 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Get Stable: An End-to-End Signal Propagation Theory for Language Models
Mar 14, 2024In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the forward and backward signal through the transformer model. Our framework can be used to understand and mitigate vanishing/exploding gradients, rank collapse, and instability associated with high attention scores. We also propose DeepScaleLM, an initialization and scaling scheme that conserves unit output/gradient moments throughout the model, enabling the training of very deep models with 100s of layers. We find that transformer models could be much deeper - our deep models with fewer parameters outperform shallow models in Language Modeling, Speech Translation, and Image Classification, across Encoder-only, Decoder-only and Encoder-Decoder variants, for both Pre-LN and Post-LN transformers, for multiple datasets and model sizes. These improvements also translate into improved performance on downstream Question Answering tasks and improved robustness for image classification.
Span-Selective Linear Attention Transformers for Effective and Robust Schema-Guided Dialogue State Tracking
Jun 15, 2023In schema-guided dialogue state tracking models estimate the current state of a conversation using natural language descriptions of the service schema for generalization to unseen services. Prior generative approaches which decode slot values sequentially do not generalize well to variations in schema, while discriminative approaches separately encode history and schema and fail to account for inter-slot and intent-slot dependencies. We introduce SPLAT, a novel architecture which achieves better generalization and efficiency than prior approaches by constraining outputs to a limited prediction space. At the same time, our model allows for rich attention among descriptions and history while keeping computation costs constrained by incorporating linear-time attention. We demonstrate the effectiveness of our model on the Schema-Guided Dialogue (SGD) and MultiWOZ datasets. Our approach significantly improves upon existing models achieving 85.3 JGA on the SGD dataset. Further, we show increased robustness on the SGD-X benchmark: our model outperforms the more than 30$\times$ larger D3ST-XXL model by 5.0 points.
FiE: Building a Global Probability Space by Leveraging Early Fusion in Encoder for Open-Domain Question Answering
Nov 18, 2022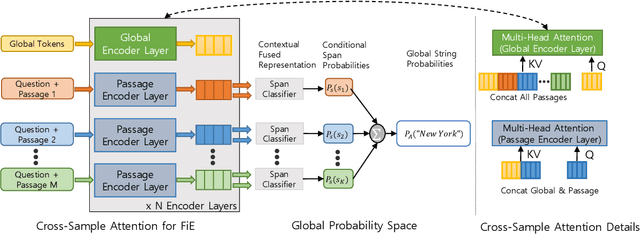



Generative models have recently started to outperform extractive models in Open Domain Question Answering, largely by leveraging their decoder to attend over multiple encoded passages and combining their information. However, generative models tend to be larger than extractive models due to the need for a decoder, run slower during inference due to auto-regressive decoder beam search, and their generated output often suffers from hallucinations. We propose to extend transformer encoders with the ability to fuse information from multiple passages, using global representation to provide cross-sample attention over all tokens across samples. Furthermore, we propose an alternative answer span probability calculation to better aggregate answer scores in the global space of all samples. Using our proposed method, we outperform the current state-of-the-art method by $2.5$ Exact Match score on the Natural Question dataset while using only $25\%$ of parameters and $35\%$ of the latency during inference, and $4.4$ Exact Match on WebQuestions dataset. When coupled with synthetic data augmentation, we outperform larger models on the TriviaQA dataset as well. The latency and parameter savings of our method make it particularly attractive for open-domain question answering, as these models are often compute-intensive.
You Only Need One Model for Open-domain Question Answering
Dec 14, 2021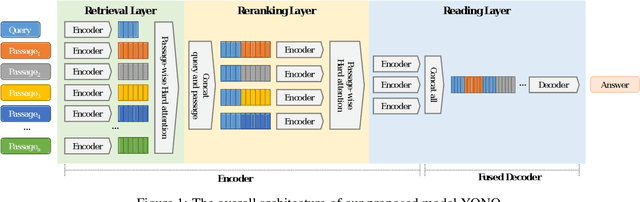
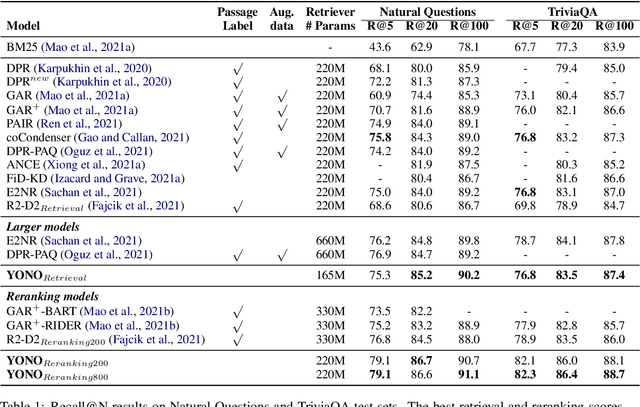
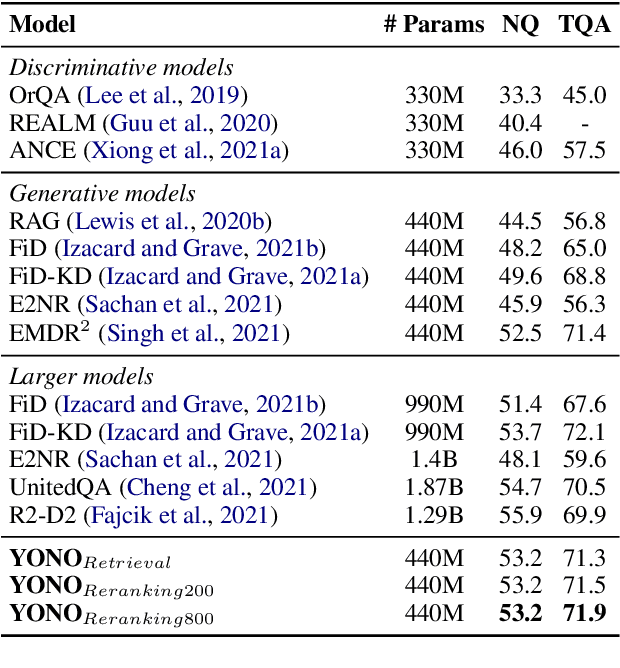
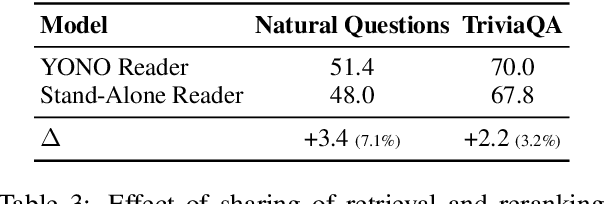
Recent works for Open-domain Question Answering refer to an external knowledge base using a retriever model, optionally rerank the passages with a separate reranker model and generate an answer using an another reader model. Despite performing related tasks, the models have separate parameters and are weakly-coupled during training. In this work, we propose casting the retriever and the reranker as hard-attention mechanisms applied sequentially within the transformer architecture and feeding the resulting computed representations to the reader. In this singular model architecture the hidden representations are progressively refined from the retriever to the reranker to the reader, which is more efficient use of model capacity and also leads to better gradient flow when we train it in an end-to-end manner. We also propose a pre-training methodology to effectively train this architecture. We evaluate our model on Natural Questions and TriviaQA open datasets and for a fixed parameter budget, our model outperforms the previous state-of-the-art model by 1.0 and 0.7 exact match scores.
SLM: Learning a Discourse Language Representation with Sentence Unshuffling
Oct 30, 2020



We introduce Sentence-level Language Modeling, a new pre-training objective for learning a discourse language representation in a fully self-supervised manner. Recent pre-training methods in NLP focus on learning either bottom or top-level language representations: contextualized word representations derived from language model objectives at one extreme and a whole sequence representation learned by order classification of two given textual segments at the other. However, these models are not directly encouraged to capture representations of intermediate-size structures that exist in natural languages such as sentences and the relationships among them. To that end, we propose a new approach to encourage learning of a contextualized sentence-level representation by shuffling the sequence of input sentences and training a hierarchical transformer model to reconstruct the original ordering. Through experiments on downstream tasks such as GLUE, SQuAD, and DiscoEval, we show that this feature of our model improves the performance of the original BERT by large margins.
Retrieve, Rerank, Read, then Iterate: Answering Open-Domain Questions of Arbitrary Complexity from Text
Oct 23, 2020

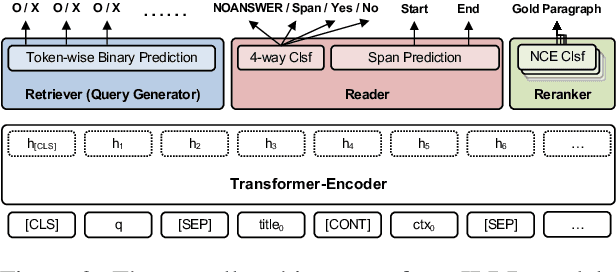

Current approaches to open-domain question answering often make crucial assumptions that prevent them from generalizing to real-world settings, including the access to parameterized retrieval systems well-tuned for the task, access to structured metadata like knowledge bases and web links, or a priori knowledge of the complexity of questions to be answered (e.g., single-hop or multi-hop). To address these limitations, we propose a unified system to answer open-domain questions of arbitrary complexity directly from text that works with off-the-shelf retrieval systems on arbitrary text collections. We employ a single multi-task model to perform all the necessary subtasks---retrieving supporting facts, reranking them, and predicting the answer from all retrieved documents---in an iterative fashion. To emulate a more realistic setting, we also constructed a new unified benchmark by collecting about 200 multi-hop questions that require three Wikipedia pages to answer, and combining them with existing datasets. We show that our model not only outperforms state-of-the-art systems on several existing benchmarks that exclusively feature single-hop or multi-hop open-domain questions, but also achieves strong performance on the new benchmark.
Syllable-level Neural Language Model for Agglutinative Language
Aug 18, 2017
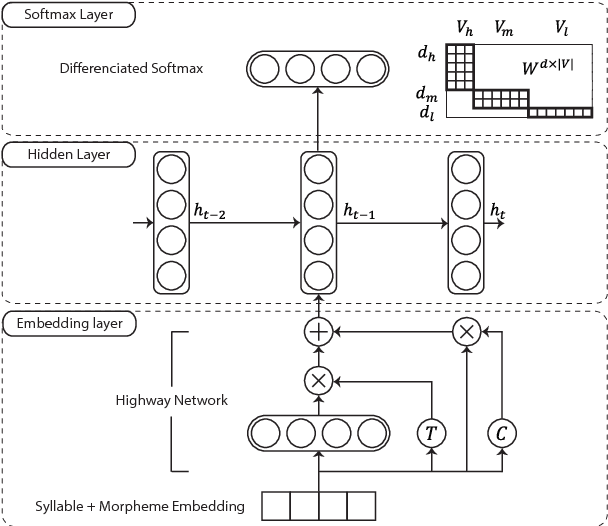
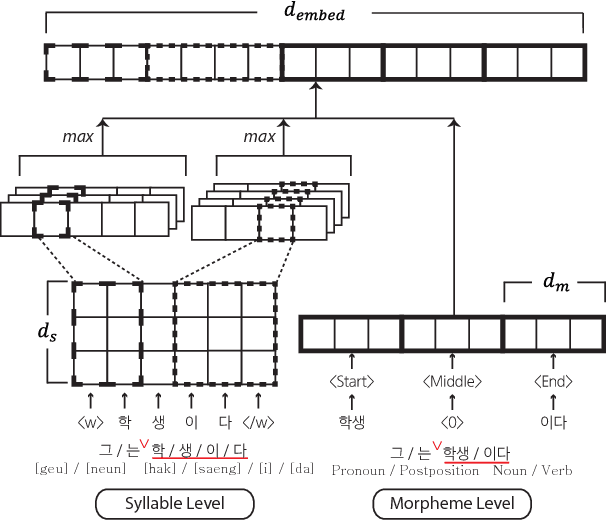
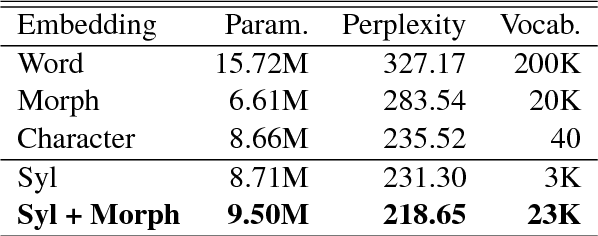
Language models for agglutinative languages have always been hindered in past due to myriad of agglutinations possible to any given word through various affixes. We propose a method to diminish the problem of out-of-vocabulary words by introducing an embedding derived from syllables and morphemes which leverages the agglutinative property. Our model outperforms character-level embedding in perplexity by 16.87 with 9.50M parameters. Proposed method achieves state of the art performance over existing input prediction methods in terms of Key Stroke Saving and has been commercialized.
An Embedded Deep Learning based Word Prediction
Jul 06, 2017


Recent developments in deep learning with application to language modeling have led to success in tasks of text processing, summarizing and machine translation. However, deploying huge language models for mobile device such as on-device keyboards poses computation as a bottle-neck due to their puny computation capacities. In this work we propose an embedded deep learning based word prediction method that optimizes run-time memory and also provides a real time prediction environment. Our model size is 7.40MB and has average prediction time of 6.47 ms. We improve over the existing methods for word prediction in terms of key stroke savings and word prediction rate.