 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Get Stable: An End-to-End Signal Propagation Theory for Language Models
Mar 14, 2024In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the forward and backward signal through the transformer model. Our framework can be used to understand and mitigate vanishing/exploding gradients, rank collapse, and instability associated with high attention scores. We also propose DeepScaleLM, an initialization and scaling scheme that conserves unit output/gradient moments throughout the model, enabling the training of very deep models with 100s of layers. We find that transformer models could be much deeper - our deep models with fewer parameters outperform shallow models in Language Modeling, Speech Translation, and Image Classification, across Encoder-only, Decoder-only and Encoder-Decoder variants, for both Pre-LN and Post-LN transformers, for multiple datasets and model sizes. These improvements also translate into improved performance on downstream Question Answering tasks and improved robustness for image classification.
FiE: Building a Global Probability Space by Leveraging Early Fusion in Encoder for Open-Domain Question Answering
Nov 18, 2022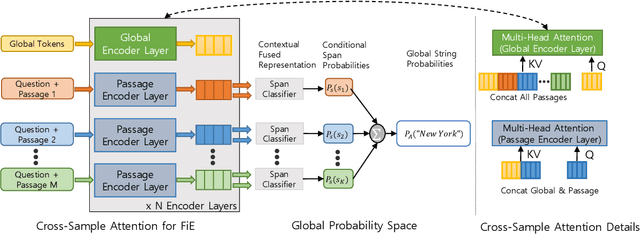



Generative models have recently started to outperform extractive models in Open Domain Question Answering, largely by leveraging their decoder to attend over multiple encoded passages and combining their information. However, generative models tend to be larger than extractive models due to the need for a decoder, run slower during inference due to auto-regressive decoder beam search, and their generated output often suffers from hallucinations. We propose to extend transformer encoders with the ability to fuse information from multiple passages, using global representation to provide cross-sample attention over all tokens across samples. Furthermore, we propose an alternative answer span probability calculation to better aggregate answer scores in the global space of all samples. Using our proposed method, we outperform the current state-of-the-art method by $2.5$ Exact Match score on the Natural Question dataset while using only $25\%$ of parameters and $35\%$ of the latency during inference, and $4.4$ Exact Match on WebQuestions dataset. When coupled with synthetic data augmentation, we outperform larger models on the TriviaQA dataset as well. The latency and parameter savings of our method make it particularly attractive for open-domain question answering, as these models are often compute-intensive.
Decision Attentive Regularization to Improve Simultaneous Speech Translation Systems
Oct 13, 2021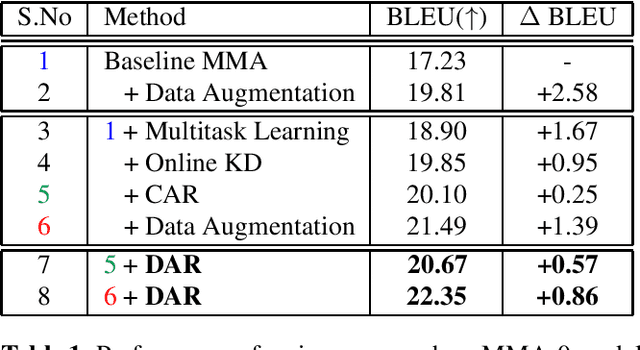
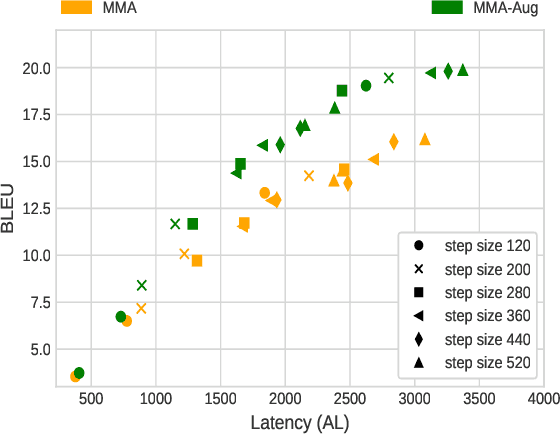
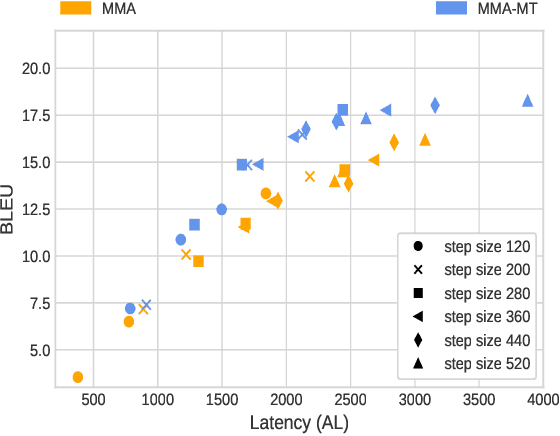
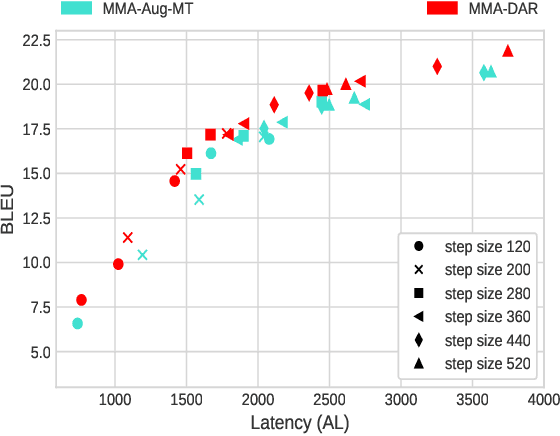
Simultaneous Speech-to-text Translation (SimulST) systems translate source speech in tandem with the speaker using partial input. Recent works have tried to leverage the text translation task to improve the performance of Speech Translation (ST) in the offline domain. Motivated by these improvements, we propose to add Decision Attentive Regularization (DAR) to Monotonic Multihead Attention (MMA) based SimulST systems. DAR improves the read/write decisions for speech using the Simultaneous text Translation (SimulMT) task. We also extend several techniques from the offline domain to the SimulST task. Our proposed system achieves significant performance improvements for the MuST-C English-German (EnDe) SimulST task, where we provide an average BLUE score improvement of around 4.57 points or 34.17% across different latencies. Further, the latency-quality tradeoffs establish that the proposed model achieves better results compared to the baseline.
Infusing Future Information into Monotonic Attention Through Language Models
Sep 07, 2021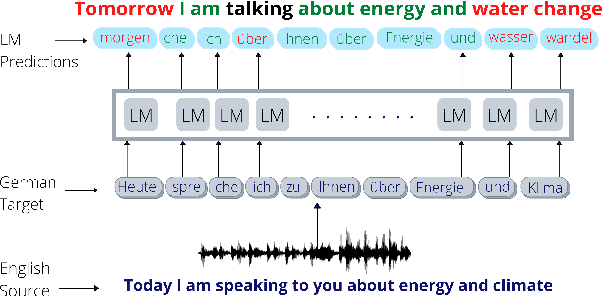

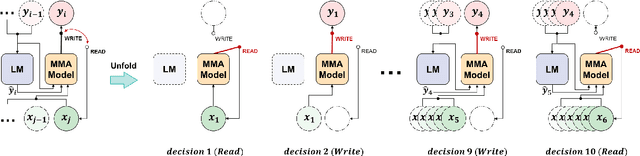
Simultaneous neural machine translation(SNMT) models start emitting the target sequence before they have processed the source sequence. The recent adaptive policies for SNMT use monotonic attention to perform read/write decisions based on the partial source and target sequences. The lack of sufficient information might cause the monotonic attention to take poor read/write decisions, which in turn negatively affects the performance of the SNMT model. On the other hand, human translators make better read/write decisions since they can anticipate the immediate future words using linguistic information and domain knowledge.Motivated by human translators, in this work, we propose a framework to aid monotonic attention with an external language model to improve its decisions.We conduct experiments on the MuST-C English-German and English-French speech-to-text translation tasks to show the effectiveness of the proposed framework.The proposed SNMT method improves the quality-latency trade-off over the state-of-the-art monotonic multihead attention.
Faster Re-translation Using Non-Autoregressive Model For Simultaneous Neural Machine Translation
Dec 29, 2020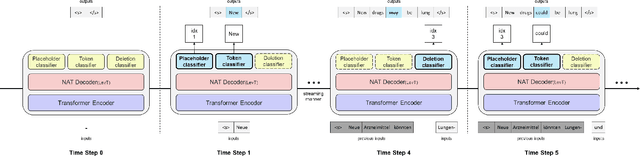

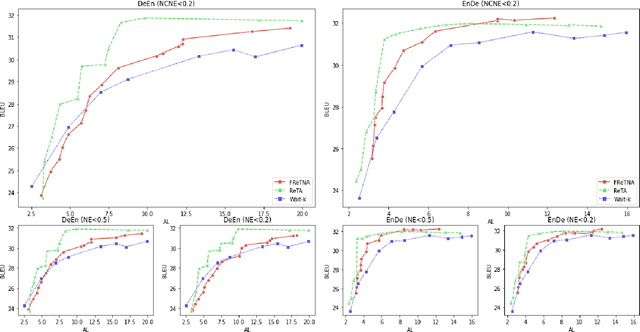
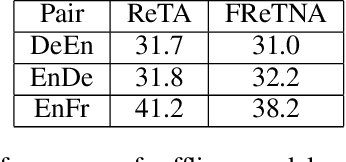
Recently, simultaneous translation has gathered a lot of attention since it enables compelling applications such as subtitle translation for a live event or real-time video-call translation. Some of these translation applications allow editing of partial translation giving rise to re-translation approaches. The current re-translation approaches are based on autoregressive sequence generation models (ReTA), which generate tar-get tokens in the (partial) translation sequentially. The multiple re-translations with sequential generation inReTAmodelslead to an increased inference time gap between the incoming source input and the corresponding target output as the source input grows. Besides, due to the large number of inference operations involved, the ReTA models are not favorable for resource-constrained devices. In this work, we propose a faster re-translation system based on a non-autoregressive sequence generation model (FReTNA) to overcome the aforementioned limitations. We evaluate the proposed model on multiple translation tasks and our model reduces the inference times by several orders and achieves a competitive BLEUscore compared to the ReTA and streaming (Wait-k) models.The proposed model reduces the average computation time by a factor of 20 when compared to the ReTA model by incurring a small drop in the translation quality. It also outperforms the streaming-based Wait-k model both in terms of computation time (1.5 times lower) and translation quality.