 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Propaganda Detection in News Articles
Aug 29, 2021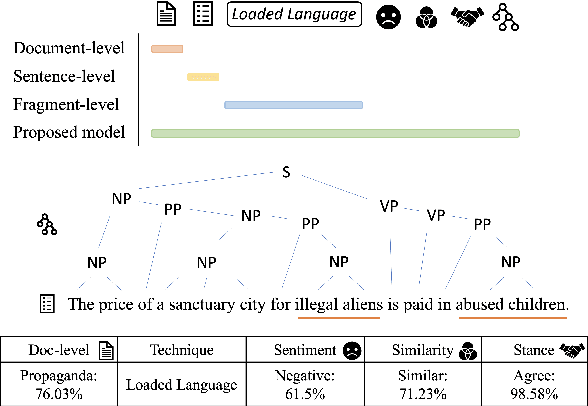

Online users today are exposed to misleading and propagandistic news articles and media posts on a daily basis. To counter thus, a number of approaches have been designed aiming to achieve a healthier and safer online news and media consumption. Automatic systems are able to support humans in detecting such content; yet, a major impediment to their broad adoption is that besides being accurate, the decisions of such systems need also to be interpretable in order to be trusted and widely adopted by users. Since misleading and propagandistic content influences readers through the use of a number of deception techniques, we propose to detect and to show the use of such techniques as a way to offer interpretability. In particular, we define qualitatively descriptive features and we analyze their suitability for detecting deception techniques. We further show that our interpretable features can be easily combined with pre-trained language models, yielding state-of-the-art results.
* propaganda, propaganda techniques, disinformation, misinformation, fake news, explainability, interpretability
Cooperative Learning of Zero-Shot Machine Reading Comprehension
Mar 22, 2021
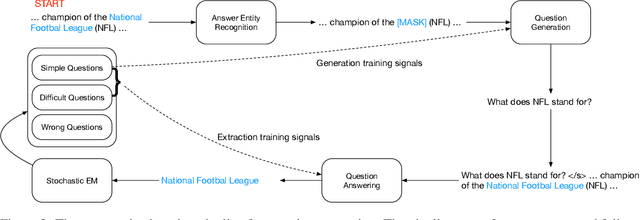
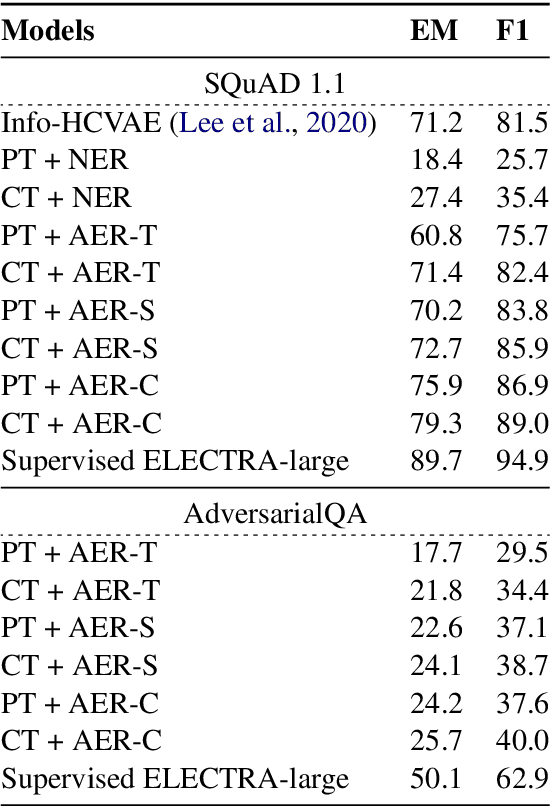
Pretrained language models have significantly improved the performance of down-stream language understanding tasks, including extractive question answering, by providing high-quality contextualized word embeddings. However, learning question answering models still need large-scaled data annotation in specific domains. In this work, we propose a cooperative, self-play learning framework, REGEX, for question generation and answering. REGEX is built upon a masked answer extraction task with an interactive learning environment containing an answer entity REcognizer, a question Generator, and an answer EXtractor. Given a passage with a masked entity, the generator generates a question around the entity, and the extractor is trained to extract the masked entity with the generated question and raw texts. The framework allows the training of question generation and answering models on any text corpora without annotation. We further leverage a reinforcement learning technique to reward generating high-quality questions and to improve the answer extraction model's performance. Experiment results show that REGEX outperforms the state-of-the-art (SOTA) pretrained language models and zero-shot approaches on standard question-answering benchmarks, and yields the new SOTA performance under the zero-shot setting.
Constructing a Knowledge Graph from Unstructured Documents without External Alignment
Aug 20, 2020
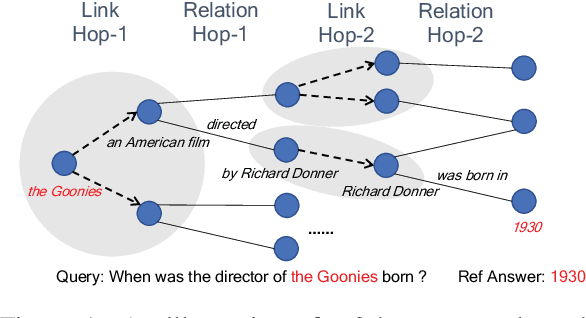
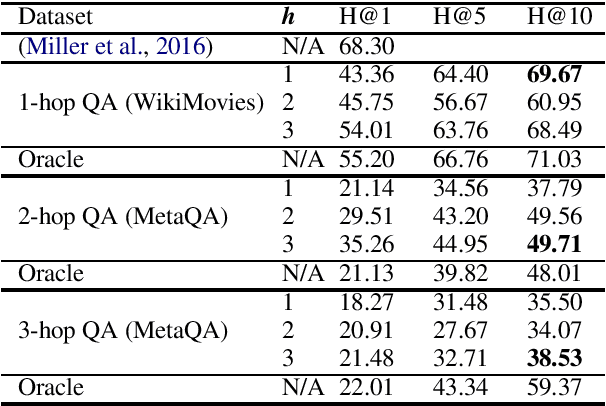

Knowledge graphs (KGs) are relevant to many NLP tasks, but building a reliable domain-specific KG is time-consuming and expensive. A number of methods for constructing KGs with minimized human intervention have been proposed, but still require a process to align into the human-annotated knowledge base. To overcome this issue, we propose a novel method to automatically construct a KG from unstructured documents that does not require external alignment and explore its use to extract desired information. To summarize our approach, we first extract knowledge tuples in their surface form from unstructured documents, encode them using a pre-trained language model, and link the surface-entities via the encoding to form the graph structure. We perform experiments with benchmark datasets such as WikiMovies and MetaQA. The experimental results show that our method can successfully create and search a KG with 18K documents and achieve 69.7% hits@10 (close to an oracle model) on a query retrieval task.
A Survey on Computational Propaganda Detection
Jul 15, 2020

Propaganda campaigns aim at influencing people's mindset with the purpose of advancing a specific agenda. They exploit the anonymity of the Internet, the micro-profiling ability of social networks, and the ease of automatically creating and managing coordinated networks of accounts, to reach millions of social network users with persuasive messages, specifically targeted to topics each individual user is sensitive to, and ultimately influencing the outcome on a targeted issue. In this survey, we review the state of the art on computational propaganda detection from the perspective of Natural Language Processing and Network Analysis, arguing about the need for combined efforts between these communities. We further discuss current challenges and future research directions.
* propaganda detection, disinformation, misinformation, fake news, media bias
Prta: A System to Support the Analysis of Propaganda Techniques in the News
May 12, 2020
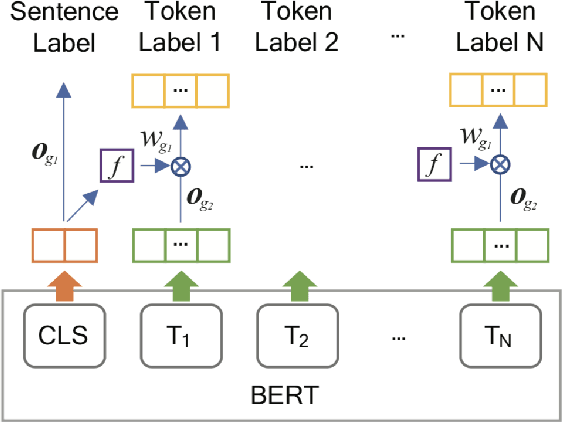
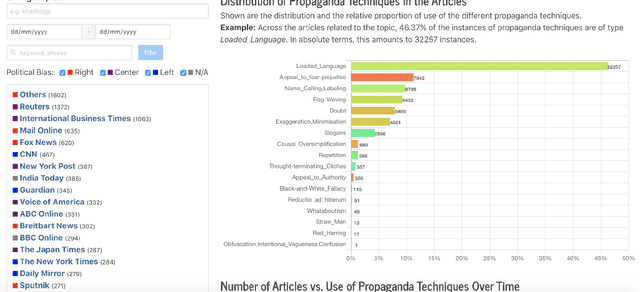
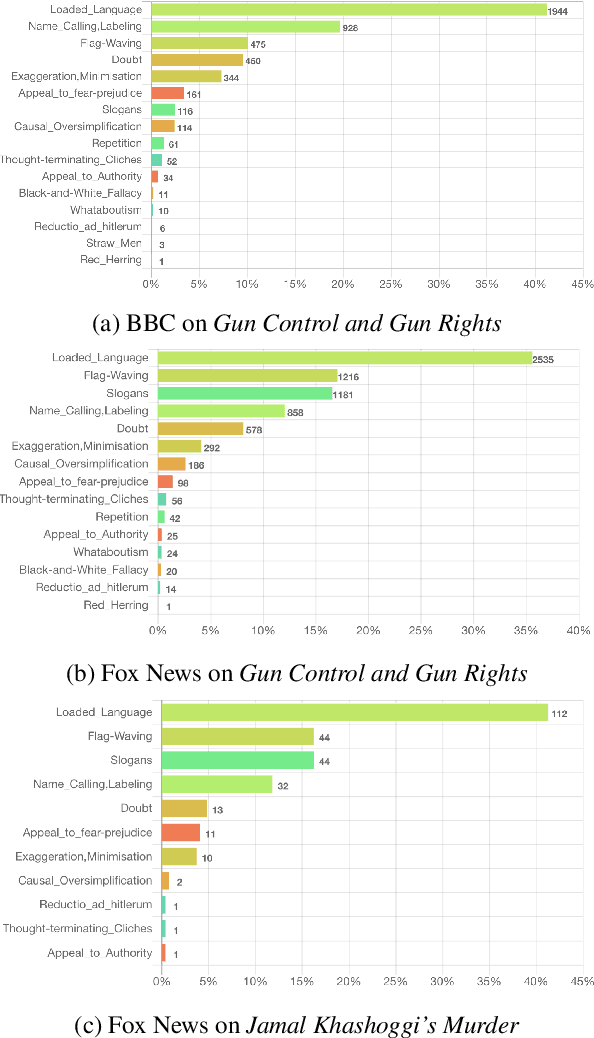
Recent events, such as the 2016 US Presidential Campaign, Brexit and the COVID-19 "infodemic", have brought into the spotlight the dangers of online disinformation. There has been a lot of research focusing on fact-checking and disinformation detection. However, little attention has been paid to the specific rhetorical and psychological techniques used to convey propaganda messages. Revealing the use of such techniques can help promote media literacy and critical thinking, and eventually contribute to limiting the impact of "fake news" and disinformation campaigns. Prta (Propaganda Persuasion Techniques Analyzer) allows users to explore the articles crawled on a regular basis by highlighting the spans in which propaganda techniques occur and to compare them on the basis of their use of propaganda techniques. The system further reports statistics about the use of such techniques, overall and over time, or according to filtering criteria specified by the user based on time interval, keywords, and/or political orientation of the media. Moreover, it allows users to analyze any text or URL through a dedicated interface or via an API. The system is available online: https://www.tanbih.org/prta
* propaganda, disinformation, fake news, media bias, COVID-19
Experiments in Detecting Persuasion Techniques in the News
Nov 15, 2019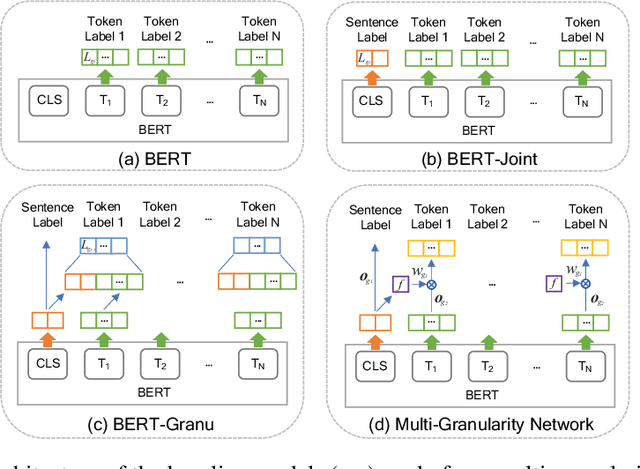
Many recent political events, like the 2016 US Presidential elections or the 2018 Brazilian elections have raised the attention of institutions and of the general public on the role of Internet and social media in influencing the outcome of these events. We argue that a safe democracy is one in which citizens have tools to make them aware of propaganda campaigns. We propose a novel task: performing fine-grained analysis of texts by detecting all fragments that contain propaganda techniques as well as their type. We further design a novel multi-granularity neural network, and we show that it outperforms several strong BERT-based baselines.
* arXiv admin note: substantial text overlap with arXiv:1910.02517
Fine-Grained Analysis of Propaganda in News Articles
Oct 06, 2019
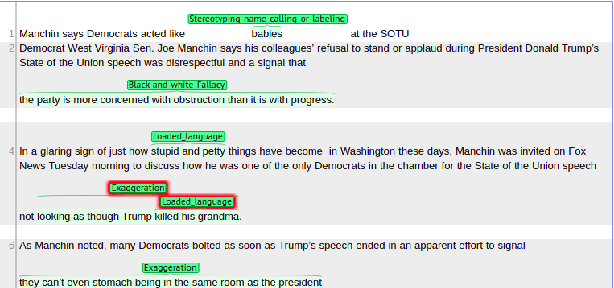
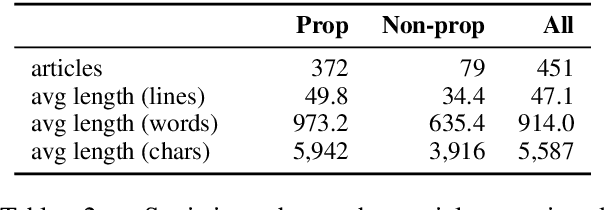
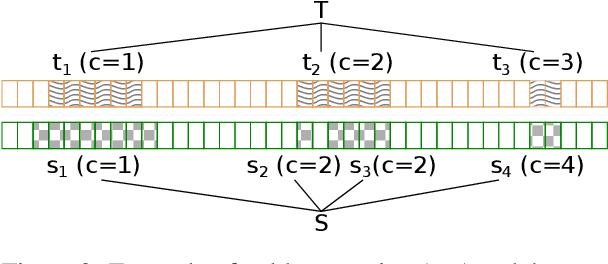
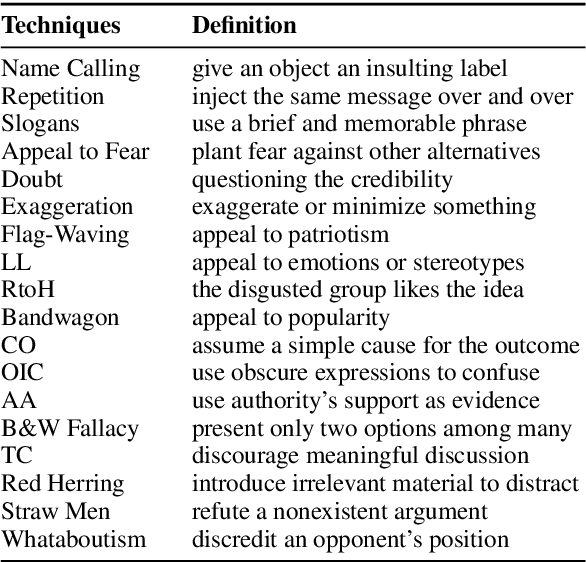
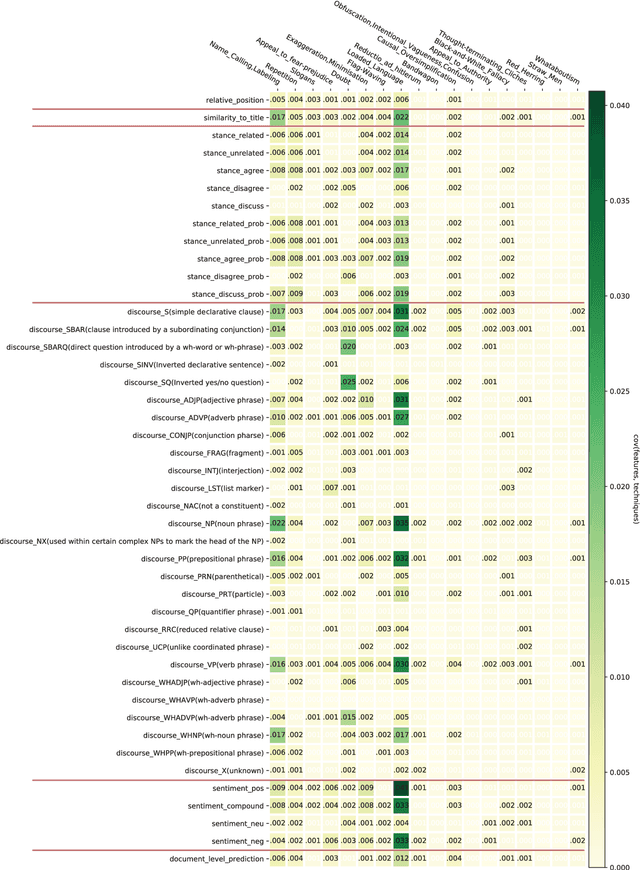
Propaganda aims at influencing people's mindset with the purpose of advancing a specific agenda. Previous work has addressed propaganda detection at the document level, typically labelling all articles from a propagandistic news outlet as propaganda. Such noisy gold labels inevitably affect the quality of any learning system trained on them. A further issue with most existing systems is the lack of explainability. To overcome these limitations, we propose a novel task: performing fine-grained analysis of texts by detecting all fragments that contain propaganda techniques as well as their type. In particular, we create a corpus of news articles manually annotated at the fragment level with eighteen propaganda techniques and we propose a suitable evaluation measure. We further design a novel multi-granularity neural network, and we show that it outperforms several strong BERT-based baselines.
Ensemble-Based Deep Reinforcement Learning for Chatbots
Aug 27, 2019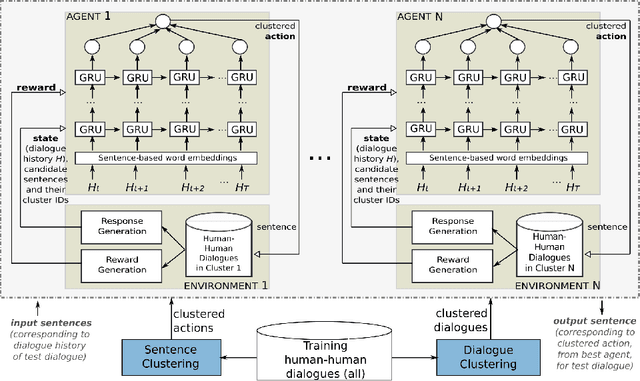



Trainable chatbots that exhibit fluent and human-like conversations remain a big challenge in artificial intelligence. Deep Reinforcement Learning (DRL) is promising for addressing this challenge, but its successful application remains an open question. This article describes a novel ensemble-based approach applied to value-based DRL chatbots, which use finite action sets as a form of meaning representation. In our approach, while dialogue actions are derived from sentence clustering, the training datasets in our ensemble are derived from dialogue clustering. The latter aim to induce specialised agents that learn to interact in a particular style. In order to facilitate neural chatbot training using our proposed approach, we assume dialogue data in raw text only -- without any manually-labelled data. Experimental results using chitchat data reveal that (1) near human-like dialogue policies can be induced, (2) generalisation to unseen data is a difficult problem, and (3) training an ensemble of chatbot agents is essential for improved performance over using a single agent. In addition to evaluations using held-out data, our results are further supported by a human evaluation that rated dialogues in terms of fluency, engagingness and consistency -- which revealed that our proposed dialogue rewards strongly correlate with human judgements.
Factor Graph Attention
Apr 11, 2019
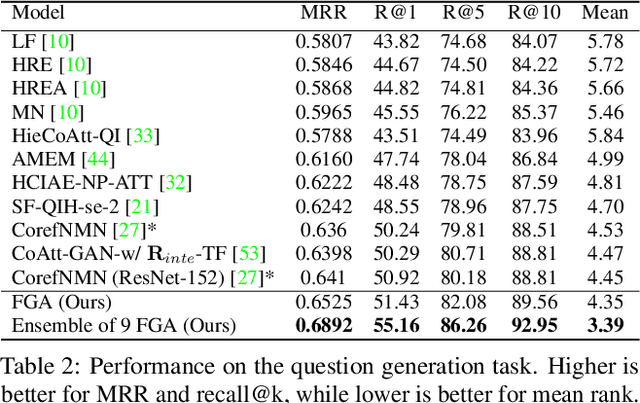
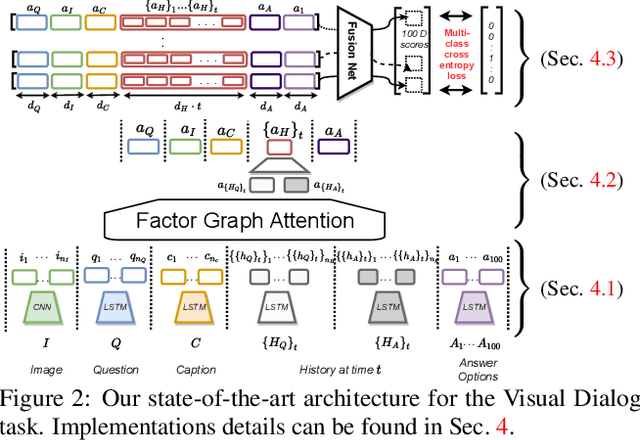
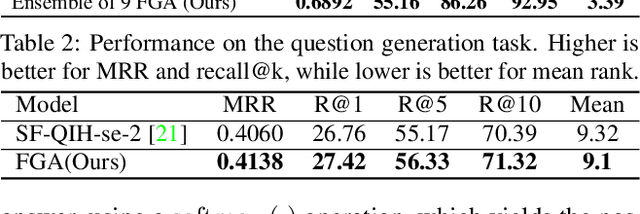
Dialog is an effective way to exchange information, but subtle details and nuances are extremely important. While significant progress has paved a path to address visual dialog with algorithms, details and nuances remain a challenge. Attention mechanisms have demonstrated compelling results to extract details in visual question answering and also provide a convincing framework for visual dialog due to their interpretability and effectiveness. However, the many data utilities that accompany visual dialog challenge existing attention techniques. We address this issue and develop a general attention mechanism for visual dialog which operates on any number of data utilities. To this end, we design a factor graph based attention mechanism which combines any number of utility representations. We illustrate the applicability of the proposed approach on the challenging and recently introduced VisDial datasets, outperforming recent state-of-the-art methods by 1.1% for VisDial0.9 and by 2% for VisDial1.0 on MRR. Our ensemble model improved the MRR score on VisDial1.0 by more than 6%.
Syllable-level Neural Language Model for Agglutinative Language
Aug 18, 2017
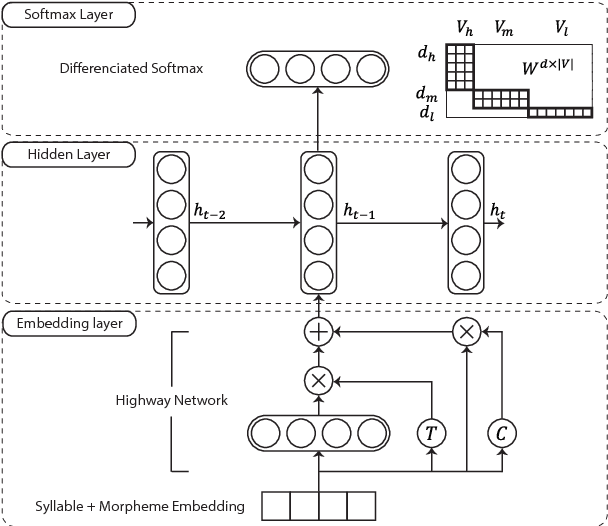
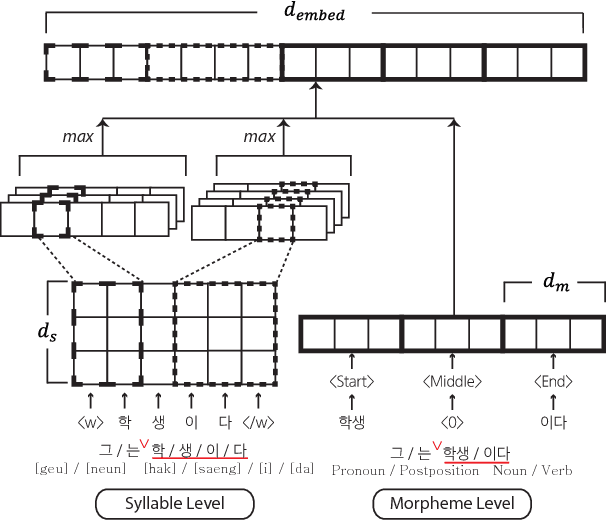
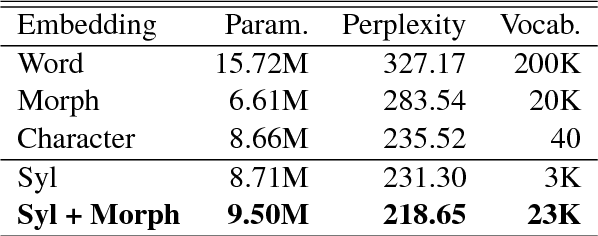
Language models for agglutinative languages have always been hindered in past due to myriad of agglutinations possible to any given word through various affixes. We propose a method to diminish the problem of out-of-vocabulary words by introducing an embedding derived from syllables and morphemes which leverages the agglutinative property. Our model outperforms character-level embedding in perplexity by 16.87 with 9.50M parameters. Proposed method achieves state of the art performance over existing input prediction methods in terms of Key Stroke Saving and has been commercialized.