 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025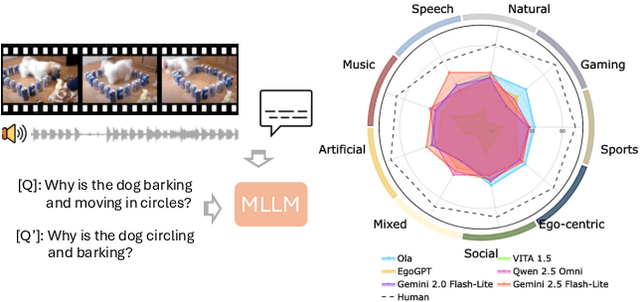
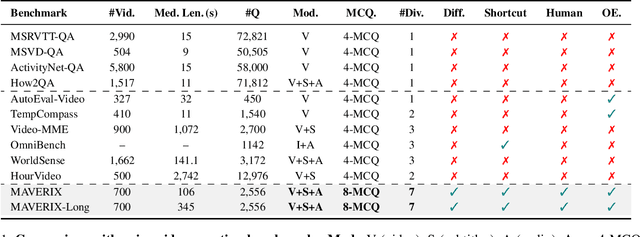
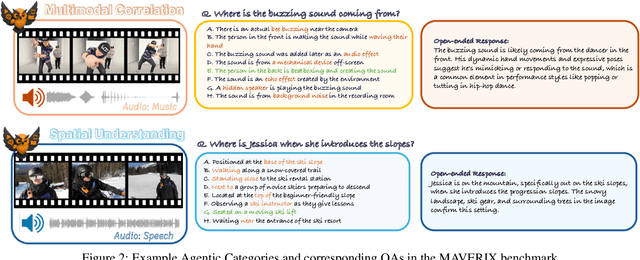
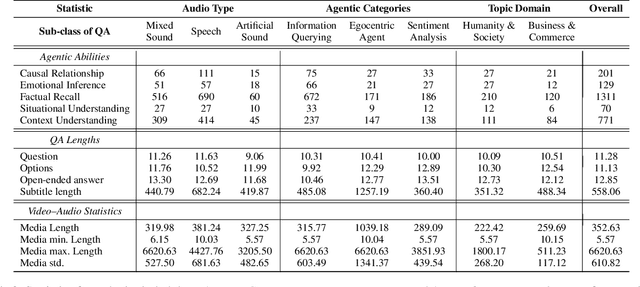
Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
CoGS: Controllable Gaussian Splatting
Dec 09, 2023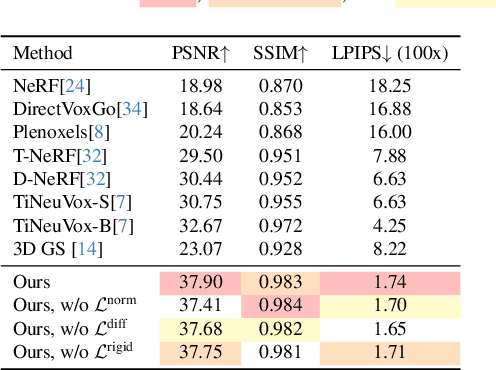
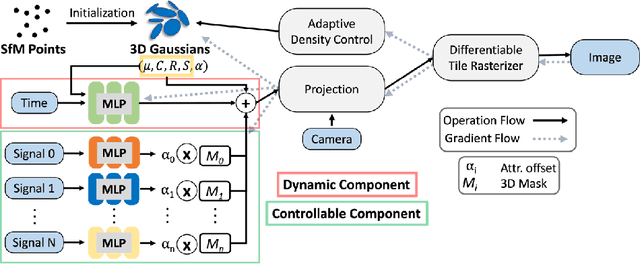
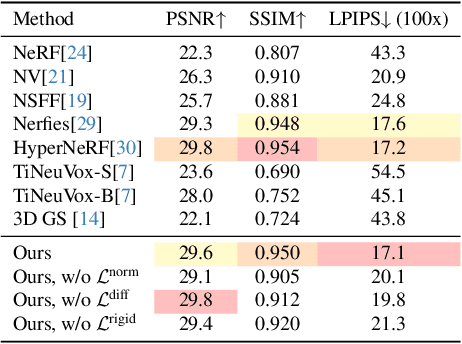
Capturing and re-animating the 3D structure of articulated objects present significant barriers. On one hand, methods requiring extensively calibrated multi-view setups are prohibitively complex and resource-intensive, limiting their practical applicability. On the other hand, while single-camera Neural Radiance Fields (NeRFs) offer a more streamlined approach, they have excessive training and rendering costs. 3D Gaussian Splatting would be a suitable alternative but for two reasons. Firstly, existing methods for 3D dynamic Gaussians require synchronized multi-view cameras, and secondly, the lack of controllability in dynamic scenarios. We present CoGS, a method for Controllable Gaussian Splatting, that enables the direct manipulation of scene elements, offering real-time control of dynamic scenes without the prerequisite of pre-computing control signals. We evaluated CoGS using both synthetic and real-world datasets that include dynamic objects that differ in degree of difficulty. In our evaluations, CoGS consistently outperformed existing dynamic and controllable neural representations in terms of visual fidelity.
Zero-Shot Video Question Answering with Procedural Programs
Dec 01, 2023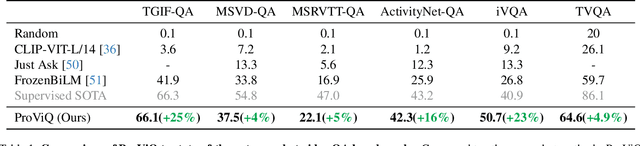
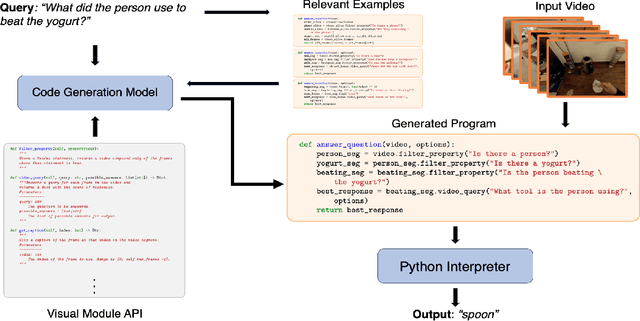
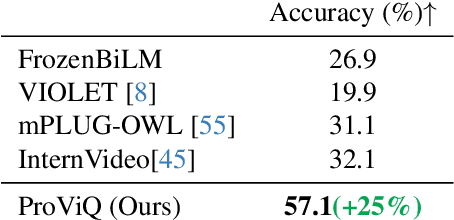
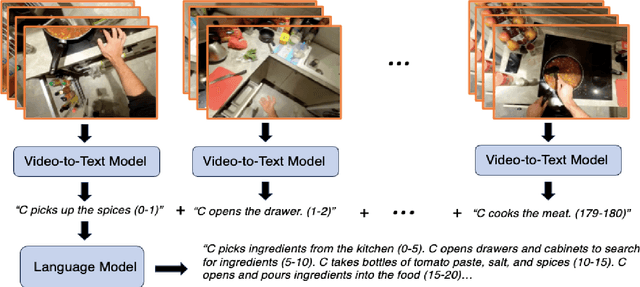
We propose to answer zero-shot questions about videos by generating short procedural programs that derive a final answer from solving a sequence of visual subtasks. We present Procedural Video Querying (ProViQ), which uses a large language model to generate such programs from an input question and an API of visual modules in the prompt, then executes them to obtain the output. Recent similar procedural approaches have proven successful for image question answering, but videos remain challenging: we provide ProViQ with modules intended for video understanding, allowing it to generalize to a wide variety of videos. This code generation framework additionally enables ProViQ to perform other video tasks in addition to question answering, such as multi-object tracking or basic video editing. ProViQ achieves state-of-the-art results on a diverse range of benchmarks, with improvements of up to 25% on short, long, open-ended, and multimodal video question-answering datasets. Our project page is at https://rccchoudhury.github.io/proviq2023.
Deep Implicit Surface Point Prediction Networks
Jun 15, 2021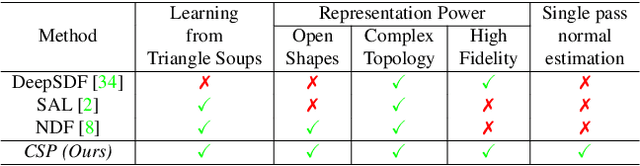
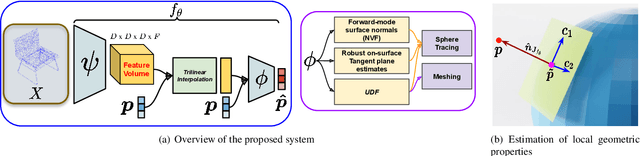
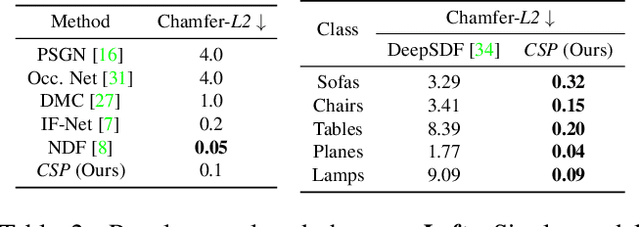
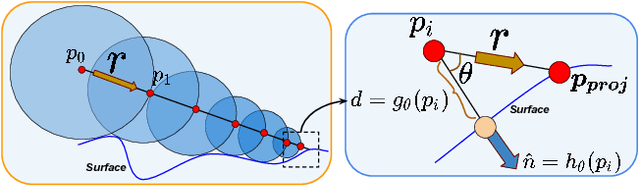
Deep neural representations of 3D shapes as implicit functions have been shown to produce high fidelity models surpassing the resolution-memory trade-off faced by the explicit representations using meshes and point clouds. However, most such approaches focus on representing closed shapes. Unsigned distance function (UDF) based approaches have been proposed recently as a promising alternative to represent both open and closed shapes. However, since the gradients of UDFs vanish on the surface, it is challenging to estimate local (differential) geometric properties like the normals and tangent planes which are needed for many downstream applications in vision and graphics. There are additional challenges in computing these properties efficiently with a low-memory footprint. This paper presents a novel approach that models such surfaces using a new class of implicit representations called the closest surface-point (CSP) representation. We show that CSP allows us to represent complex surfaces of any topology (open or closed) with high fidelity. It also allows for accurate and efficient computation of local geometric properties. We further demonstrate that it leads to efficient implementation of downstream algorithms like sphere-tracing for rendering the 3D surface as well as to create explicit mesh-based representations. Extensive experimental evaluation on the ShapeNet dataset validate the above contributions with results surpassing the state-of-the-art.
FERA 2017 - Addressing Head Pose in the Third Facial Expression Recognition and Analysis Challenge
Feb 14, 2017
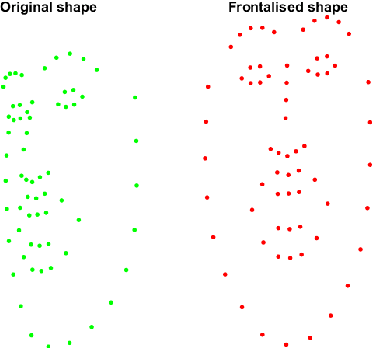
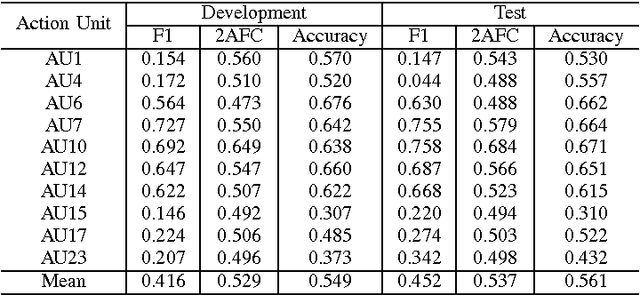
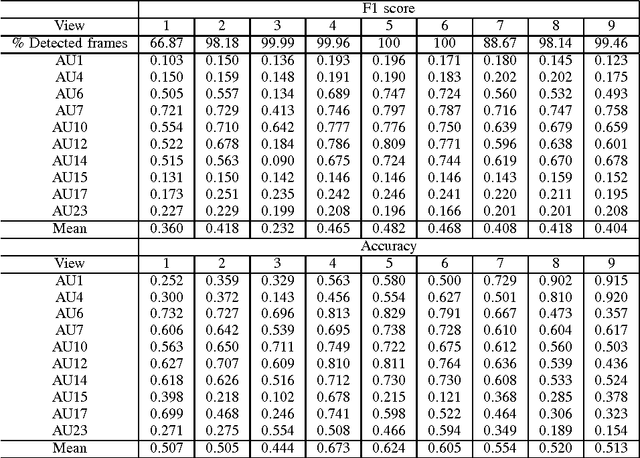
The field of Automatic Facial Expression Analysis has grown rapidly in recent years. However, despite progress in new approaches as well as benchmarking efforts, most evaluations still focus on either posed expressions, near-frontal recordings, or both. This makes it hard to tell how existing expression recognition approaches perform under conditions where faces appear in a wide range of poses (or camera views), displaying ecologically valid expressions. The main obstacle for assessing this is the availability of suitable data, and the challenge proposed here addresses this limitation. The FG 2017 Facial Expression Recognition and Analysis challenge (FERA 2017) extends FERA 2015 to the estimation of Action Units occurrence and intensity under different camera views. In this paper we present the third challenge in automatic recognition of facial expressions, to be held in conjunction with the 12th IEEE conference on Face and Gesture Recognition, May 2017, in Washington, United States. Two sub-challenges are defined: the detection of AU occurrence, and the estimation of AU intensity. In this work we outline the evaluation protocol, the data used, and the results of a baseline method for both sub-challenges.