 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025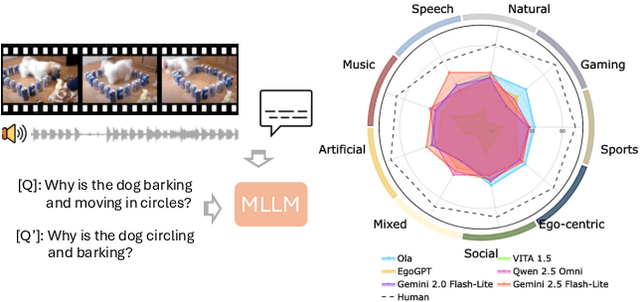
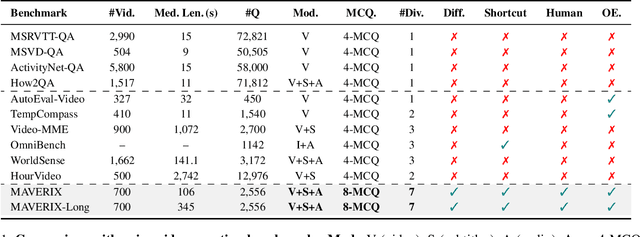
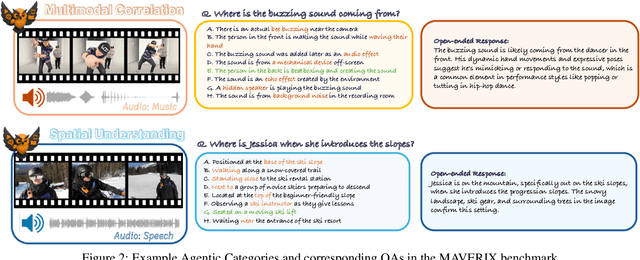
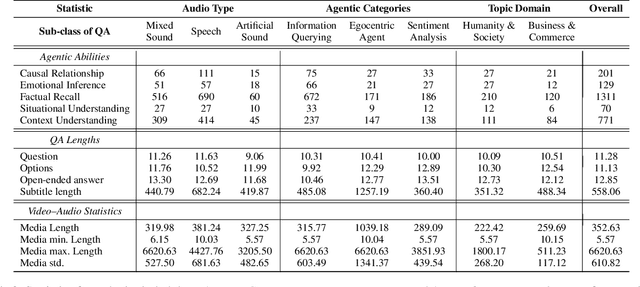
Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
Transformers Get Stable: An End-to-End Signal Propagation Theory for Language Models
Mar 14, 2024In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the forward and backward signal through the transformer model. Our framework can be used to understand and mitigate vanishing/exploding gradients, rank collapse, and instability associated with high attention scores. We also propose DeepScaleLM, an initialization and scaling scheme that conserves unit output/gradient moments throughout the model, enabling the training of very deep models with 100s of layers. We find that transformer models could be much deeper - our deep models with fewer parameters outperform shallow models in Language Modeling, Speech Translation, and Image Classification, across Encoder-only, Decoder-only and Encoder-Decoder variants, for both Pre-LN and Post-LN transformers, for multiple datasets and model sizes. These improvements also translate into improved performance on downstream Question Answering tasks and improved robustness for image classification.
Data-driven grapheme-to-phoneme representations for a lexicon-free text-to-speech
Jan 19, 2024Grapheme-to-Phoneme (G2P) is an essential first step in any modern, high-quality Text-to-Speech (TTS) system. Most of the current G2P systems rely on carefully hand-crafted lexicons developed by experts. This poses a two-fold problem. Firstly, the lexicons are generated using a fixed phoneme set, usually, ARPABET or IPA, which might not be the most optimal way to represent phonemes for all languages. Secondly, the man-hours required to produce such an expert lexicon are very high. In this paper, we eliminate both of these issues by using recent advances in self-supervised learning to obtain data-driven phoneme representations instead of fixed representations. We compare our lexicon-free approach against strong baselines that utilize a well-crafted lexicon. Furthermore, we show that our data-driven lexicon-free method performs as good or even marginally better than the conventional rule-based or lexicon-based neural G2Ps in terms of Mean Opinion Score (MOS) while using no prior language lexicon or phoneme set, i.e. no linguistic expertise.
SR-GCL: Session-Based Recommendation with Global Context Enhanced Augmentation in Contrastive Learning
Sep 23, 2022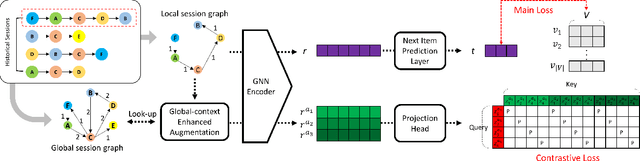
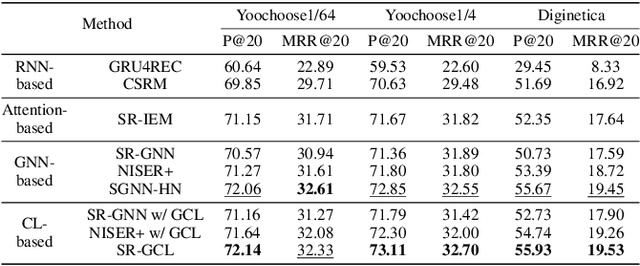
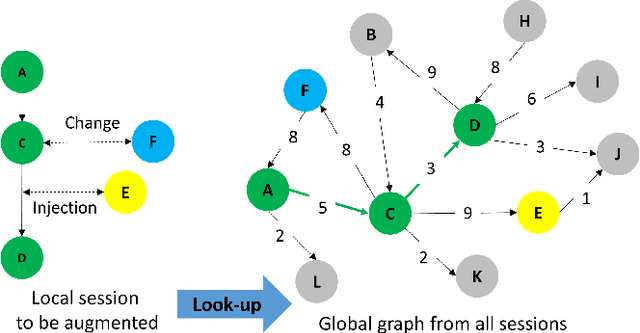
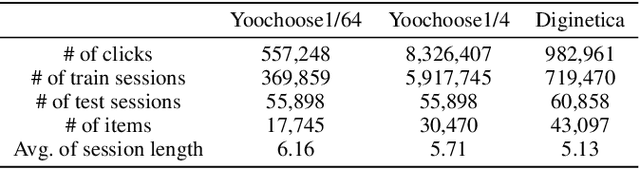
Session-based recommendations aim to predict the next behavior of users based on ongoing sessions. The previous works have been modeling the session as a variable-length of a sequence of items and learning the representation of both individual items and the aggregated session. Recent research has applied graph neural networks with an attention mechanism to capture complicated item transitions and dependencies by modeling the sessions into graph-structured data. However, they still face fundamental challenges in terms of data and learning methodology such as sparse supervision signals and noisy interactions in sessions, leading to sub-optimal performance. In this paper, we propose SR-GCL, a novel contrastive learning framework for a session-based recommendation. As a crucial component of contrastive learning, we propose two global context enhanced data augmentation methods while maintaining the semantics of the original session. The extensive experiment results on two real-world E-commerce datasets demonstrate the superiority of SR-GCL as compared to other state-of-the-art methods.
STING: Self-attention based Time-series Imputation Networks using GAN
Sep 22, 2022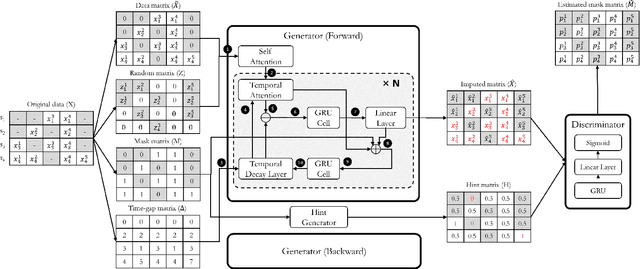
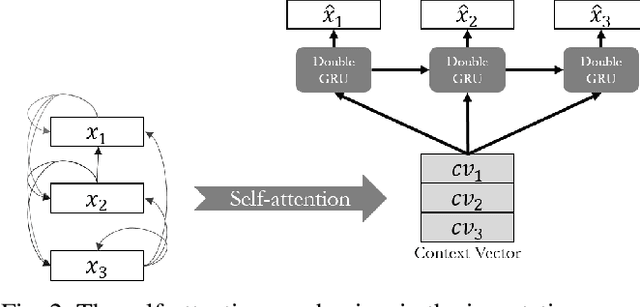
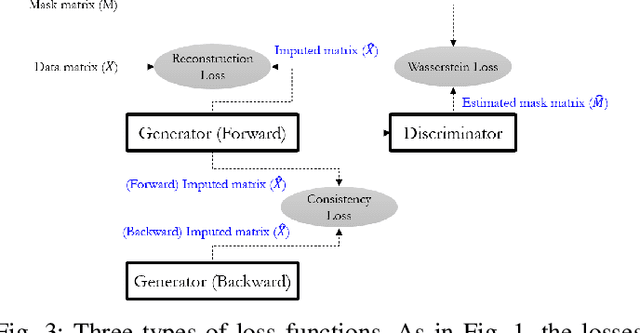
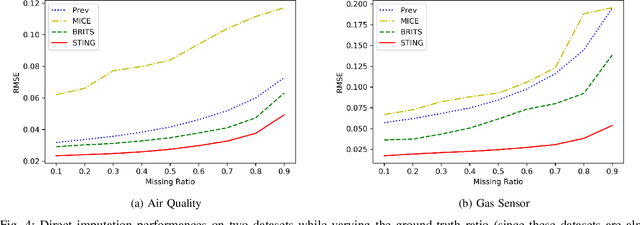
Time series data are ubiquitous in real-world applications. However, one of the most common problems is that the time series data could have missing values by the inherent nature of the data collection process. So imputing missing values from multivariate (correlated) time series data is imperative to improve a prediction performance while making an accurate data-driven decision. Conventional works for imputation simply delete missing values or fill them based on mean/zero. Although recent works based on deep neural networks have shown remarkable results, they still have a limitation to capture the complex generation process of the multivariate time series. In this paper, we propose a novel imputation method for multivariate time series data, called STING (Self-attention based Time-series Imputation Networks using GAN). We take advantage of generative adversarial networks and bidirectional recurrent neural networks to learn latent representations of the time series. In addition, we introduce a novel attention mechanism to capture the weighted correlations of the whole sequence and avoid potential bias brought by unrelated ones. Experimental results on three real-world datasets demonstrate that STING outperforms the existing state-of-the-art methods in terms of imputation accuracy as well as downstream tasks with the imputed values therein.
PAC Mode Estimation using PPR Martingale Confidence Sequences
Sep 10, 2021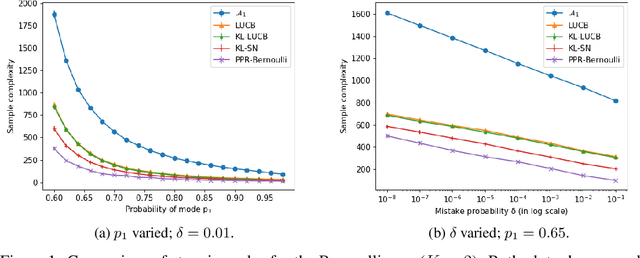
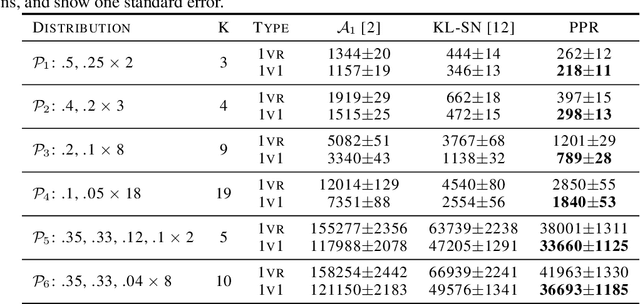
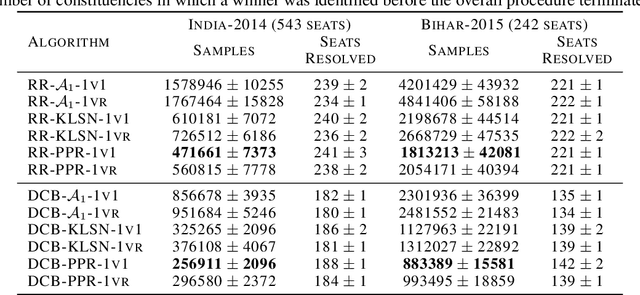
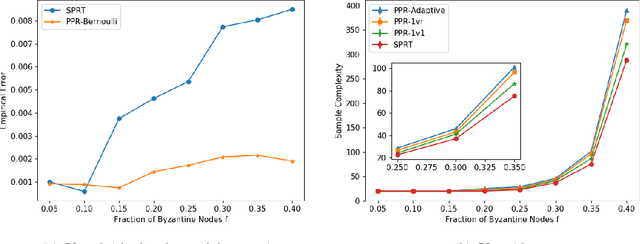
We consider the problem of correctly identifying the mode of a discrete distribution $\mathcal{P}$ with sufficiently high probability by observing a sequence of i.i.d. samples drawn according to $\mathcal{P}$. This problem reduces to the estimation of a single parameter when $\mathcal{P}$ has a support set of size $K = 2$. Noting the efficiency of prior-posterior-ratio (PPR) martingale confidence sequences for handling this special case, we propose a generalisation to mode estimation, in which $\mathcal{P}$ may take $K \geq 2$ values. We observe that the "one-versus-one" principle yields a more efficient generalisation than the "one-versus-rest" alternative. Our resulting stopping rule, denoted PPR-ME, is optimal in its sample complexity up to a logarithmic factor. Moreover, PPR-ME empirically outperforms several other competing approaches for mode estimation. We demonstrate the gains offered by PPR-ME in two practical applications: (1) sample-based forecasting of the winner in indirect election systems, and (2) efficient verification of smart contracts in permissionless blockchains.
Meta-Learning for Effective Multi-task and Multilingual Modelling
Jan 27, 2021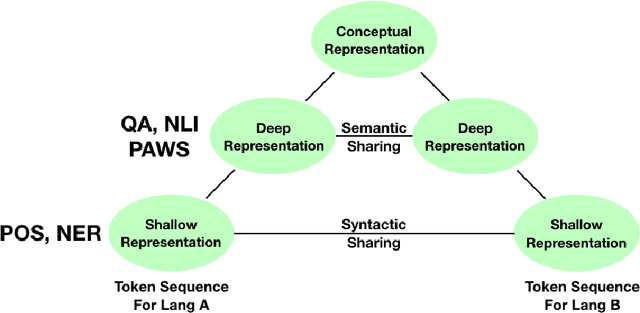
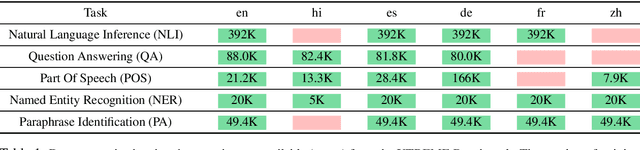
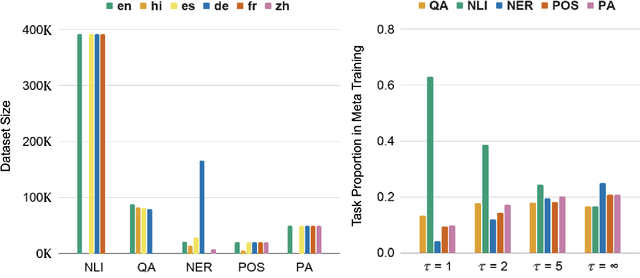
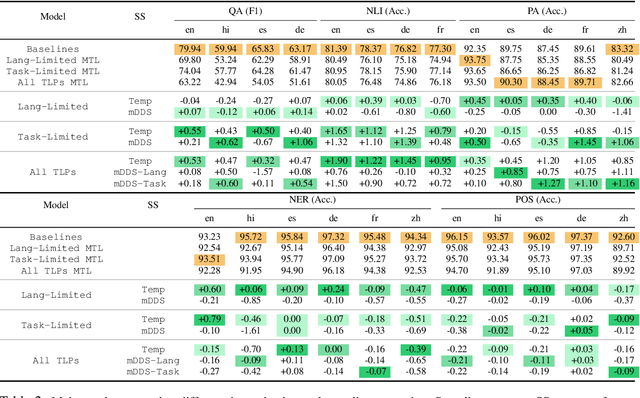
Natural language processing (NLP) tasks (e.g. question-answering in English) benefit from knowledge of other tasks (e.g. named entity recognition in English) and knowledge of other languages (e.g. question-answering in Spanish). Such shared representations are typically learned in isolation, either across tasks or across languages. In this work, we propose a meta-learning approach to learn the interactions between both tasks and languages. We also investigate the role of different sampling strategies used during meta-learning. We present experiments on five different tasks and six different languages from the XTREME multilingual benchmark dataset. Our meta-learned model clearly improves in performance compared to competitive baseline models that also include multi-task baselines. We also present zero-shot evaluations on unseen target languages to demonstrate the utility of our proposed model.