 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparks of Large Audio Models: A Survey and Outlook
Sep 03, 2023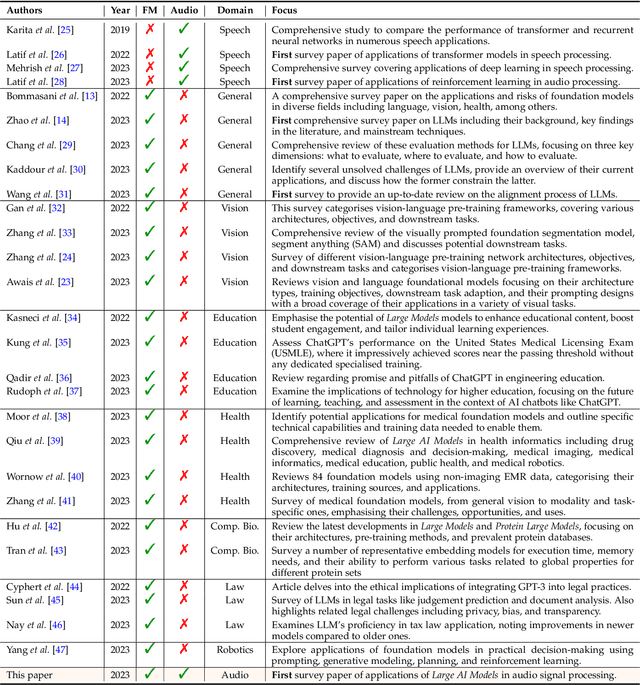
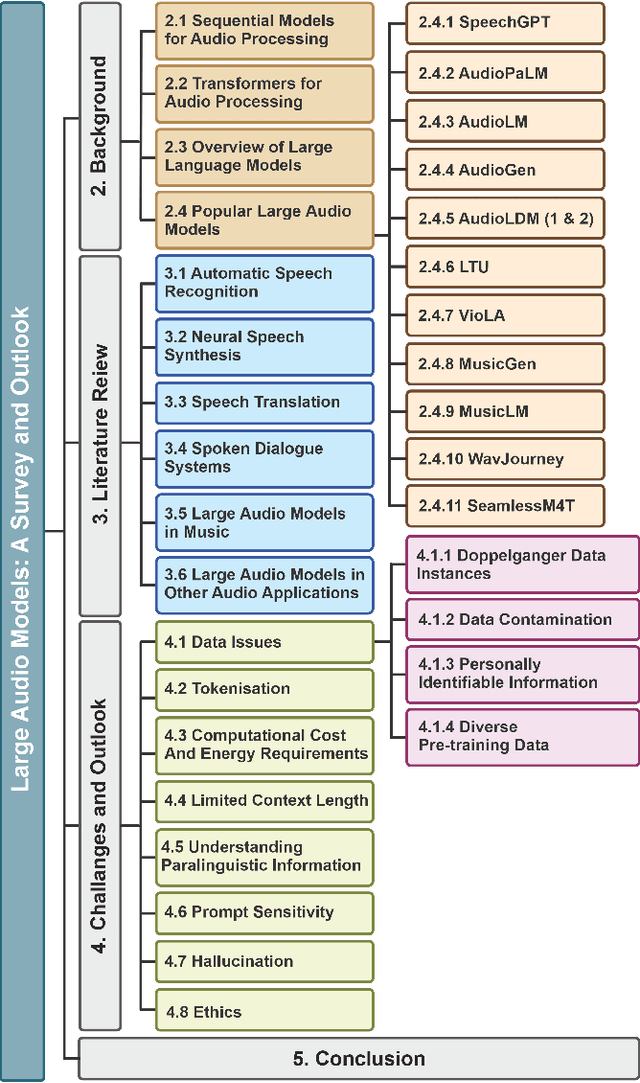
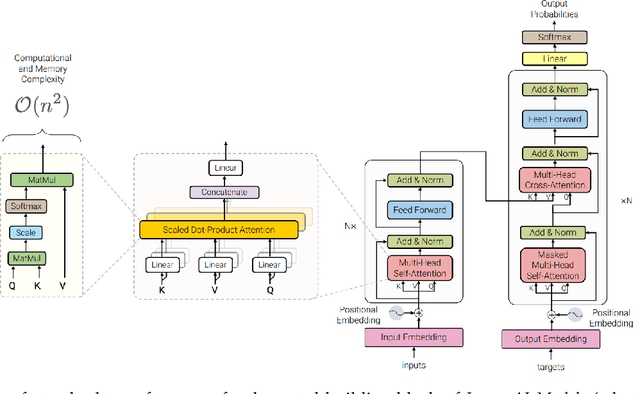
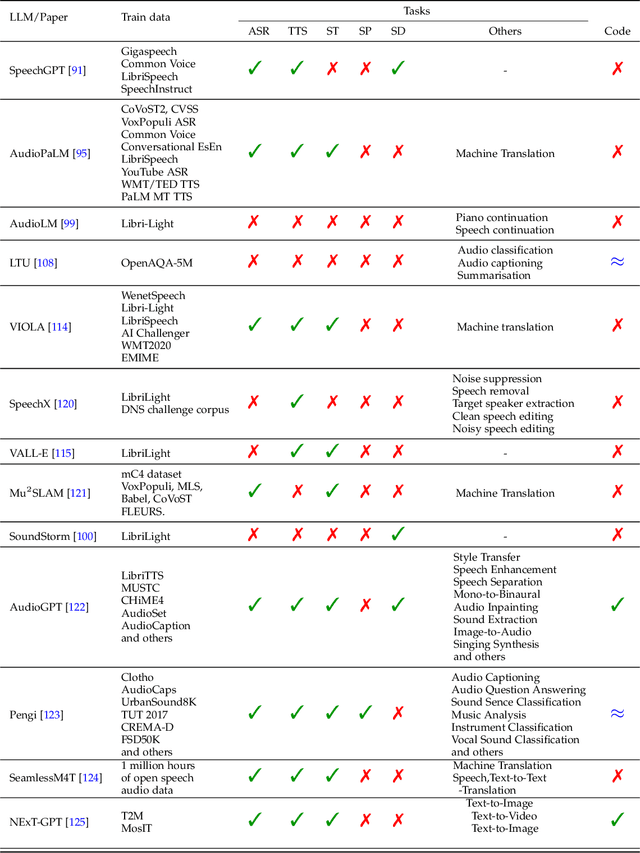
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources--from human voices to musical instruments and environmental sounds--poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at https://github.com/EmulationAI/awesome-large-audio-models.
Reward-Based Environment States for Robot Manipulation Policy Learning
Dec 10, 2021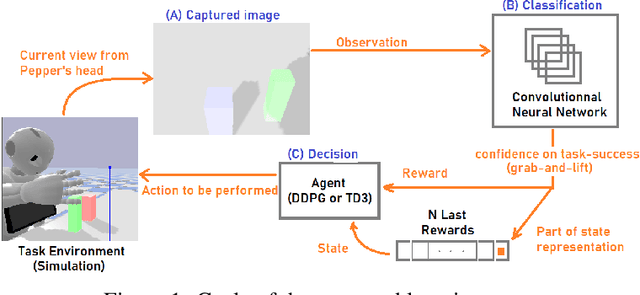
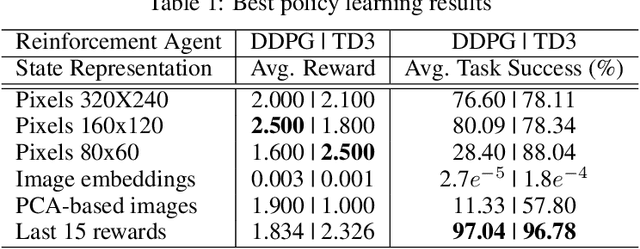
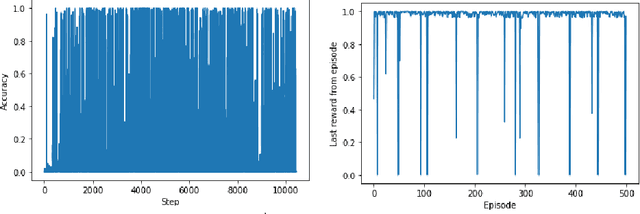

Training robot manipulation policies is a challenging and open problem in robotics and artificial intelligence. In this paper we propose a novel and compact state representation based on the rewards predicted from an image-based task success classifier. Our experiments, using the Pepper robot in simulation with two deep reinforcement learning algorithms on a grab-and-lift task, reveal that our proposed state representation can achieve up to 97% task success using our best policies.
Neural Task Success Classifiers for Robotic Manipulation from Few Real Demonstrations
Jul 01, 2021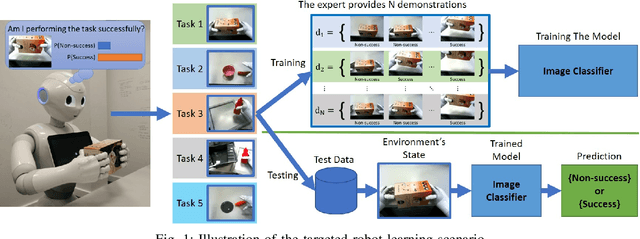
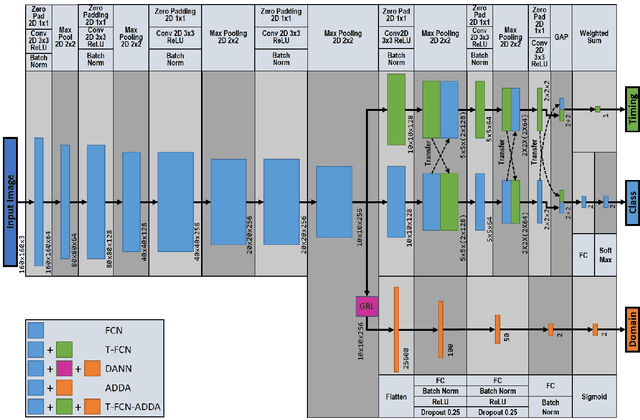
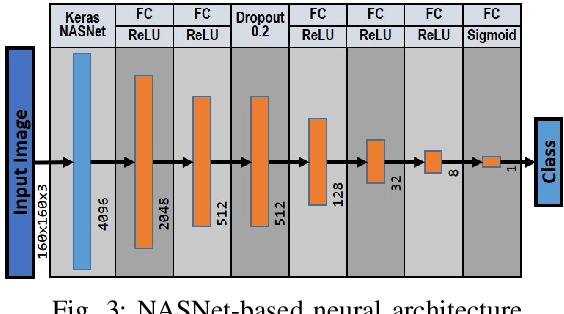
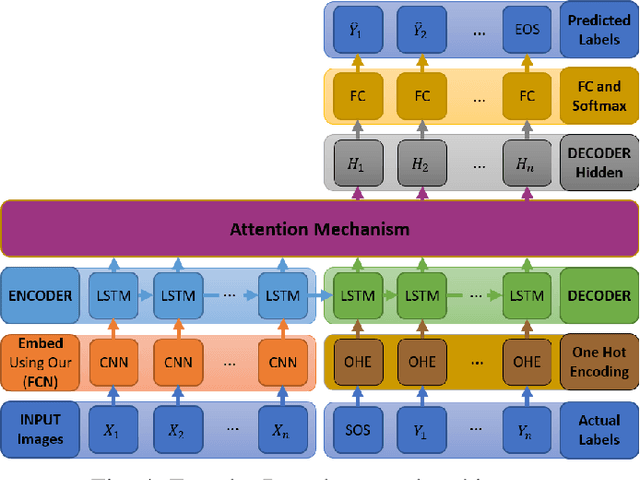
Robots learning a new manipulation task from a small amount of demonstrations are increasingly demanded in different workspaces. A classifier model assessing the quality of actions can predict the successful completion of a task, which can be used by intelligent agents for action-selection. This paper presents a novel classifier that learns to classify task completion only from a few demonstrations. We carry out a comprehensive comparison of different neural classifiers, e.g. fully connected-based, fully convolutional-based, sequence2sequence-based, and domain adaptation-based classification. We also present a new dataset including five robot manipulation tasks, which is publicly available. We compared the performances of our novel classifier and the existing models using our dataset and the MIME dataset. The results suggest domain adaptation and timing-based features improve success prediction. Our novel model, i.e. fully convolutional neural network with domain adaptation and timing features, achieves an average classification accuracy of 97.3\% and 95.5\% across tasks in both datasets whereas state-of-the-art classifiers without domain adaptation and timing-features only achieve 82.4\% and 90.3\%, respectively.
A Survey on Deep Reinforcement Learning for Audio-Based Applications
Jan 01, 2021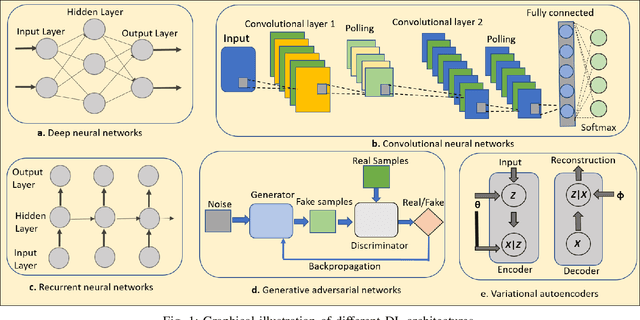
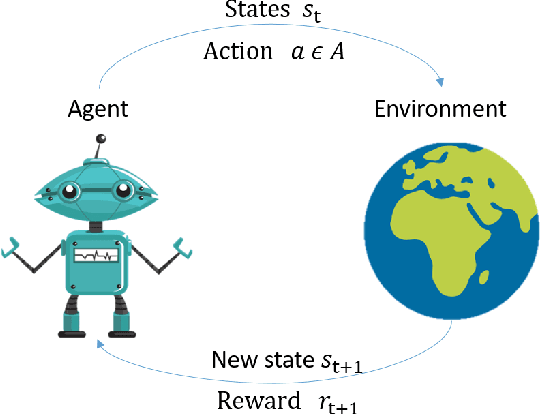
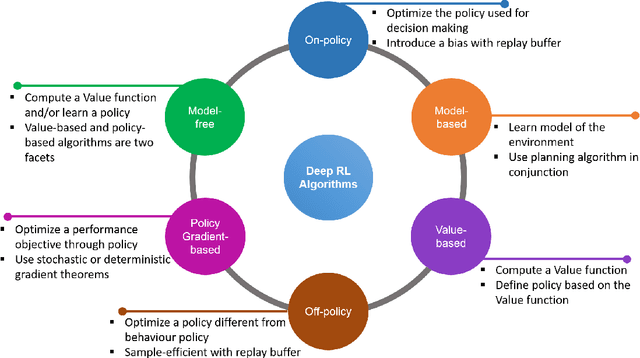
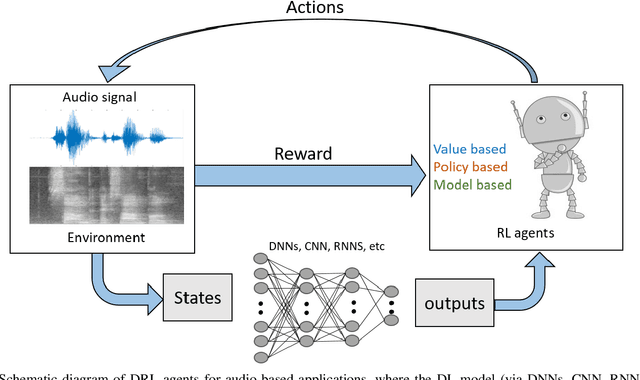
Deep reinforcement learning (DRL) is poised to revolutionise the field of artificial intelligence (AI) by endowing autonomous systems with high levels of understanding of the real world. Currently, deep learning (DL) is enabling DRL to effectively solve various intractable problems in various fields. Most importantly, DRL algorithms are also being employed in audio signal processing to learn directly from speech, music and other sound signals in order to create audio-based autonomous systems that have many promising application in the real world. In this article, we conduct a comprehensive survey on the progress of DRL in the audio domain by bringing together the research studies across different speech and music-related areas. We begin with an introduction to the general field of DL and reinforcement learning (RL), then progress to the main DRL methods and their applications in the audio domain. We conclude by presenting challenges faced by audio-based DRL agents and highlighting open areas for future research and investigation.
Ensemble-Based Deep Reinforcement Learning for Chatbots
Aug 27, 2019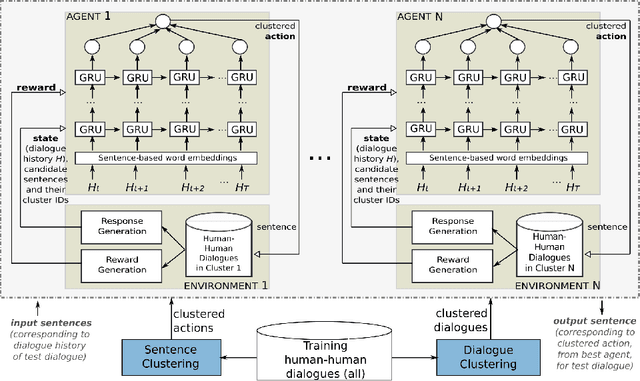



Trainable chatbots that exhibit fluent and human-like conversations remain a big challenge in artificial intelligence. Deep Reinforcement Learning (DRL) is promising for addressing this challenge, but its successful application remains an open question. This article describes a novel ensemble-based approach applied to value-based DRL chatbots, which use finite action sets as a form of meaning representation. In our approach, while dialogue actions are derived from sentence clustering, the training datasets in our ensemble are derived from dialogue clustering. The latter aim to induce specialised agents that learn to interact in a particular style. In order to facilitate neural chatbot training using our proposed approach, we assume dialogue data in raw text only -- without any manually-labelled data. Experimental results using chitchat data reveal that (1) near human-like dialogue policies can be induced, (2) generalisation to unseen data is a difficult problem, and (3) training an ensemble of chatbot agents is essential for improved performance over using a single agent. In addition to evaluations using held-out data, our results are further supported by a human evaluation that rated dialogues in terms of fluency, engagingness and consistency -- which revealed that our proposed dialogue rewards strongly correlate with human judgements.
A Data-Efficient Deep Learning Approach for Deployable Multimodal Social Robots
Aug 27, 2019

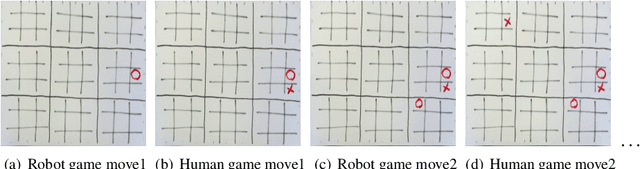

The deep supervised and reinforcement learning paradigms (among others) have the potential to endow interactive multimodal social robots with the ability of acquiring skills autonomously. But it is still not very clear yet how they can be best deployed in real world applications. As a step in this direction, we propose a deep learning-based approach for efficiently training a humanoid robot to play multimodal games---and use the game of `Noughts & Crosses' with two variants as a case study. Its minimum requirements for learning to perceive and interact are based on a few hundred example images, a few example multimodal dialogues and physical demonstrations of robot manipulation, and automatic simulations. In addition, we propose novel algorithms for robust visual game tracking and for competitive policy learning with high winning rates, which substantially outperform DQN-based baselines. While an automatic evaluation shows evidence that the proposed approach can be easily extended to new games with competitive robot behaviours, a human evaluation with 130 humans playing with the Pepper robot confirms that highly accurate visual perception is required for successful game play.
Deep Reinforcement Learning for Chatbots Using Clustered Actions and Human-Likeness Rewards
Aug 27, 2019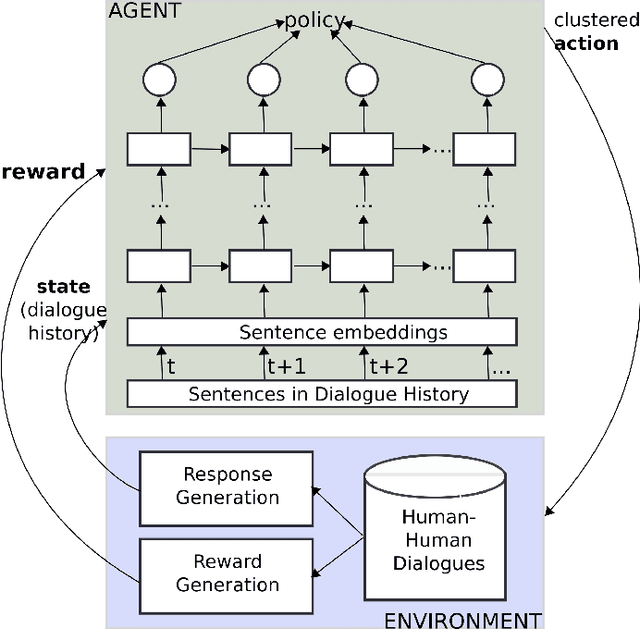
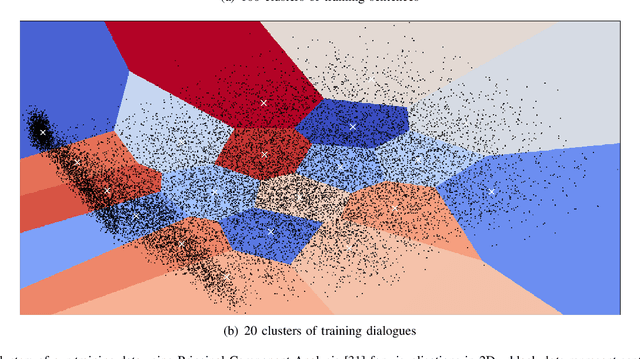
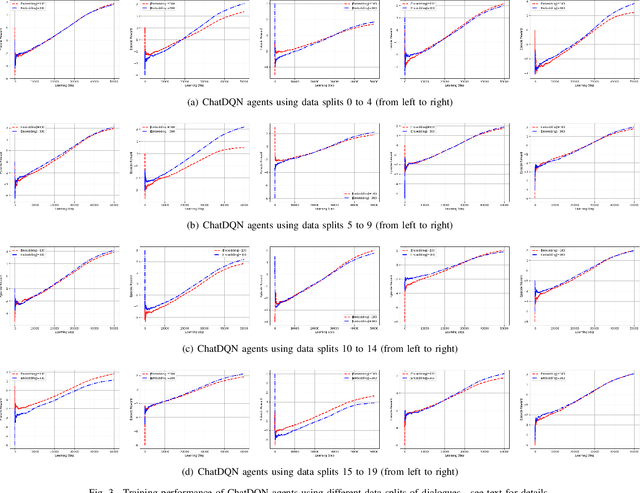
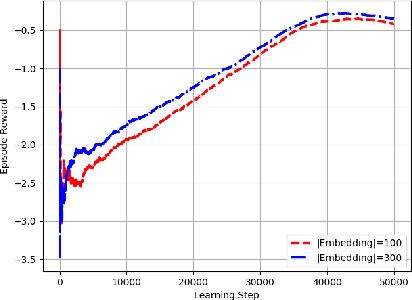
Training chatbots using the reinforcement learning paradigm is challenging due to high-dimensional states, infinite action spaces and the difficulty in specifying the reward function. We address such problems using clustered actions instead of infinite actions, and a simple but promising reward function based on human-likeness scores derived from human-human dialogue data. We train Deep Reinforcement Learning (DRL) agents using chitchat data in raw text---without any manual annotations. Experimental results using different splits of training data report the following. First, that our agents learn reasonable policies in the environments they get familiarised with, but their performance drops substantially when they are exposed to a test set of unseen dialogues. Second, that the choice of sentence embedding size between 100 and 300 dimensions is not significantly different on test data. Third, that our proposed human-likeness rewards are reasonable for training chatbots as long as they use lengthy dialogue histories of >=10 sentences.
A Study on Dialogue Reward Prediction for Open-Ended Conversational Agents
Dec 02, 2018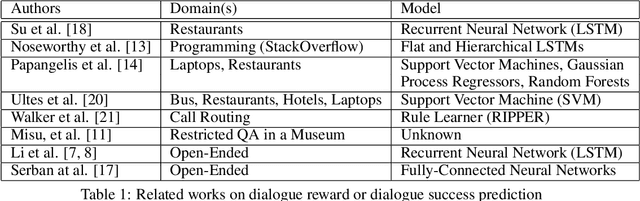
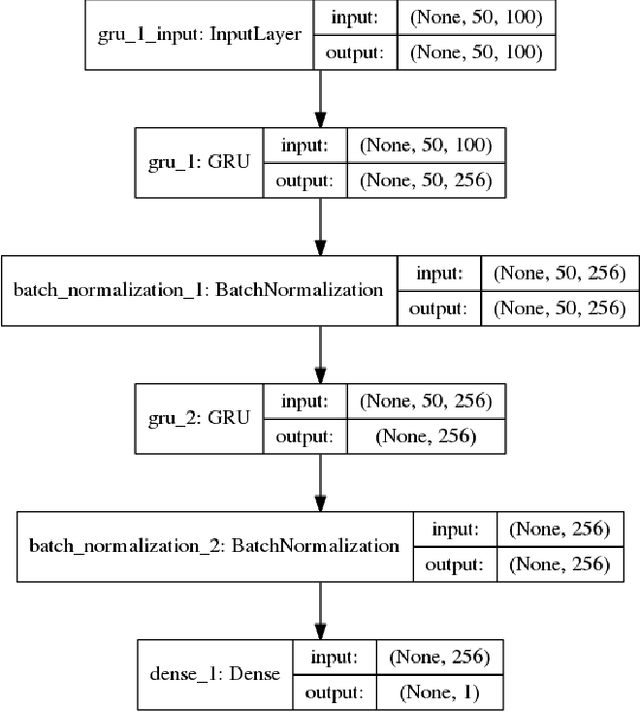

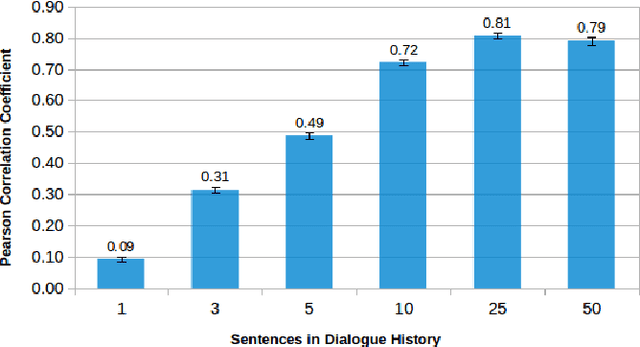
The amount of dialogue history to include in a conversational agent is often underestimated and/or set in an empirical and thus possibly naive way. This suggests that principled investigations into optimal context windows are urgently needed given that the amount of dialogue history and corresponding representations can play an important role in the overall performance of a conversational system. This paper studies the amount of history required by conversational agents for reliably predicting dialogue rewards. The task of dialogue reward prediction is chosen for investigating the effects of varying amounts of dialogue history and their impact on system performance. Experimental results using a dataset of 18K human-human dialogues report that lengthy dialogue histories of at least 10 sentences are preferred (25 sentences being the best in our experiments) over short ones, and that lengthy histories are useful for training dialogue reward predictors with strong positive correlations between target dialogue rewards and predicted ones.
Deep Reinforcement Learning for Multi-Domain Dialogue Systems
Nov 26, 2016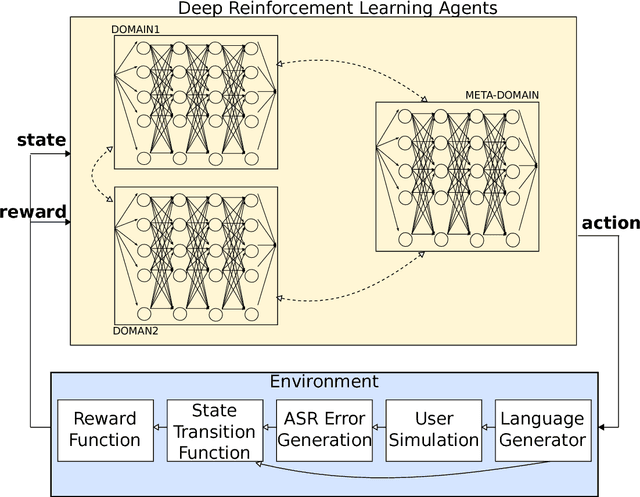

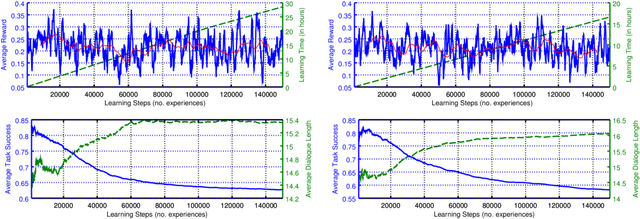
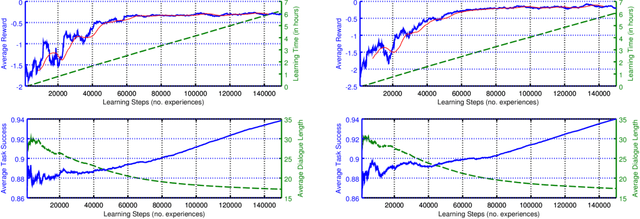
Standard deep reinforcement learning methods such as Deep Q-Networks (DQN) for multiple tasks (domains) face scalability problems. We propose a method for multi-domain dialogue policy learning---termed NDQN, and apply it to an information-seeking spoken dialogue system in the domains of restaurants and hotels. Experimental results comparing DQN (baseline) versus NDQN (proposed) using simulations report that our proposed method exhibits better scalability and is promising for optimising the behaviour of multi-domain dialogue systems.
Training an Interactive Humanoid Robot Using Multimodal Deep Reinforcement Learning
Nov 26, 2016



Training robots to perceive, act and communicate using multiple modalities still represents a challenging problem, particularly if robots are expected to learn efficiently from small sets of example interactions. We describe a learning approach as a step in this direction, where we teach a humanoid robot how to play the game of noughts and crosses. Given that multiple multimodal skills can be trained to play this game, we focus our attention to training the robot to perceive the game, and to interact in this game. Our multimodal deep reinforcement learning agent perceives multimodal features and exhibits verbal and non-verbal actions while playing. Experimental results using simulations show that the robot can learn to win or draw up to 98% of the games. A pilot test of the proposed multimodal system for the targeted game---integrating speech, vision and gestures---reports that reasonable and fluent interactions can be achieved using the proposed approach.