 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Ceilings to Walls: Universal Dynamic Perching of Small Aerial Robots on Surfaces with Variable Orientations
Dec 27, 2024



This work demonstrates universal dynamic perching capabilities for quadrotors of various sizes and on surfaces with different orientations. By employing a non-dimensionalization framework and deep reinforcement learning, we systematically assessed how robot size and surface orientation affect landing capabilities. We hypothesized that maintaining geometric proportions across different robot scales ensures consistent perching behavior, which was validated in both simulation and experimental tests. Additionally, we investigated the effects of joint stiffness and damping in the landing gear on perching behaviors and performance. While joint stiffness had minimal impact, joint damping ratios influenced landing success under vertical approaching conditions. The study also identified a critical velocity threshold necessary for successful perching, determined by the robot's maneuverability and leg geometry. Overall, this research advances robotic perching capabilities, offering insights into the role of mechanical design and scaling effects, and lays the groundwork for future drone autonomy and operational efficiency in unstructured environments.
ETHIC: Evaluating Large Language Models on Long-Context Tasks with High Information Coverage
Oct 22, 2024



Recent advancements in large language models (LLM) capable of processing extremely long texts highlight the need for a dedicated evaluation benchmark to assess their long-context capabilities. However, existing methods, like the needle-in-a-haystack test, do not effectively assess whether these models fully utilize contextual information, raising concerns about the reliability of current evaluation techniques. To thoroughly examine the effectiveness of existing benchmarks, we introduce a new metric called information coverage (IC), which quantifies the proportion of the input context necessary for answering queries. Our findings indicate that current benchmarks exhibit low IC; although the input context may be extensive, the actual usable context is often limited. To address this, we present ETHIC, a novel benchmark designed to assess LLMs' ability to leverage the entire context. Our benchmark comprises 2,648 test instances spanning four long-context tasks with high IC scores in the domains of books, debates, medicine, and law. Our evaluations reveal significant performance drops in contemporary LLMs, highlighting a critical challenge in managing long contexts. Our benchmark is available at https://github.com/dmis-lab/ETHIC.
ChroKnowledge: Unveiling Chronological Knowledge of Language Models in Multiple Domains
Oct 13, 2024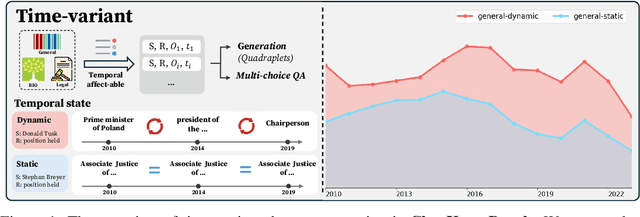


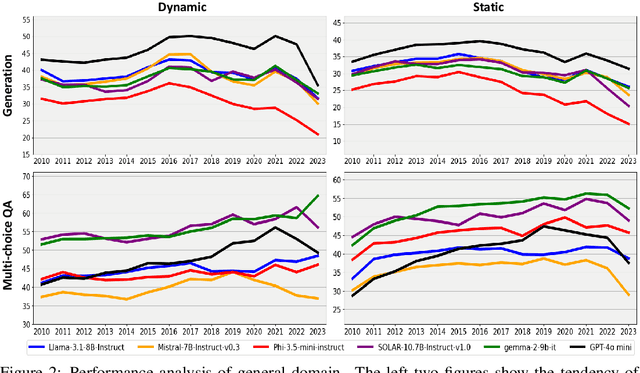
Large language models (LLMs) have significantly impacted many aspects of our lives. However, assessing and ensuring their chronological knowledge remains challenging. Existing approaches fall short in addressing the accumulative nature of knowledge, often relying on a single time stamp. To overcome this, we introduce ChroKnowBench, a benchmark dataset designed to evaluate chronologically accumulated knowledge across three key aspects: multiple domains, time dependency, temporal state. Our benchmark distinguishes between knowledge that evolves (e.g., scientific discoveries, amended laws) and knowledge that remain constant (e.g., mathematical truths, commonsense facts). Building on this benchmark, we present ChroKnowledge (Chronological Categorization of Knowledge), a novel sampling-based framework for evaluating and updating LLMs' non-parametric chronological knowledge. Our evaluation shows: (1) The ability of eliciting temporal knowledge varies depending on the data format that model was trained on. (2) LLMs partially recall knowledge or show a cut-off at temporal boundaries rather than recalling all aspects of knowledge correctly. Thus, we apply our ChroKnowPrompt, an in-depth prompting to elicit chronological knowledge by traversing step-by-step through the surrounding time spans. We observe that our framework successfully updates the overall knowledge across the entire timeline in both the biomedical domain (+11.9%) and the general domain (+2.8%), demonstrating its effectiveness in refining temporal knowledge. This non-parametric approach also enables knowledge updates not only in open-source models but also in proprietary LLMs, ensuring comprehensive applicability across model types. We perform a comprehensive analysis based on temporal characteristics of ChroKnowPrompt and validate the potential of various models to elicit intrinsic temporal knowledge through our method.
Interpretable pap smear cell representation for cervical cancer screening
Nov 17, 2023Screening is critical for prevention and early detection of cervical cancer but it is time-consuming and laborious. Supervised deep convolutional neural networks have been developed to automate pap smear screening and the results are promising. However, the interest in using only normal samples to train deep neural networks has increased owing to class imbalance problems and high-labeling costs that are both prevalent in healthcare. In this study, we introduce a method to learn explainable deep cervical cell representations for pap smear cytology images based on one class classification using variational autoencoders. Findings demonstrate that a score can be calculated for cell abnormality without training models with abnormal samples and localize abnormality to interpret our results with a novel metric based on absolute difference in cross entropy in agglomerative clustering. The best model that discriminates squamous cell carcinoma (SCC) from normals gives 0.908 +- 0.003 area under operating characteristic curve (AUC) and one that discriminates high-grade epithelial lesion (HSIL) 0.920 +- 0.002 AUC. Compared to other clustering methods, our method enhances the V-measure and yields higher homogeneity scores, which more effectively isolate different abnormality regions, aiding in the interpretation of our results. Evaluation using in-house and additional open dataset show that our model can discriminate abnormality without the need of additional training of deep models.
Ensemble-Based Deep Reinforcement Learning for Chatbots
Aug 27, 2019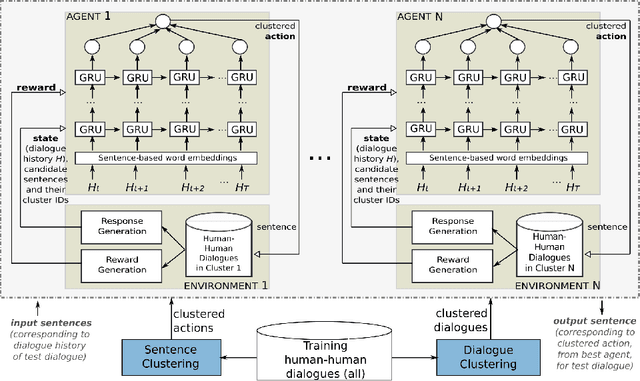



Trainable chatbots that exhibit fluent and human-like conversations remain a big challenge in artificial intelligence. Deep Reinforcement Learning (DRL) is promising for addressing this challenge, but its successful application remains an open question. This article describes a novel ensemble-based approach applied to value-based DRL chatbots, which use finite action sets as a form of meaning representation. In our approach, while dialogue actions are derived from sentence clustering, the training datasets in our ensemble are derived from dialogue clustering. The latter aim to induce specialised agents that learn to interact in a particular style. In order to facilitate neural chatbot training using our proposed approach, we assume dialogue data in raw text only -- without any manually-labelled data. Experimental results using chitchat data reveal that (1) near human-like dialogue policies can be induced, (2) generalisation to unseen data is a difficult problem, and (3) training an ensemble of chatbot agents is essential for improved performance over using a single agent. In addition to evaluations using held-out data, our results are further supported by a human evaluation that rated dialogues in terms of fluency, engagingness and consistency -- which revealed that our proposed dialogue rewards strongly correlate with human judgements.
Deep Reinforcement Learning for Chatbots Using Clustered Actions and Human-Likeness Rewards
Aug 27, 2019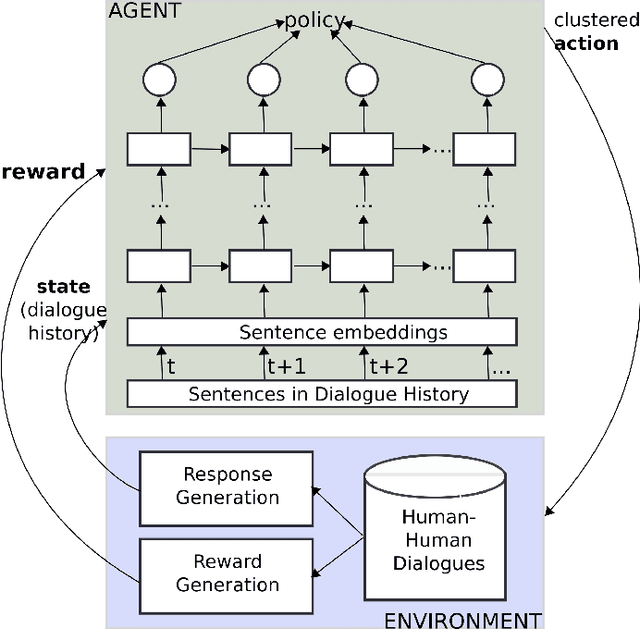
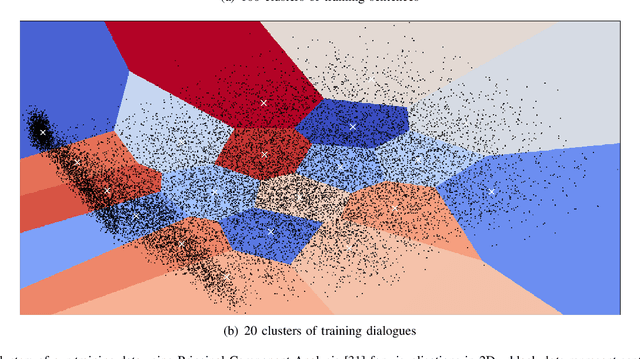
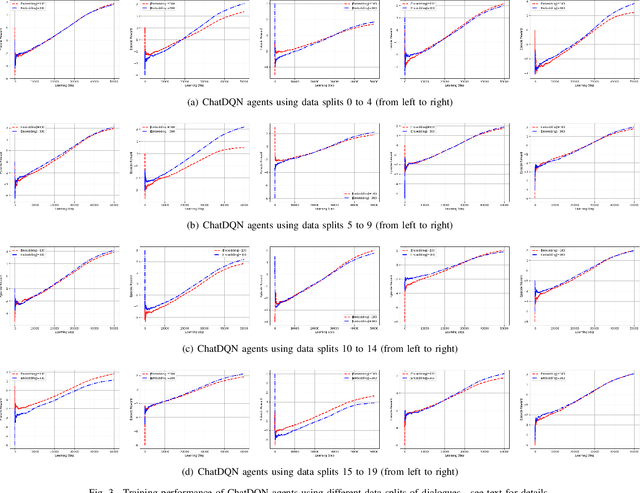
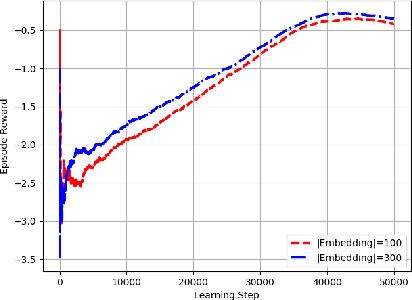
Training chatbots using the reinforcement learning paradigm is challenging due to high-dimensional states, infinite action spaces and the difficulty in specifying the reward function. We address such problems using clustered actions instead of infinite actions, and a simple but promising reward function based on human-likeness scores derived from human-human dialogue data. We train Deep Reinforcement Learning (DRL) agents using chitchat data in raw text---without any manual annotations. Experimental results using different splits of training data report the following. First, that our agents learn reasonable policies in the environments they get familiarised with, but their performance drops substantially when they are exposed to a test set of unseen dialogues. Second, that the choice of sentence embedding size between 100 and 300 dimensions is not significantly different on test data. Third, that our proposed human-likeness rewards are reasonable for training chatbots as long as they use lengthy dialogue histories of >=10 sentences.
A Study on Dialogue Reward Prediction for Open-Ended Conversational Agents
Dec 02, 2018
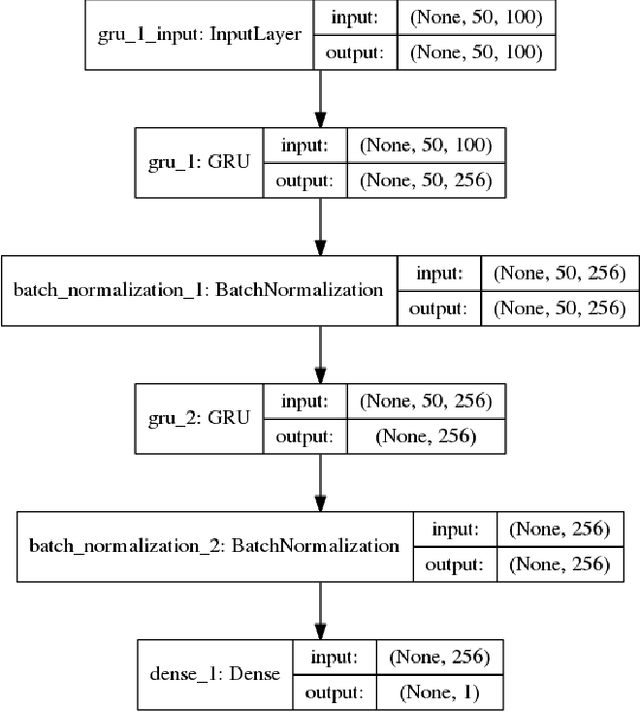

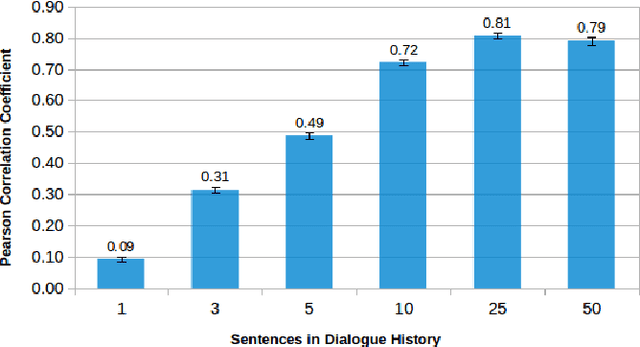
The amount of dialogue history to include in a conversational agent is often underestimated and/or set in an empirical and thus possibly naive way. This suggests that principled investigations into optimal context windows are urgently needed given that the amount of dialogue history and corresponding representations can play an important role in the overall performance of a conversational system. This paper studies the amount of history required by conversational agents for reliably predicting dialogue rewards. The task of dialogue reward prediction is chosen for investigating the effects of varying amounts of dialogue history and their impact on system performance. Experimental results using a dataset of 18K human-human dialogues report that lengthy dialogue histories of at least 10 sentences are preferred (25 sentences being the best in our experiments) over short ones, and that lengthy histories are useful for training dialogue reward predictors with strong positive correlations between target dialogue rewards and predicted ones.