 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025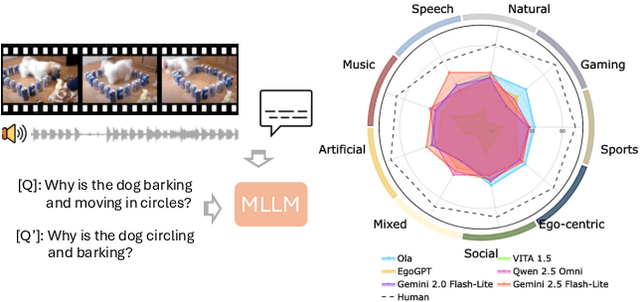
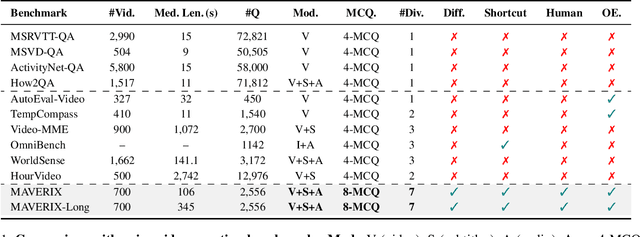
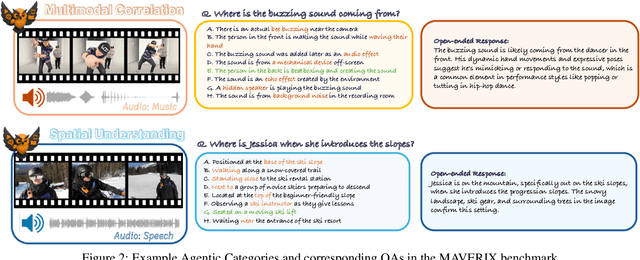
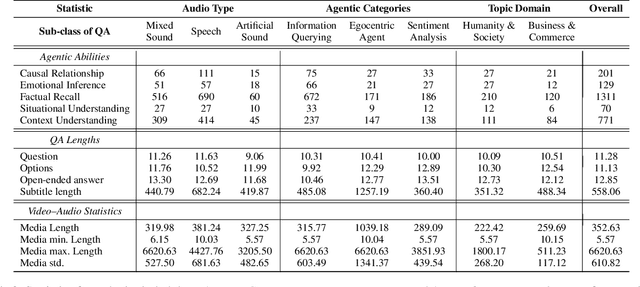
Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
Object Agnostic 3D Lifting in Space and Time
Dec 02, 2024



We present a spatio-temporal perspective on category-agnostic 3D lifting of 2D keypoints over a temporal sequence. Our approach differs from existing state-of-the-art methods that are either: (i) object agnostic, but can only operate on individual frames, or (ii) can model space-time dependencies, but are only designed to work with a single object category. Our approach is grounded in two core principles. First, when there is a lack of data about an object, general information from similar objects can be leveraged for better performance. Second, while temporal information is important, the most critical information is in immediate temporal proximity. These two principles allow us to outperform current state-of-the-art methods on per-frame and per-sequence metrics for a variety of objects. Lastly, we release a new synthetic dataset containing 3D skeletons and motion sequences of a diverse set animals. Dataset and code will be made publicly available.
3D-LFM: Lifting Foundation Model
Dec 19, 2023



The lifting of 3D structure and camera from 2D landmarks is at the cornerstone of the entire discipline of computer vision. Traditional methods have been confined to specific rigid objects, such as those in Perspective-n-Point (PnP) problems, but deep learning has expanded our capability to reconstruct a wide range of object classes (e.g. C3PDO and PAUL) with resilience to noise, occlusions, and perspective distortions. All these techniques, however, have been limited by the fundamental need to establish correspondences across the 3D training data -- significantly limiting their utility to applications where one has an abundance of "in-correspondence" 3D data. Our approach harnesses the inherent permutation equivariance of transformers to manage varying number of points per 3D data instance, withstands occlusions, and generalizes to unseen categories. We demonstrate state of the art performance across 2D-3D lifting task benchmarks. Since our approach can be trained across such a broad class of structures we refer to it simply as a 3D Lifting Foundation Model (3D-LFM) -- the first of its kind.
MBW: Multi-view Bootstrapping in the Wild
Oct 04, 2022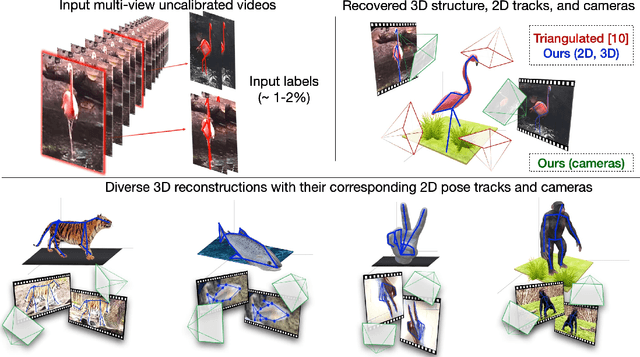
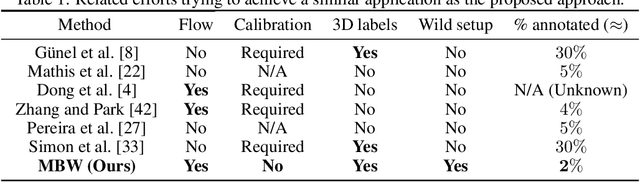
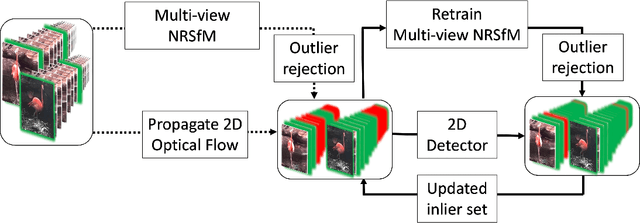
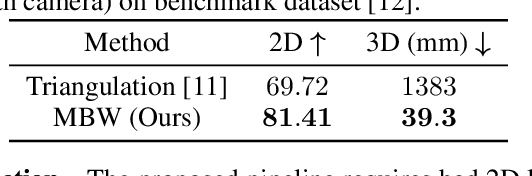
Labeling articulated objects in unconstrained settings have a wide variety of applications including entertainment, neuroscience, psychology, ethology, and many fields of medicine. Large offline labeled datasets do not exist for all but the most common articulated object categories (e.g., humans). Hand labeling these landmarks within a video sequence is a laborious task. Learned landmark detectors can help, but can be error-prone when trained from only a few examples. Multi-camera systems that train fine-grained detectors have shown significant promise in detecting such errors, allowing for self-supervised solutions that only need a small percentage of the video sequence to be hand-labeled. The approach, however, is based on calibrated cameras and rigid geometry, making it expensive, difficult to manage, and impractical in real-world scenarios. In this paper, we address these bottlenecks by combining a non-rigid 3D neural prior with deep flow to obtain high-fidelity landmark estimates from videos with only two or three uncalibrated, handheld cameras. With just a few annotations (representing 1-2% of the frames), we are able to produce 2D results comparable to state-of-the-art fully supervised methods, along with 3D reconstructions that are impossible with other existing approaches. Our Multi-view Bootstrapping in the Wild (MBW) approach demonstrates impressive results on standard human datasets, as well as tigers, cheetahs, fish, colobus monkeys, chimpanzees, and flamingos from videos captured casually in a zoo. We release the codebase for MBW as well as this challenging zoo dataset consisting image frames of tail-end distribution categories with their corresponding 2D, 3D labels generated from minimal human intervention.
High Fidelity 3D Reconstructions with Limited Physical Views
Oct 22, 2021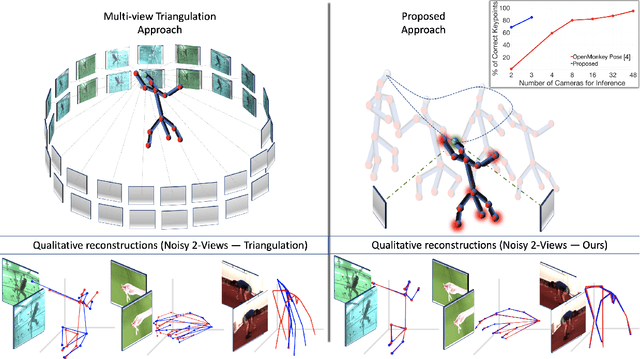

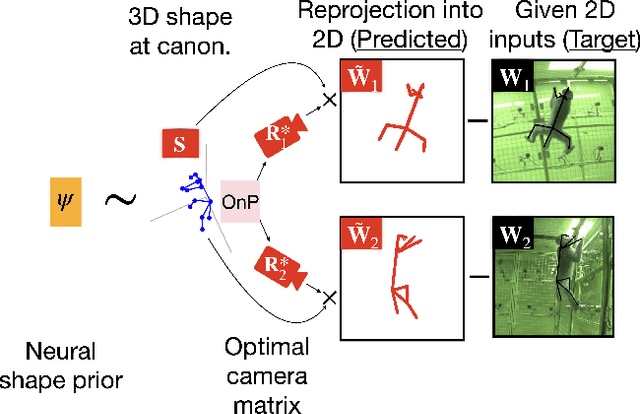

Multi-view triangulation is the gold standard for 3D reconstruction from 2D correspondences given known calibration and sufficient views. However in practice, expensive multi-view setups -- involving tens sometimes hundreds of cameras -- are required in order to obtain the high fidelity 3D reconstructions necessary for many modern applications. In this paper we present a novel approach that leverages recent advances in 2D-3D lifting using neural shape priors while also enforcing multi-view equivariance. We show how our method can achieve comparable fidelity to expensive calibrated multi-view rigs using a limited (2-3) number of uncalibrated camera views.
Fast and Agile Vision-Based Flight with Teleoperation and Collision Avoidance on a Multirotor
May 31, 2019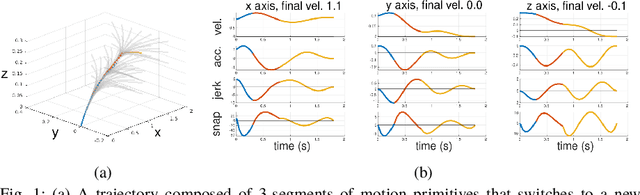

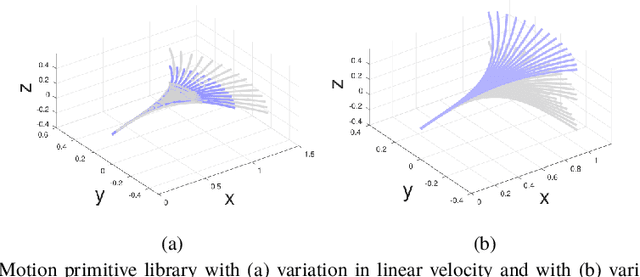
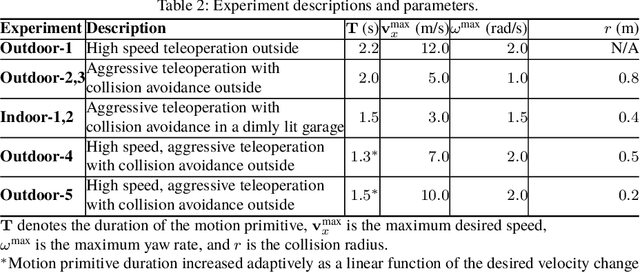
We present a multirotor architecture capable of aggressive autonomous flight and collision-free teleoperation in unstructured, GPS-denied environments. The proposed system enables aggressive and safe autonomous flight around clutter by integrating recent advancements in visual-inertial state estimation and teleoperation. Our teleoperation framework maps user inputs onto smooth and dynamically feasible motion primitives. Collision-free trajectories are ensured by querying a locally consistent map that is incrementally constructed from forward-facing depth observations. Our system enables a non-expert operator to safely navigate a multirotor around obstacles at speeds of 10 m/s. We achieve autonomous flights at speeds exceeding 12 m/s and accelerations exceeding 12 m/s^2 in a series of outdoor field experiments that validate our approach.