 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Dialogue Reward Prediction for Open-Ended Conversational Agents
Paper and Code
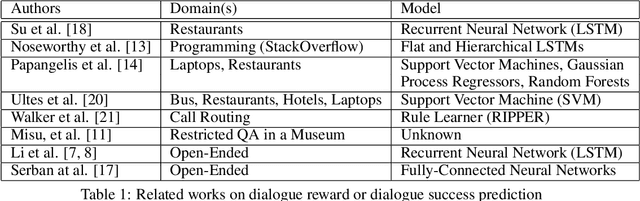
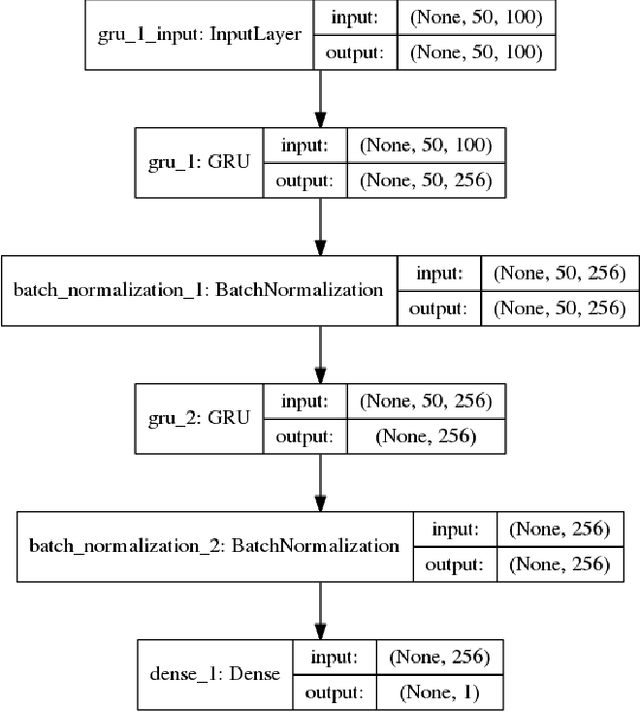

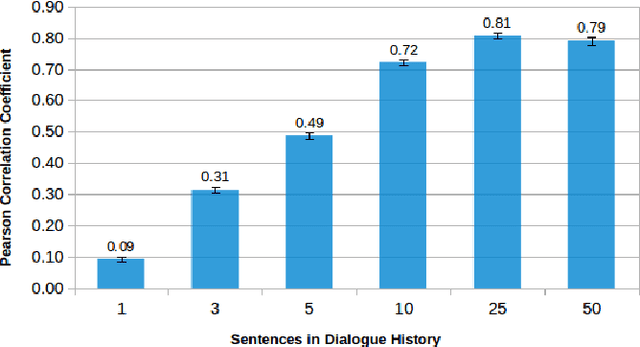
The amount of dialogue history to include in a conversational agent is often underestimated and/or set in an empirical and thus possibly naive way. This suggests that principled investigations into optimal context windows are urgently needed given that the amount of dialogue history and corresponding representations can play an important role in the overall performance of a conversational system. This paper studies the amount of history required by conversational agents for reliably predicting dialogue rewards. The task of dialogue reward prediction is chosen for investigating the effects of varying amounts of dialogue history and their impact on system performance. Experimental results using a dataset of 18K human-human dialogues report that lengthy dialogue histories of at least 10 sentences are preferred (25 sentences being the best in our experiments) over short ones, and that lengthy histories are useful for training dialogue reward predictors with strong positive correlations between target dialogue rewards and predicted ones.