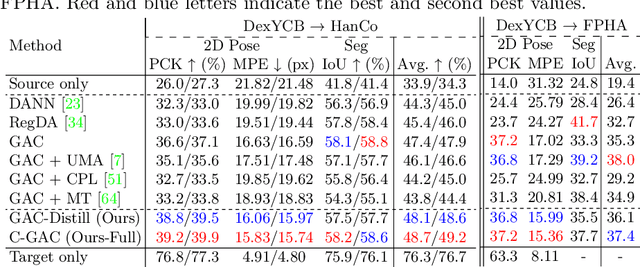
We aim to improve the performance of regressing hand keypoints and segmenting pixel-level hand masks under new imaging conditions (e.g., outdoors) when we only have labeled images taken under very different conditions (e.g., indoors). In the real world, it is important that the model trained for both tasks works under various imaging conditions. However, their variation covered by existing labeled hand datasets is limited. Thus, it is necessary to adapt the model trained on the labeled images (source) to unlabeled images (target) with unseen imaging conditions. While self-training domain adaptation methods (i.e., learning from the unlabeled target images in a self-supervised manner) have been developed for both tasks, their training may degrade performance when the predictions on the target images are noisy. To avoid this, it is crucial to assign a low importance (confidence) weight to the noisy predictions during self-training. In this paper, we propose to utilize the divergence of two predictions to estimate the confidence of the target image for both tasks. These predictions are given from two separate networks, and their divergence helps identify the noisy predictions. To integrate our proposed confidence estimation into self-training, we propose a teacher-student framework where the two networks (teachers) provide supervision to a network (student) for self-training, and the teachers are learned from the student by knowledge distillation. Our experiments show its superiority over state-of-the-art methods in adaptation settings with different lighting, grasping objects, backgrounds, and camera viewpoints. Our method improves by 4% the multi-task score on HO3D compared to the latest adversarial adaptation method. We also validate our method on Ego4D, egocentric videos with rapid changes in imaging conditions outdoors.
REvolveR: Continuous Evolutionary Models for Robot-to-robot Policy Transfer
Feb 10, 2022
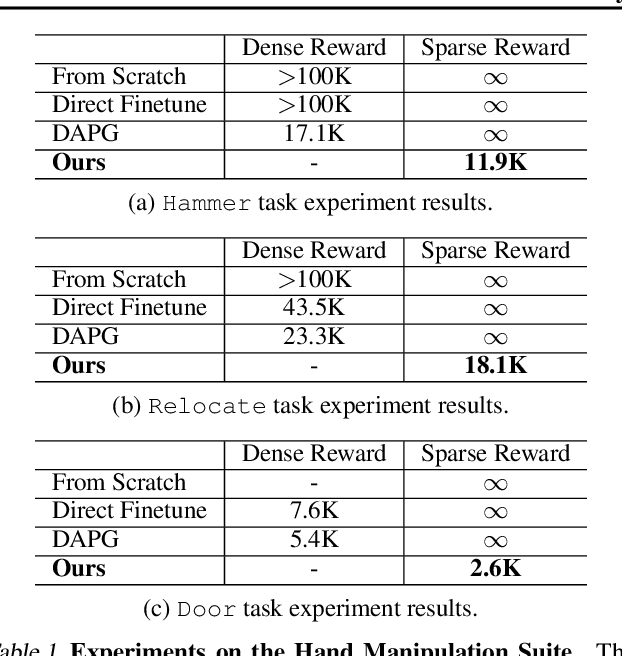
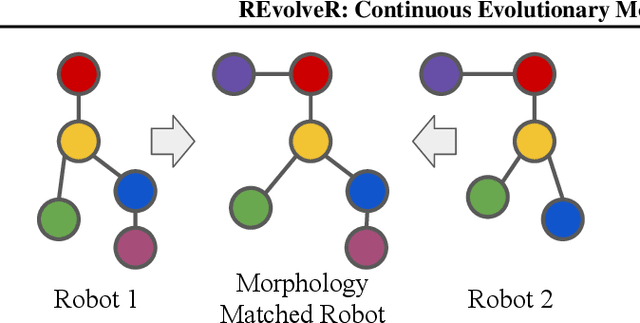

A popular paradigm in robotic learning is to train a policy from scratch for every new robot. This is not only inefficient but also often impractical for complex robots. In this work, we consider the problem of transferring a policy across two different robots with significantly different parameters such as kinematics and morphology. Existing approaches that train a new policy by matching the action or state transition distribution, including imitation learning methods, fail due to optimal action and/or state distribution being mismatched in different robots. In this paper, we propose a novel method named $REvolveR$ of using continuous evolutionary models for robotic policy transfer implemented in a physics simulator. We interpolate between the source robot and the target robot by finding a continuous evolutionary change of robot parameters. An expert policy on the source robot is transferred through training on a sequence of intermediate robots that gradually evolve into the target robot. Experiments show that the proposed continuous evolutionary model can effectively transfer the policy across robots and achieve superior sample efficiency on new robots using a physics simulator. The proposed method is especially advantageous in sparse reward settings where exploration can be significantly reduced.
Sequential Voting with Relational Box Fields for Active Object Detection
Nov 21, 2021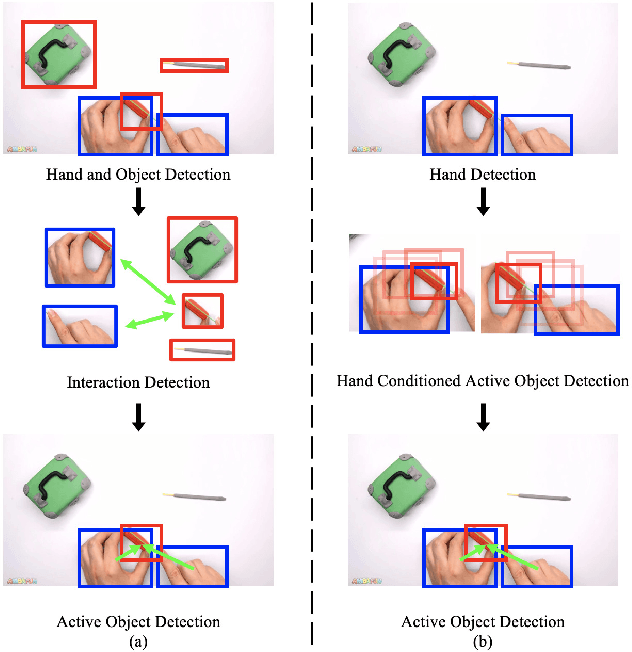

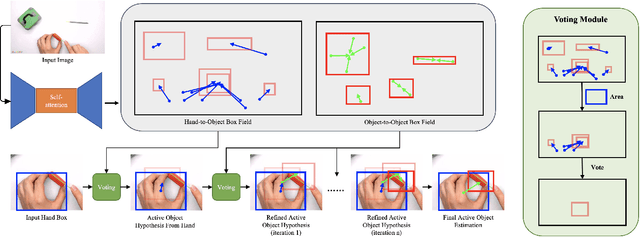

A key component of understanding hand-object interactions is the ability to identify the active object -- the object that is being manipulated by the human hand. In order to accurately localize the active object, any method must reason using information encoded by each image pixel, such as whether it belongs to the hand, the object, or the background. To leverage each pixel as evidence to determine the bounding box of the active object, we propose a pixel-wise voting function. Our pixel-wise voting function takes an initial bounding box as input and produces an improved bounding box of the active object as output. The voting function is designed so that each pixel inside of the input bounding box votes for an improved bounding box, and the box with the majority vote is selected as the output. We call the collection of bounding boxes generated inside of the voting function, the Relational Box Field, as it characterizes a field of bounding boxes defined in relationship to the current bounding box. While our voting function is able to improve the bounding box of the active object, one round of voting is typically not enough to accurately localize the active object. Therefore, we repeatedly apply the voting function to sequentially improve the location of the bounding box. However, since it is known that repeatedly applying a one-step predictor (i.e., auto-regressive processing with our voting function) can cause a data distribution shift, we mitigate this issue using reinforcement learning (RL). We adopt standard RL to learn the voting function parameters and show that it provides a meaningful improvement over a standard supervised learning approach. We perform experiments on two large-scale datasets: 100DOH and MECCANO, improving AP50 performance by 8% and 30%, respectively, over the state of the art.
V-MAO: Generative Modeling for Multi-Arm Manipulation of Articulated Objects
Nov 07, 2021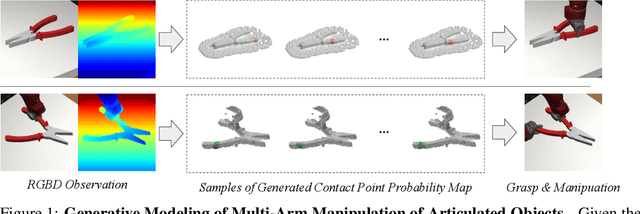
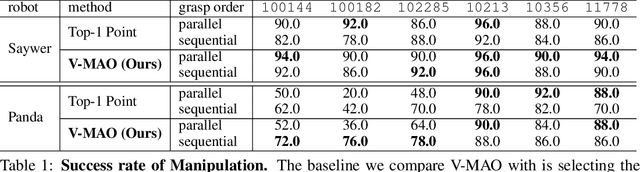
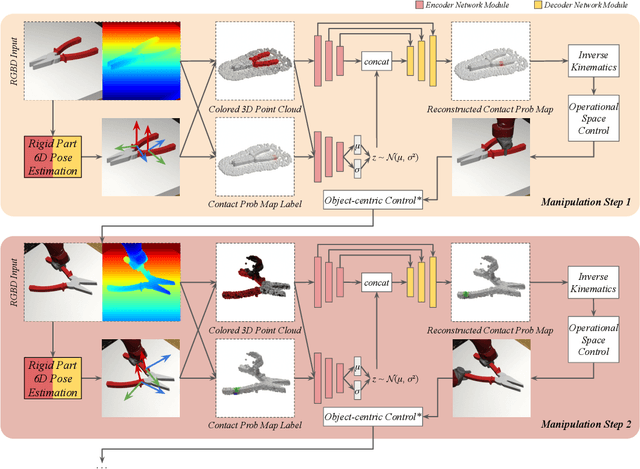

Manipulating articulated objects requires multiple robot arms in general. It is challenging to enable multiple robot arms to collaboratively complete manipulation tasks on articulated objects. In this paper, we present $\textbf{V-MAO}$, a framework for learning multi-arm manipulation of articulated objects. Our framework includes a variational generative model that learns contact point distribution over object rigid parts for each robot arm. The training signal is obtained from interaction with the simulation environment which is enabled by planning and a novel formulation of object-centric control for articulated objects. We deploy our framework in a customized MuJoCo simulation environment and demonstrate that our framework achieves a high success rate on six different objects and two different robots. We also show that generative modeling can effectively learn the contact point distribution on articulated objects.